
What is OmniSQL?
将自然语言问题转化为结构化数据库查询一直以来都是一个巨大的挑战。尤其是在处理复杂数据库和各式各样的提问方式时,您需要一种可靠的方法将用户意图转化为准确的 SQL 语句。 OmniSQL 提供了一系列精密的 text-to-SQL 模型,这些模型基于大规模、高质量的合成数据集构建,旨在帮助您实现这一目标。
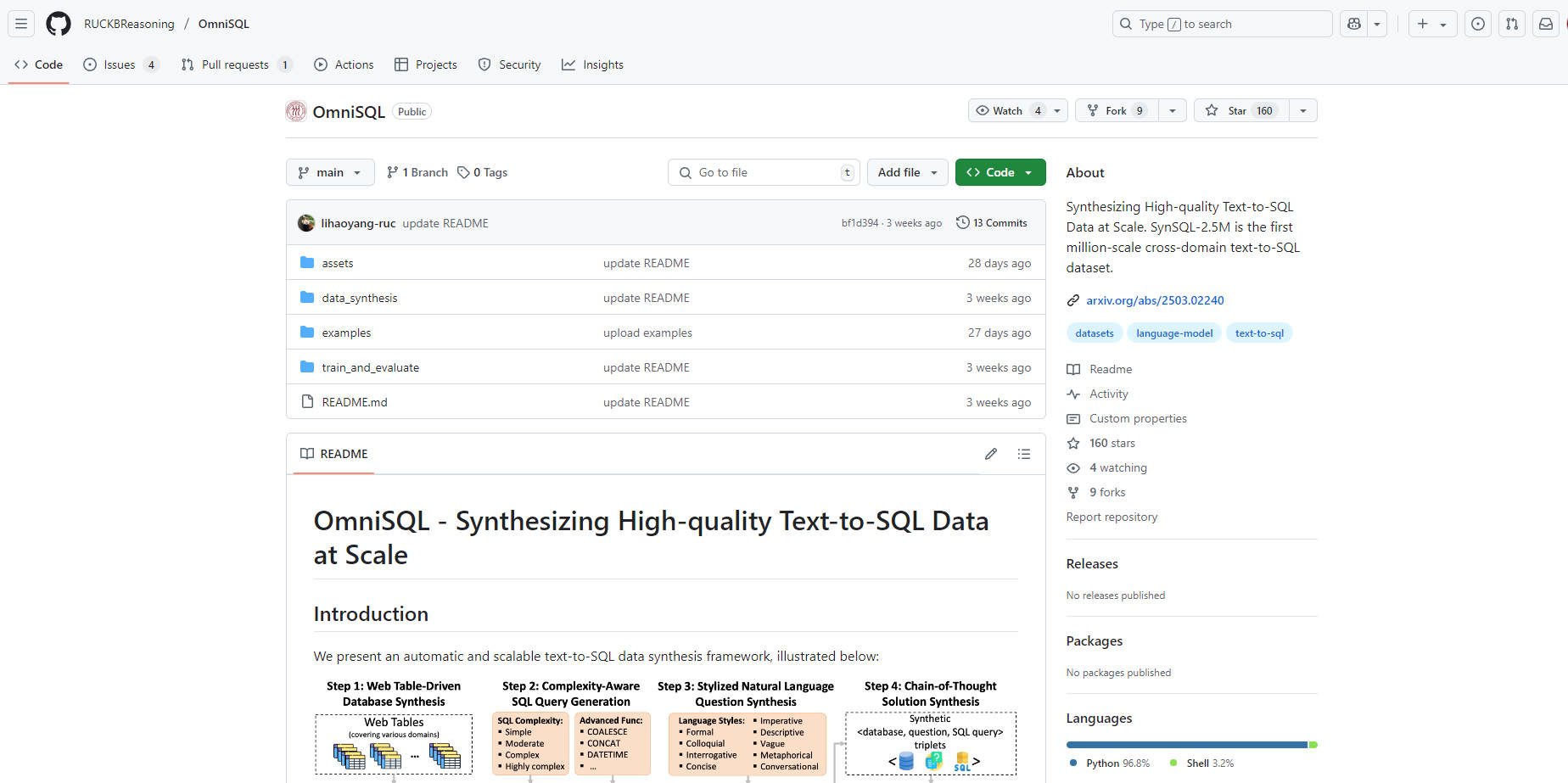
OmniSQL 采用了一种新颖的自动数据合成框架进行开发,充分利用了 SynSQL-2.5M 数据集。这个基础数据集包含超过 250 万个 text-to-SQL 样本,涵盖超过 16000 个数据库,提供了训练高性能模型所需的规模和多样性。 OmniSQL 模型提供 7B、14B 和 32B 三种参数规模,并在 Spider 和 BIRD 等已建立的基准上进一步微调,整合人工标注数据以提高质量。
主要特性与组件
📊 多种模型规模:选择最适合您的计算资源和性能需求的 OmniSQL 模型(7B、14B、32B)。每个模型都经过微调,具有强大的 text-to-SQL 能力。
📚 大规模训练数据集 (SynSQL-2.5M):受益于在超过 250 万个多样化的 text-to-SQL 样本上训练的模型,这些样本涵盖了各种领域和 SQL 复杂程度(从简单到高度复杂)的 16583 个合成数据库。
🧠 Chain-of-Thought (CoT) 集成: SynSQL-2.5M 中的每个样本都包含一个 CoT 解决方案,使模型能够学习生成复杂查询的推理步骤。
📈 卓越的性能表现: OmniSQL 模型在众多 text-to-SQL 基准测试(包括 Spider、BIRD、Spider-DK、Spider-Syn)中表现出色,通常超过同等规模的其他模型,甚至在特定数据集上超过更大的专有模型,评估指标为 Execution Accuracy (EX) 和 Test-Suite Accuracy (TS)。有关详细信息,请参阅完整的性能表。
🔧 开源合成框架:访问用于创建 SynSQL-2.5M 的底层框架,使您能够生成定制的大规模 text-to-SQL 数据集,这些数据集可以针对超出 SQLite 的特定领域或 SQL 方言进行定制。
💻 轻松集成:使用提供的代码片段和清晰的提示模板,通过 vLLM 和 Hugging Face Transformers 等常用工具快速入门。
使用场景
对于数据分析师和科学家:您经常收到用自然语言表达的临时数据请求。无需每次都手动编写 SQL,您可以使用 OmniSQL 从诸如“显示上季度加利福尼亚州客户的平均订单价值”或“列出今年在欧盟地区销售的前 5 名产品及其总收入”之类的问题中快速生成准确的 SQLite 查询。这可以加速数据探索和报告生成。
对于 NLP 研究人员:您正在研究复杂 text-to-SQL 转换的挑战。您可以使用 SynSQL-2.5M 数据集,凭借其庞大的规模、多样化的语言风格、各种 SQL 复杂性以及包含的 CoT 推理,作为训练、评估和分析新模型或技术的综合资源。您还可以利用开源数据合成框架来探索变体或扩展。
对于应用程序开发人员:您旨在构建一个应用程序功能,允许非技术用户使用自然语言查询数据库。您可以将 OmniSQL 模型(例如,OmniSQL-7B,以提高资源效率)集成到您的后端。使用提供的提示结构,您的应用程序可以接收用户的问题(例如,“昨天打开但仍未解决的支持票有哪些?”),并将其与相关的 SQLite 数据库模式一起传递给 OmniSQL,以获得可执行的 SQL 查询。
结论
OmniSQL 由大规模 SynSQL-2.5M 数据集提供支持,为 text-to-SQL 任务提供了一个强大且高性能的解决方案。无论您是分析数据、进行研究还是构建应用程序,OmniSQL 都能提供基于多样化、高质量数据构建的高性能模型。多种模型规模的可用性、强大的基准性能以及合成框架的开源特性使其成为任何从事自然语言和数据库交叉工作的人员的宝贵资产。
More information on OmniSQL
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
OmniSQL was manually vetted by our editorial team and was first featured on 2025-03-31.
OmniSQL 替代方案
更多 替代方案-

使用 OpenSQL.ai 将您的问题立即转换为 SQL!只需用简单的英语输入,即可获得精确的 SQL 代码。非常适合希望简化数据任务的任何人 - 立即尝试,让 SQL 变得简单!
-

-
-
-
