
What is OmniSQL?
要縮小自然語言提問和結構化資料庫查詢之間的差距,可能是一項重大挑戰。您需要一個可靠的方法,將使用者意圖轉換為精確的 SQL 語法,尤其是在處理複雜資料庫和多樣化措辭時。OmniSQL 提供一系列精密的 text-to-SQL 模型,建立在廣泛且高品質的合成資料集之上,旨在協助您達成此目標。
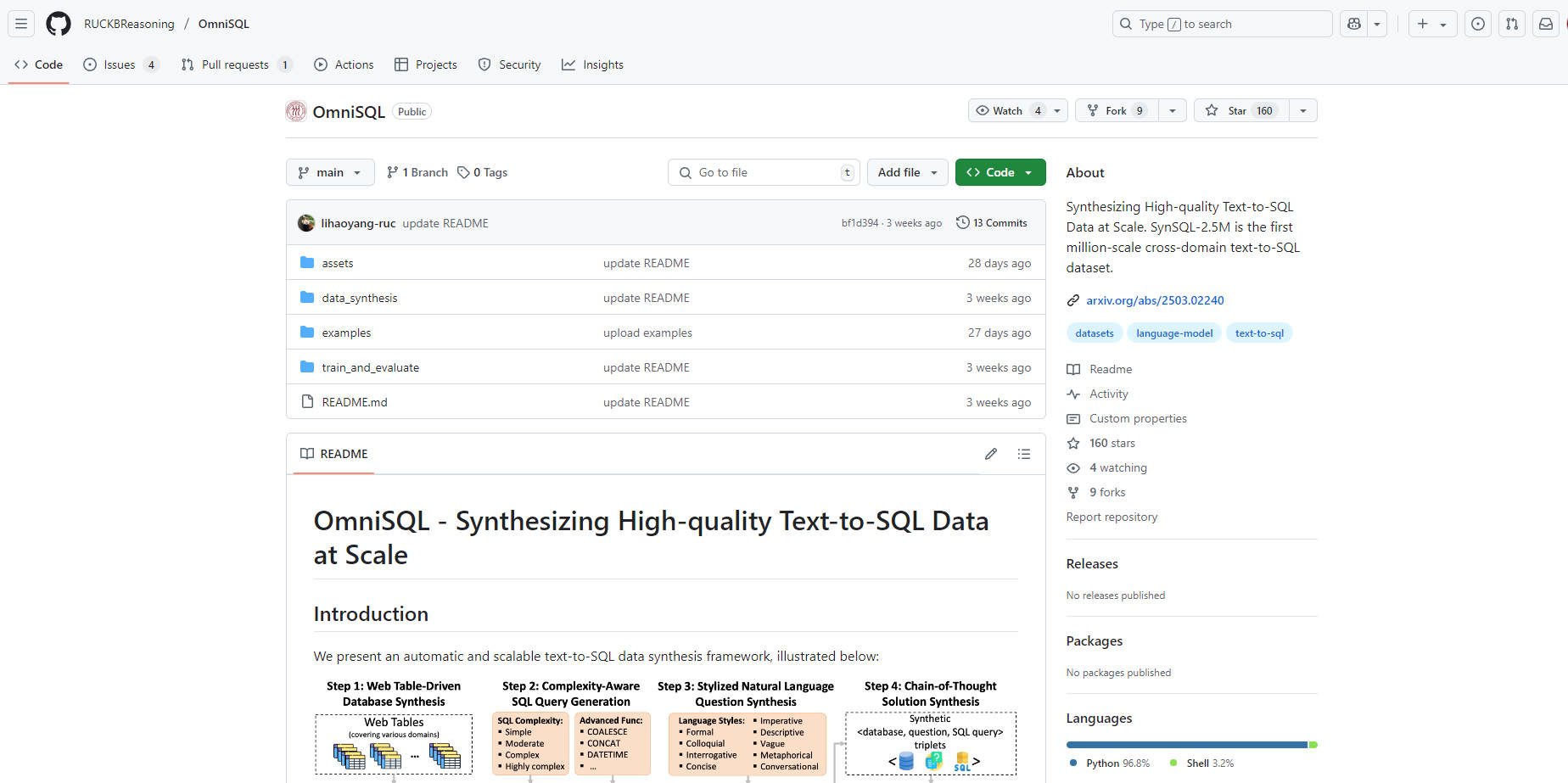
OmniSQL 使用一種創新的自動資料合成架構開發而成,充分利用了 SynSQL-2.5M 資料集。這個基礎資料集包含超過 250 萬個 text-to-SQL 樣本,涵蓋超過 16,000 個資料庫,提供訓練高效能模型所需的規模和多樣性。OmniSQL 模型提供 7B、14B 和 32B 等多種參數規模,並在 Spider 和 BIRD 等已建立的基準上進一步微調,整合人工標記的資料以提高品質。
主要特色與組件
📊 多種模型規模: 選擇最符合您運算資源和效能需求的 OmniSQL 模型 (7B、14B、32B)。每個模型都經過微調,以具備強大的 text-to-SQL 功能。
📚 大規模訓練資料集 (SynSQL-2.5M): 受益於在超過 250 萬個多樣化 text-to-SQL 樣本上訓練的模型,涵蓋各種領域和 SQL 複雜度等級 (從簡單到高度複雜) 的 16,583 個合成資料庫。
🧠 思維鏈 (CoT) 整合: SynSQL-2.5M 中的每個樣本都包含一個 CoT 解決方案,使模型能夠學習產生複雜查詢的推理步驟。
📈 經驗證的高效能: OmniSQL 模型在眾多 text-to-SQL 基準 (包括 Spider、BIRD、Spider-DK、Spider-Syn) 中展現出強勁的成果,通常超越其他類似規模的模型,甚至在特定資料集上超越更大的專有模型,評估標準基於執行準確度 (EX) 和測試套件準確度 (TS) 指標。請參閱完整的效能表以了解詳細資訊。
🔧 開放原始碼合成架構: 存取用於建立 SynSQL-2.5M 的底層架構,讓您可以產生自訂的大規模 text-to-SQL 資料集,以針對特定領域或 SQLite 以外的 SQL 方言進行客製化。
💻 輕鬆整合: 使用熟悉的工具 (例如 vLLM 和 Hugging Face Transformers),以及提供的程式碼片段和清晰的提示範本,快速開始使用。
使用案例
適用於資料分析師和科學家: 您經常收到以自然語言表達的臨時資料請求。您可以利用 OmniSQL 快速從諸如「顯示我加州客戶上季的平均訂單價值」或「列出今年在歐盟地區銷售的前 5 名產品及其總收入」等問題中,產生精確的 SQLite 查詢,而無需每次都手動編寫 SQL。這加快了資料探索和報告產生的速度。
適用於自然語言處理研究人員: 您正在研究複雜 text-to-SQL 轉換的挑戰。您可以利用 SynSQL-2.5M 資料集,憑藉其龐大的規模、多樣化的語言風格、各種 SQL 複雜性和包含的 CoT 推理,作為訓練、評估和分析新模型或技術的全面資源。您還可以利用開放原始碼資料合成架構來探索變體或擴展。
適用於應用程式開發人員: 您旨在建立一個應用程式功能,讓非技術使用者可以使用自然語言查詢資料庫。您可以將 OmniSQL 模型 (例如,針對資源效率的 OmniSQL-7B) 整合到您的後端。使用提供的提示結構,您的應用程式可以接收使用者的問題 (例如,「昨天開啟且尚未解決的支援票有哪些?」),並將其與相關的 SQLite 資料庫綱要一起傳遞給 OmniSQL,以取回可執行的 SQL 查詢。
結論
OmniSQL 由大規模的 SynSQL-2.5M 資料集提供支援,為 text-to-SQL 任務提供強大且高效能的解決方案。無論您是分析資料、進行研究還是建構應用程式,OmniSQL 都能提供建立在多樣化、高品質資料基礎之上的高效模型。多種模型規模的可用性、強大的基準效能以及合成架構的開放原始碼特性,使其成為在自然語言和資料庫交叉領域工作的任何人的寶貴資產。
More information on OmniSQL
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
OmniSQL was manually vetted by our editorial team and was first featured on 2025-03-31.
OmniSQL 替代方案
更多 替代方案-

使用 OpenSQL.ai 將您的問題立即轉換成 SQL!只需用簡單的英文輸入,即可獲得精確的 SQL 程式碼。非常適合想要簡化資料任務的任何人 - 立即試用,讓 SQL 變得輕鬆!
-

-
-
-
