
What is Modular?
혁신적인 AI 소프트웨어 스택인 모듈러 가속화 실행(MAX) 플랫폼은 AI 엔지니어에게 뛰어난 성능, 프로그래밍 가능성, 이식성을 제공하도록 설계되었습니다. Modular Inc.에서 개발한 MAX는 AI 인프라에 대한 획기적인 접근 방식을 나타내며, 저지연, 고처리량, 실시간 AI 추론 파이프라인 배포를 간소화하는 종합적인 도구와 라이브러리 세트를 제공합니다.
주요 기능:
-
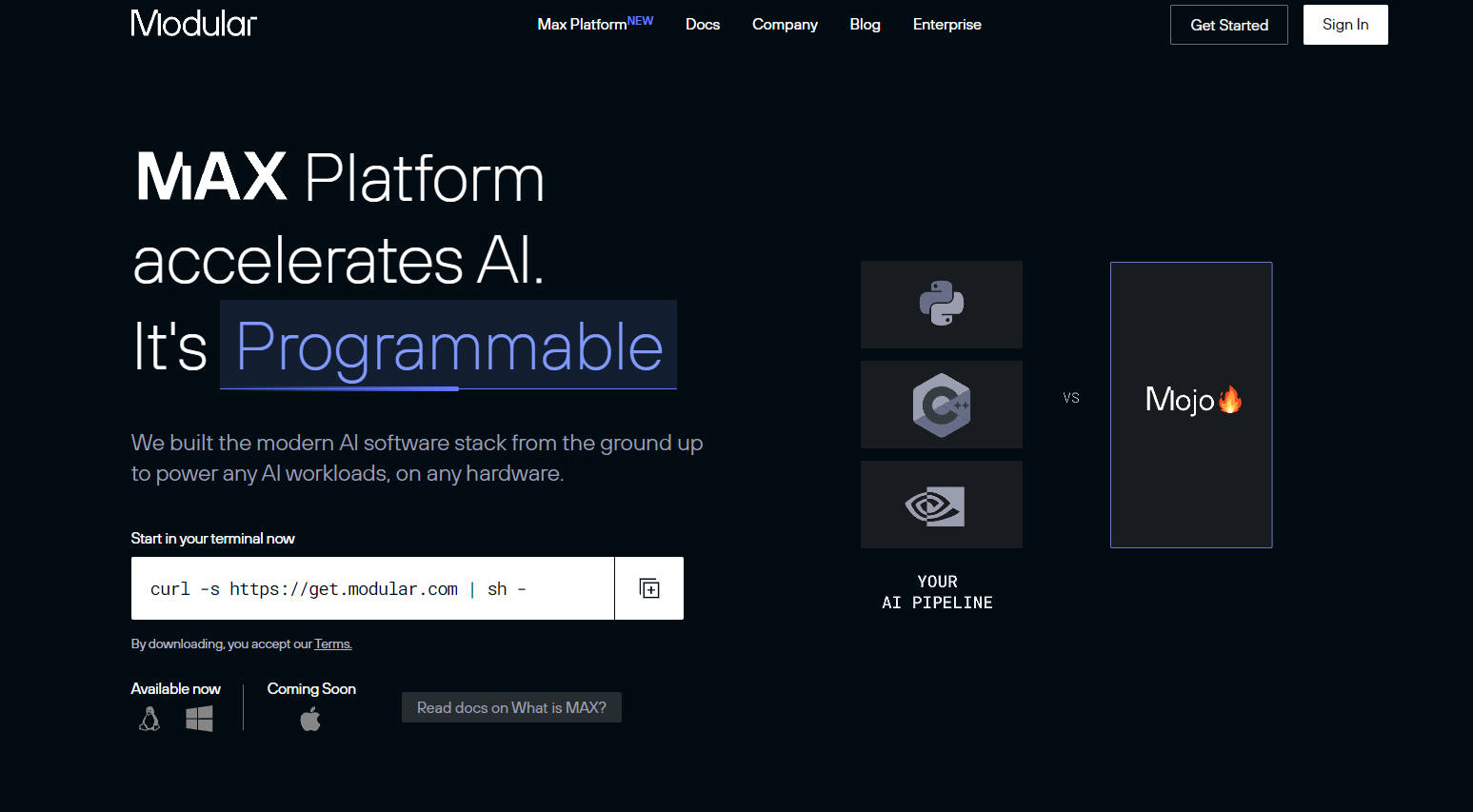
Mojo를 통한 완전한 프로그래밍 가능성: MAX는 Python의 용이성, Rust의 안전성, C의 성능을 결합한 프로그래밍 언어인 Mojo를 기반으로 구축되었습니다. 이러한 고유한 조합은 AI 하드웨어의 모든 잠재력을 해제하여 AI 엔지니어가 전례 없는 편의성과 효율성으로 AI 모델을 확장하고 최적화할 수 있도록 합니다.
-
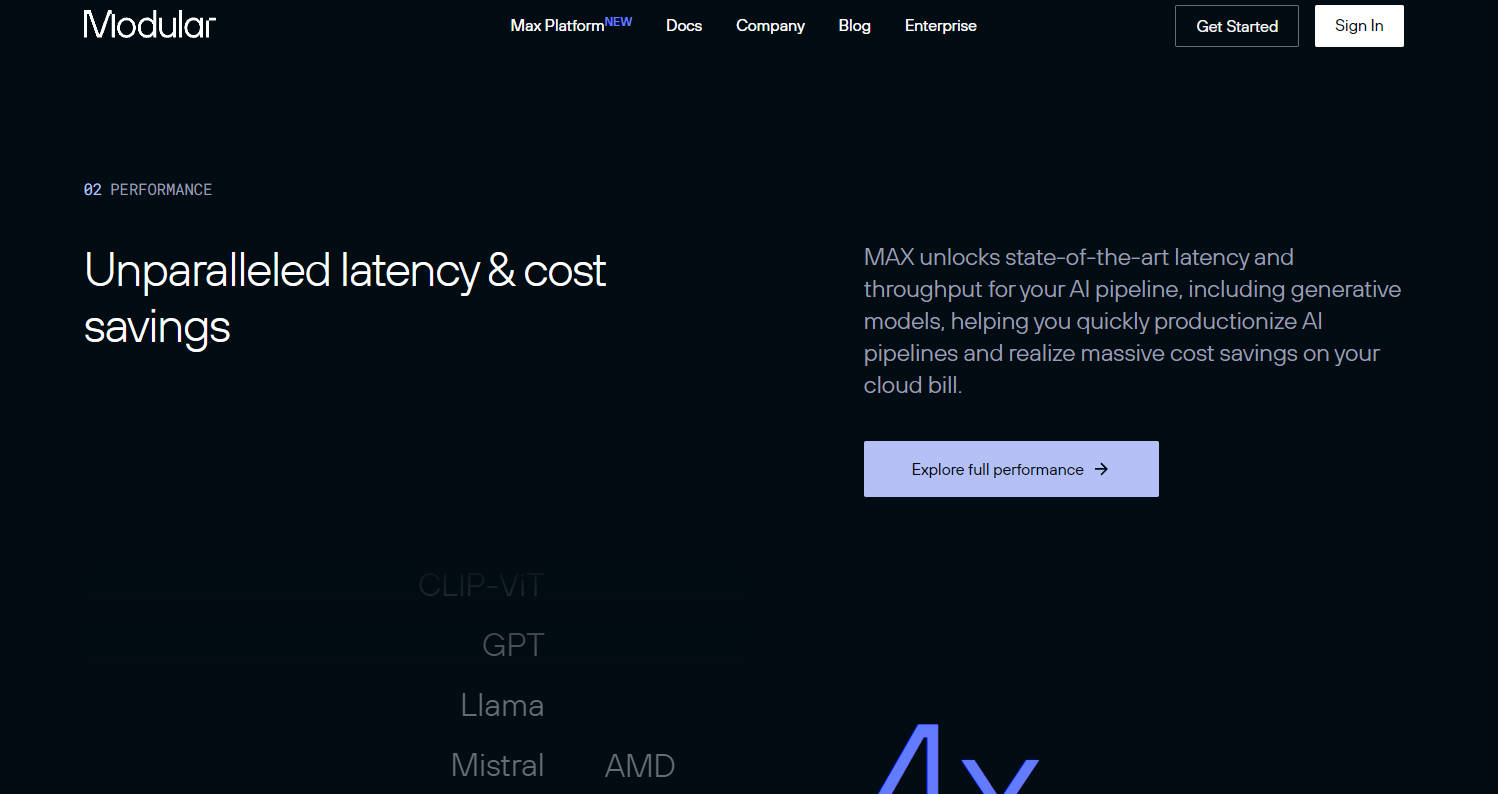
탁월한 성능: 플랫폼의 핵심 구성 요소인 MAX 엔진은 AI 파이프라인에 최신 지연 시간과 처리량을 제공합니다. 여기에는 생성 모델이 포함되어 AI 파이프라인을 신속히 생산화하고 클라우드 인프라에서 상당한 비용을 절감할 수 있습니다.
-
원활한 이식성: MAX는 AI 모델과 파이프라인을 모든 하드웨어 대상으로 쉽게 옮길 수 있도록 합니다. 이러한 유연성은 성능 대비 비용 비율을 극대화하고 벤더 잠금을 없애 하드웨어 선택의 자유와 효율성을 제공합니다.
-
MAX 엔진: 모델 추론 런타임 및 API 라이브러리인 MAX 엔진은 모든 하드웨어에서 놀라운 성능으로 AI 파이프라인을 실행합니다. TensorFlow, PyTorch 또는 ONNX와 같은 기존 추론 호출에서 빠르게 전환할 수 있는 간단한 Python 또는 C API를 제공하며 다양한 CPU 아키텍처에서 최대 5배 빠른 실행을 제공합니다.
-
MAX Serving: MAX 엔진을 위한 이 모델 서빙 라이브러리는 기존 서빙 시스템과의 완벽한 상호 운용성과 Kubernetes와 같은 컨테이너 인프라 내의 원활한 배포를 제공합니다. NVIDIA Triton Inference Server와 같은 시스템을 대체할 수 있어 통합과 배포의 편의성을 향상시킵니다.
사용 사례:
-
빠른 성능 향상: MAX는 AI 모델 성능을 신속하게 향상시킬 수 있습니다. 현재 추론 호출을 MAX 엔진으로 대체하면 최소한의 코드 변경으로 상당한 속도 향상을 얻을 수 있습니다.
-
모델 확장 및 최적화: MAX 엔진을 사용하면 사용자는 Mojo를 사용하여 모델을 더욱 최적화할 수 있습니다. 여기에는 추론을 위한 MAX Graph API를 활용하여 맞춤형 연산자를 작성하거나 전체 모델을 Mojo에서 구축하는 것이 포함됩니다.
-
풀 스택 최적화: MAX는 추론을 넘어 전체 AI 파이프라인을 최적화할 수 있습니다. 사용자는 데이터 사전/사후 처리 코드와 애플리케이션 코드를 Mojo로 마이그레이션할 수 있으며 지속적으로 추가되는 MAX 도구와 라이브러리를 사용하여 AI 스택 전반에 걸쳐 개발을 가속화할 수 있습니다.
MAX를 선택하는 이유:
-
AI 전문가가 구축: Modular 팀에는 TensorFlow, PyTorch, ONNX, XLA와 같은 기본 AI 인프라에 기여한 세계적인 AI 전문가들이 있습니다.
-
재창조된 AI 인프라: MAX는 AI 스택의 "원칙적 재구축"을 나타내며, 신선하고 효율적인 접근 방식으로 기존 솔루션의 복잡성을 해결합니다.
-
원활히 작동하는 인프라: MAX는 기존 워크플로우에 원활하게 통합되도록 설계되었으며 모델 재작성이나 하드웨어 전문 지식이 필요하지 않으므로 최첨단 기술을 활용할 수 있습니다.
MAX는 플랫폼 그 이상입니다. AI가 개발 및 배포되는 방식에 대한 패러다임 전환이며 AI 엔지니어와 조직에 미래 지향적이고 고성능의 솔루션을 제공합니다. MAX를 통해 AI 하드웨어의 잠재력이 완전히 해제되어 차세대 AI 혁신의 길을 열 수 있습니다.
More information on Modular
Launched
1997-05
Pricing Model
Starting Price
Global Rank
217916
Follow
Month Visit
199.1K
Tech used
Google Analytics,Google Tag Manager,LinkedIn Insights,Webflow,Amazon AWS CloudFront,cdnjs,JSDelivr,unpkg,jQuery,KaTeX,Gzip,OpenGraph,RSS
Top 5 Countries
19.26%
4.26%
4.05%
3.99%
3.69%
United States
Germany
Russia
India
Korea, Republic of
Traffic Sources
4.08%
0.73%
0.1%
9.26%
48.73%
37.03%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Modular was manually vetted by our editorial team and was first featured on 2024-05-11.
Related Searches
Modular 대체품
더보기 대체품-

-

MiniMax-M1: 100만 토큰 컨텍스트 및 심층 추론 능력을 갖춘 가중치 공개 AI 모델입니다. 고급 AI 애플리케이션을 위해 방대한 데이터를 효율적으로 처리합니다.
-

-
데이터 탐색, 분석, 통찰력 도출을 단 몇 초 만에 도와주는 AI 데이터 분석 지원자인 Max를 만나보세요. Max는 GPT-3.5 Turbo AnswerRocket의 힘을 빌렸습니다.
-
