
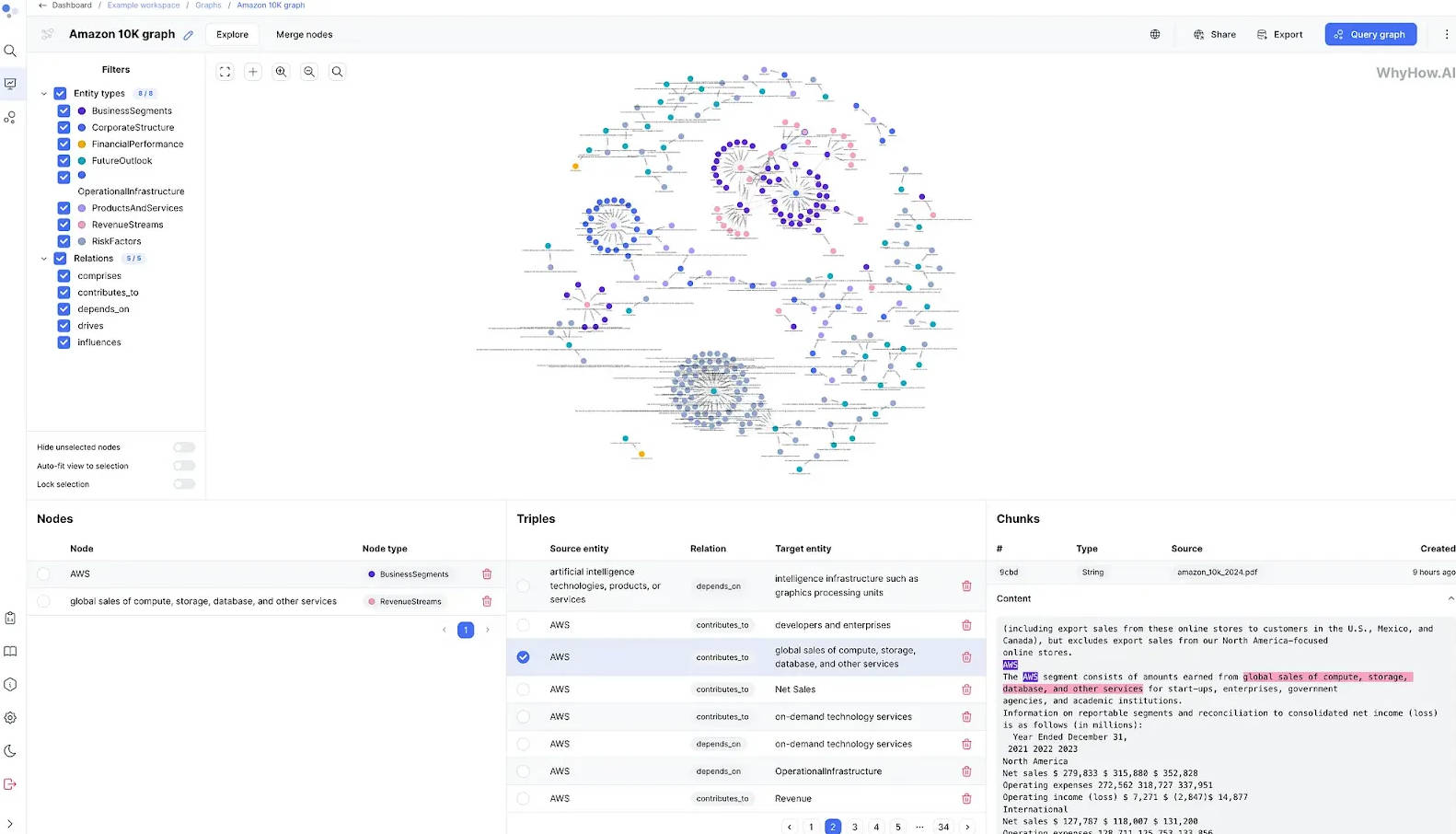
What is Knowledge Graph Studio?
Knowledge Graph Studio 是一个强大且开源的平台,旨在加速可靠、可解释、高精度的AI系统开发,特别是那些利用先进 Agentic RAG(检索增强生成)工作流的系统。它通过提供一个模块化、API优先的框架来构建和查询知识图谱,从而无缝结合结构化和非结构化数据,解决了单纯依赖向量搜索的关键局限性。本次发布赋能开发者、研究人员和领域专家,使其能够定制和控制基于图谱的AI应用的每一个环节。
核心功能
Knowledge Graph Studio 旨在提供最直观的方式来构建 RAG 原生知识表示,重点关注精确性、可控性和集成性。
🔌 API 优先设计与 Python SDK 秉持 API 优先的设计理念,WhyHow 提供了极致的灵活性和强大的集成能力。我们原生的 JSON 数据摄取工作流和全面的 Python SDK 允许开发者通过编程方式与各项功能进行交互,将图谱的创建和查询无缝集成到现有系统和 RAG 管道中。
🧠 将向量块作为一等公民的混合搜索 通过将文本块(非结构化数据)视为核心原语,并将其直接链接到图谱的节点和三元组(结构化数据)中,Knowledge Graph Studio 克服了纯向量搜索的固有局限性。这种将语义相似性与关系上下文结合的能力,确保了检索本身就具有深度和可解释性,从而产生更准确、更具确定性的信息工作流。
🎯 先进的语义三元组检索 不同于传统图谱查询方法常依赖于存在问题的 Text2Cypher 转换,WhyHow 直接嵌入三元组并通过语义相似性进行检索。这种技术确保了上下文窗口能够接收到更丰富、关联更紧密的信息,在特定基准测试中,检索响应的准确性比使用 Text2Cypher 查询的同等图谱高出 2倍。
🧩 模块化、小型图谱创建 通过为特定数据集或用例创建专注的、自包含的知识表示,充分利用模块化的强大功能。这种“小图谱”方法支持有针对性的实验、微调和高效调试,这对于 RAG 应用至关重要,因为在 RAG 应用中,对上下文的精确性和控制是首要的。
🤝 人机协作的实体解析 通过一个直观的、基于规则的系统,赋能领域专家执行个性化、针对特定用例的实体解析。用户可以轻松合并相似实体,并将这些决策保存为可复用规则,随着时间的推移,持续提高图谱创建的一致性和准确性。
用例
Knowledge Graph Studio 为在要求严苛的领域构建复杂的 AI 应用提供了必要的结构性支柱。
构建高精度合规助手: 利用模块化图谱结构,摄取特定的监管文件(非结构化文本块),并将其直接链接到已定义的实体、组织关系和规则集(结构化数据)。当用户提出复杂的合规问题时,系统会同时检索语义相关的文本块和强制性的关联关系上下文,确保在法律和金融等敏感领域提供可解释、可审计且无幻觉的答案。
增强智能体的记忆和复杂推理能力: 为 AI 智能体提供持久化、结构化且可查询的记忆层。不再仅仅依赖简单的顺序聊天历史,智能体可以查询知识图谱,确定性地检索相关的过往行动、约束和关系。这一能力显著提升了多步骤规划、复杂决策和长期对话记忆任务的性能。
定制数据转换管道: 利用其开源特性和 API 优先设计,构建针对特定用例的数据转换管道。无论您需要根据特殊数据结构调整实体提取,还是与专有的内部监控工具集成,该平台都能让您将图谱创建、管理和模式构建过程完美地适配您的数据需求。
独特优势
Knowledge Graph Studio 专为现代 LLM 系统和 Agentic RAG 的需求而设计,相较于传统知识库解决方案,提供了独特的优势。
卓越的检索准确性: 通过利用嵌入式三元组进行语义检索,而非依赖 LLM 将自然语言转换为可能容易出错的图查询语言(如 Text2Cypher),该平台能够提供明显更准确、更具确定性的结果。
真正的混合数据集成: 该架构基于 MongoDB 等灵活的数据库构建(未来计划实现数据库无关性),结合了关系数据、向量存储和灵活模式的优势。这使得您可以在单一检索机制中,将非结构化文本的上下文与结构化关系的精确性相结合。
通过开源实现透明度和控制: MIT 许可证允许团队将其直接安装、扩展并集成到自己的环境中。这种灵活性确保了对安全措施、监控工具和数据库选择的完全控制,从而实现根据特定企业需求定制知识图谱的快速、合规部署。
总结
Knowledge Graph Studio 提供了关键的开源基础设施,助力 RAG 应用从标准实现迈向更可靠、可解释、高精度的 AI 系统。通过促进社区发展,并提供对图谱构建和查询的全面控制,我们赋能开发者充分利用混合结构化数据检索的强大能力。
立即探索代码库,推动您的图谱驱动型 AI 解决方案。
More information on Knowledge Graph Studio
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Knowledge Graph Studio was manually vetted by our editorial team and was first featured on 2025-10-23.
Knowledge Graph Studio 替代方案
更多 替代方案-

用于图检索增强复杂推理的纵向统一智能体——革命性框架,相较于SOTA基线,在将token成本降低33.6%的同时,准确率提升16.62%,成功拓展了帕累托前沿。
-
-
-
-
