
What is Relace?
构建强大的 AI 编码系统,特别是那些为复杂任务或大型代码库设计的系统,常常会遇到意想不到的瓶颈。随着用户不断探索其边界,您会面临诸如高效管理海量代码上下文,或使用更敏捷的方法取代缓慢且昂贵的完整文件重写等挑战。如果每一步都仅仅依赖强大的通用前沿模型,包括检索和代码合并等辅助功能,可能会迅速增加成本并引入令人沮丧的延迟,特别是对于期望快速改进的非技术用户而言。
Relace 提供了高度专业化的 AI 模型,专门用于解决 AI 编码工作流程中的这些关键辅助任务。通过专注于这些特定功能,与使用更大、更昂贵的模型相比,Relace 模型在速度和成本效率方面都实现了显著提升,同时保持或提高了准确性。集成 Relace 可增强您的 AI 代码生成产品的性能和可靠性。
主要特点:
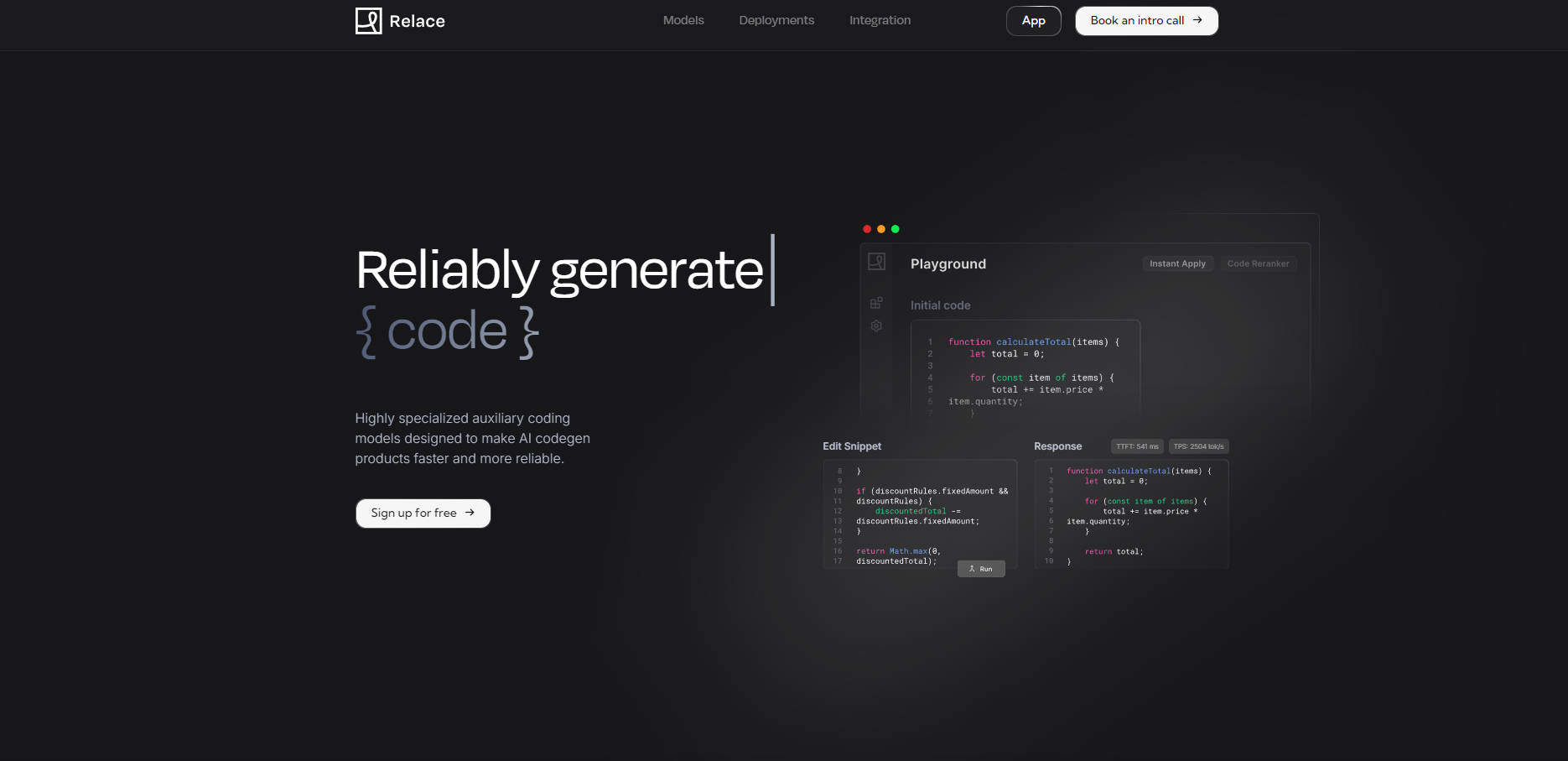
⚡️ 加速代码合并: Instant Apply 模型以每秒超过 2,500 个 token 的速度合并语义代码片段,平均端到端延迟约为 900 毫秒。它取代了缓慢的完整文件重写,可以直接在您的产品中快速、精确地进行代码修改。
🔍 高效的上下文管理: Embeddings 和 Code Reranker 模型可以在大约 1-2 秒内快速确定百万行代码库中的相关性。通过有效过滤不相关的文件,可以显著减少输入 token 的使用量(超过 50%)并清理上下文窗口,从而提高后续 AI 生成的质量。
📈 降低运营成本: 通过使用专门的、成本优化的模型来处理资源密集型的辅助任务,而不是使用昂贵的前沿模型,Relace 有助于大幅降低每次用户操作的 API 费用。
🎯 实现最先进的准确性: Relace 模型经过广泛数据集的训练,涵盖了跨多种语言的数十万个代码合并和查询-代码对,为其特定功能提供领先的准确性。
使用场景:
扩展到大型代码库: 集成 Embeddings 和 Reranker,使您的 AI 代理能够可靠地导航和检索大型、数百万行代码存储库中的相关上下文,而不会超出上下文窗口限制或产生过高的成本。
实现快速代码改进: 利用 Instant Apply 模型,允许用户快速应用由您的 AI 代理生成的小型、有针对性的代码编辑。这避免了重新生成整个文件的延迟和成本,使编码体验对于迭代更改而言感觉更灵敏、响应更快。
优化 Agentic 工作流程成本: 在您的代理循环中部署 Relace 模型以进行检索和合并步骤。这从昂贵的前沿模型中卸载了这些频繁、高容量的任务,从而在保持或提高整体代理执行速度和可靠性的同时,显著节省成本。
结论:
Relace 为 AI 代码生成中的常见瓶颈提供了一个专注、高性能的解决方案。通过为上下文检索和代码合并提供专门构建的模型,Relace 使您能够构建更快、更经济高效且更可靠的 AI 编码产品。集成我们经过验证的模型,以增强您产品的能力,并为您的用户提供卓越的体验。
More information on Relace
Launched
2024-10
Pricing Model
Free Trial
Starting Price
Global Rank
14065166
Follow
Month Visit
<5k
Tech used
Webflow,Amazon AWS CloudFront,cdnjs,Cloudflare CDN,JSDelivr,unpkg,jQuery,Gzip,HTTP/3,OpenGraph,HSTS
Top 5 Countries
74.41%
25.59%
United States
India
Traffic Sources
9.65%
1.03%
0.05%
3.95%
17.86%
67.45%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
Relace was manually vetted by our editorial team and was first featured on 2025-05-16.
Related Searches
Relace 替代方案
更多 替代方案-

-

-

-

-
部署能够规划、构建和审查的代码智能体。这些智能体具备全面的上下文理解能力、强大的集成功能,并能交付生产就绪的成果。更有企业级支持作为坚实后盾。借助 Codegen,助您加速交付。