
What is OmniSQL?
자연어 질문과 구조화된 데이터베이스 쿼리 사이의 간극을 좁히는 것은 상당한 과제가 될 수 있습니다. 특히 복잡한 데이터베이스와 다양한 표현을 다룰 때, 사용자 의도를 정확한 SQL로 변환할 수 있는 신뢰할 수 있는 방법이 필요합니다. OmniSQL은 광범위하고 수준 높은 합성 데이터 세트를 기반으로 구축된 정교한 text-to-SQL 모델 제품군을 제공하여 이러한 목표를 달성하도록 돕습니다.
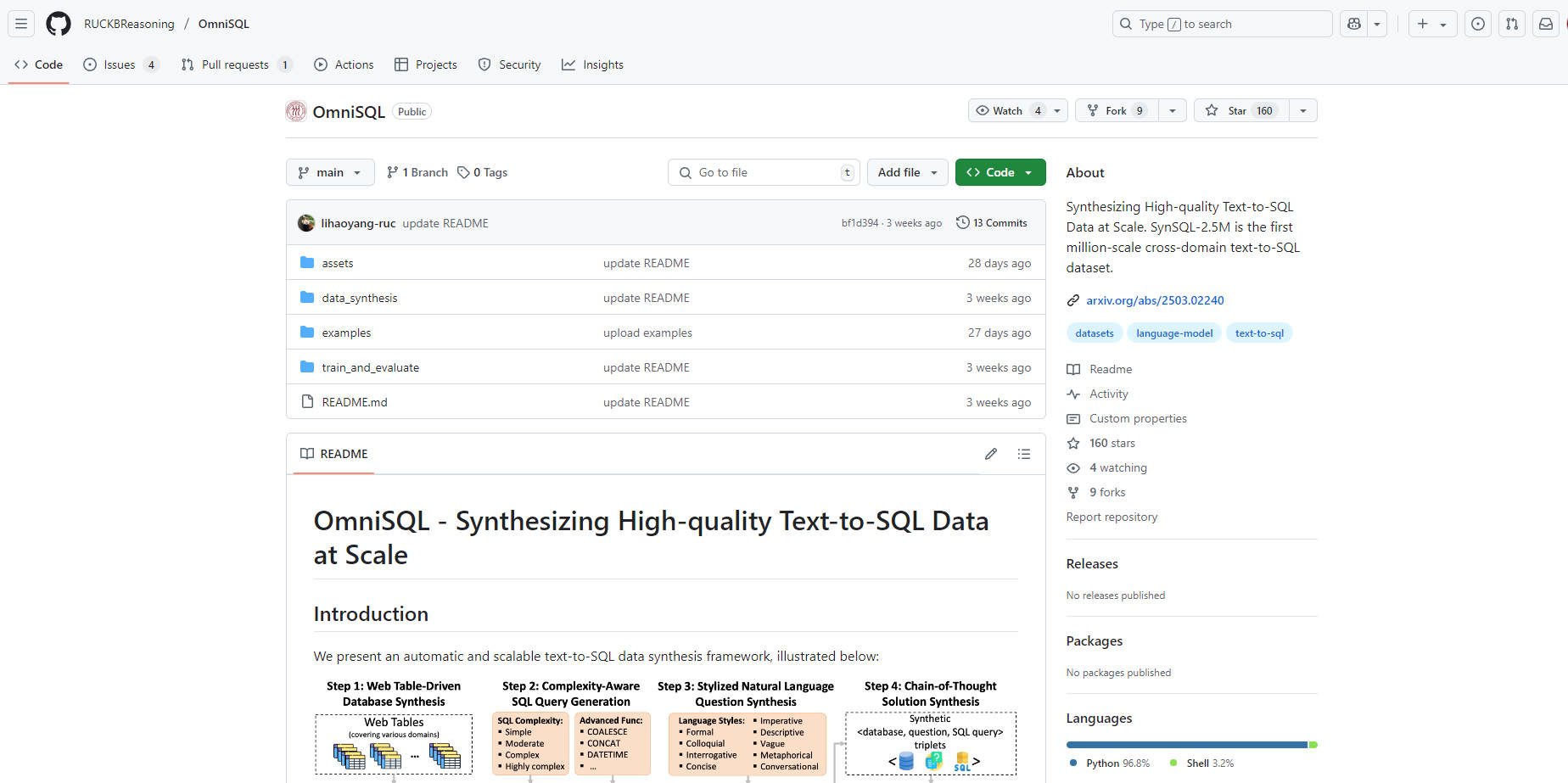
OmniSQL은 혁신적인 자동 데이터 합성 프레임워크를 사용하여 개발되었으며, SynSQL-2.5M 데이터 세트를 활용합니다. 이 기본 데이터 세트는 16,000개 이상의 데이터베이스에 걸쳐 250만 개 이상의 text-to-SQL 샘플을 포함하고 있어 고성능 모델을 훈련하는 데 필요한 규모와 다양성을 제공합니다. 7B, 14B, 32B 파라미터 크기로 제공되는 OmniSQL 모델은 Spider 및 BIRD와 같은 기존 벤치마크에서 추가 미세 조정되어 품질 향상을 위해 사람이 레이블링한 데이터를 통합합니다.
주요 기능 및 구성 요소
📊 다양한 모델 크기: OmniSQL 모델(7B, 14B, 32B) 중에서 컴퓨팅 리소스 및 성능 요구 사항에 가장 적합한 모델을 선택하십시오. 각 모델은 강력한 text-to-SQL 기능을 위해 미세 조정되었습니다.
📚 대규모 훈련 데이터 세트 (SynSQL-2.5M): 다양한 도메인과 SQL 복잡성 수준(단순에서 매우 복잡)에 걸쳐 16,583개의 합성 데이터베이스를 포함하는 250만 개 이상의 다양한 text-to-SQL 샘플로 훈련된 모델의 이점을 누리십시오.
🧠 Chain-of-Thought (CoT) 통합: SynSQL-2.5M의 각 샘플에는 CoT 솔루션이 포함되어 있어 모델이 복잡한 쿼리를 생성하기 위한 추론 단계를 학습할 수 있습니다.
📈 입증된 높은 성능: OmniSQL 모델은 Execution Accuracy (EX) 및 Test-Suite Accuracy (TS) 메트릭을 기반으로 다양한 text-to-SQL 벤치마크(Spider, BIRD, Spider-DK, Spider-Syn 포함)에서 강력한 결과를 보여주며, 유사한 규모의 다른 모델은 물론 특정 데이터 세트에서 더 큰 독점 모델의 성능을 능가하는 경우가 많습니다. 자세한 내용은 전체 성능 표를 참조하십시오.
🔧 오픈 소스 합성 프레임워크: SynSQL-2.5M을 생성하는 데 사용된 기본 프레임워크에 액세스하여 SQLite 이외의 특정 도메인 또는 SQL 방언에 맞게 조정된 사용자 지정 대규모 text-to-SQL 데이터 세트를 생성할 수 있습니다.
💻 간편한 통합: 제공된 코드 스니펫 및 명확한 프롬프트 템플릿을 사용하여 vLLM 및 Hugging Face Transformers와 같은 친숙한 도구를 사용하여 빠르게 시작하십시오.
활용 사례
데이터 분석가 및 과학자를 위해: 자연어로 표현된 임시 데이터 요청을 자주 받습니다. 매번 SQL을 수동으로 작성하는 대신 OmniSQL을 사용하여 "지난 분기 캘리포니아 고객의 평균 주문 금액을 보여주세요" 또는 "올해 EU 지역에서 판매된 상위 5개 제품과 총 수익을 나열해주세요"와 같은 질문에서 정확한 SQLite 쿼리를 빠르게 생성할 수 있습니다. 이를 통해 데이터 탐색 및 보고서 생성이 가속화됩니다.
NLP 연구자를 위해: 복잡한 text-to-SQL 변환의 과제를 조사하고 있습니다. 광범위한 규모, 다양한 언어 스타일, 다양한 SQL 복잡성 및 포함된 CoT 추론을 갖춘 SynSQL-2.5M 데이터 세트를 새로운 모델 또는 기술을 훈련, 평가 및 분석하기 위한 포괄적인 리소스로 사용할 수 있습니다. 또한 오픈 소스 데이터 합성 프레임워크를 활용하여 변형 또는 확장을 탐색할 수도 있습니다.
애플리케이션 개발자를 위해: 비기술적 사용자가 자연어를 사용하여 데이터베이스를 쿼리할 수 있도록 하는 애플리케이션 기능을 구축하는 것을 목표로 합니다. OmniSQL 모델(예: 리소스 효율성을 위한 OmniSQL-7B)을 백엔드에 통합할 수 있습니다. 제공된 프롬프트 구조를 사용하여 애플리케이션은 사용자의 질문(예: "어제 열렸고 아직 해결되지 않은 지원 티켓은 무엇입니까?")을 가져와 관련 SQLite 데이터베이스 스키마와 함께 OmniSQL에 전달하여 실행 가능한 SQL 쿼리를 다시 얻을 수 있습니다.
결론
대규모 SynSQL-2.5M 데이터 세트로 구동되는 OmniSQL은 text-to-SQL 작업에 대한 강력하고 고성능 솔루션을 제공합니다. 데이터를 분석하든, 연구를 수행하든, 애플리케이션을 구축하든 OmniSQL은 다양하고 고품질 데이터 기반으로 구축된 유능한 모델을 제공합니다. 다양한 모델 크기, 강력한 벤치마크 성능, 합성 프레임워크의 오픈 소스 특성은 자연어와 데이터베이스의 교차점에서 작업하는 모든 사람에게 귀중한 자산이 됩니다.
More information on OmniSQL
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
OmniSQL was manually vetted by our editorial team and was first featured on 2025-03-31.
OmniSQL 대체품
더보기 대체품-

OpenSQL.ai로 질문을 즉시 SQL로 변환하세요! 평범한 영어로 입력하기만 하면 정확한 SQL 코드를 얻을 수 있습니다. 데이터 작업을 간소화하고 싶은 모든 사람에게 완벽합니다. 오늘 바로 시도해보고 SQL을 쉽게 만들어보세요!
-

-
-
OWOX BI SQL Copilot은 데이터베이스에 자동으로 연결되어 데이터 및 비즈니스 팀이 정확한 SQL을 손쉽게 만들 수 있도록 지원합니다. 무료로 이용 가능합니다.
-
