
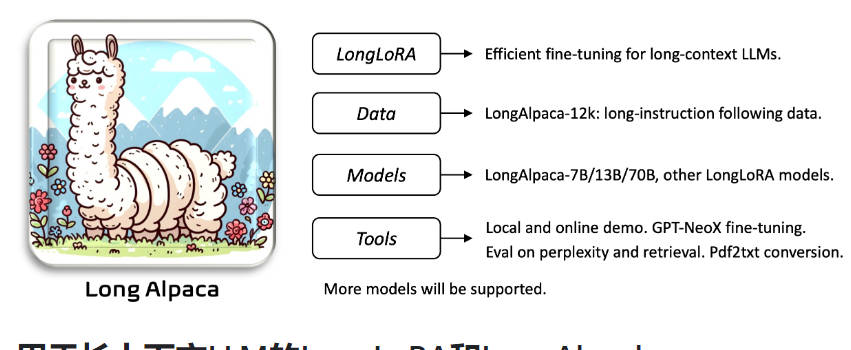
What is LongLoRA?
LongLoRA 解决了大型语言模型在处理长文本时存在的局限性。用户只需两行代码和一台 8 卡 A100 机器,即可将 7B 模型的文本长度扩展到 100k 个标记,将 70B 模型的文本长度扩展到 32k 个标记。此外,他们还发布了 LongAlpaca,这是世界上第一个具有 70B 参数的长文本对话语言模型。
主要特征:
1. LongLoRA:这项技术允许扩展大型语言模型中的文本长度。
2. 两行代码:实现 LongLoRA 只需两行代码。
3. 文本长度扩展:用户可以将文本长度从 7B 模型扩展到 100k 个标记,从 70B 模型扩展到 32k 个标记。
4. LongAlpaca 模型:团队开发了 LongAlpaca,这是一种具有令人印象深刻的参数计数的长文本对话语言模型。
用例:
1. 学术论文:研究人员可以使用 LongAlpaca 来获取有关其论文的反馈,并通过提供更精确的解释、严格的实验结果、更广泛的应用、未来的发展方向、关键贡献和影响来提高论文的被接受率。
2. 会议论文比较:通过使用在 ICLR 和 CVPR 等不同会议论文上训练的 LongAlpaca,用户可以根据结构重点或理论分析和数学推导的灵活性,总结这些会议之间的风格差异。
3. 经济分析:用户可以利用 LongAlpaca 总结多年来的全球经济展望或根据国际组织(如国际货币基金组织)提供的总结预测未来趋势。
4. 小说分析:读者可以在通读长篇小说后使用 LongAlpaca 来进行分析。
LongLoRA 是一项革命性突破,解决了大型语言模型在处理长文本时存在的局限性。凭借其扩展文本长度和发布 LongAlpaca(一种具有令人印象深刻的参数计数的长文本对话语言模型)的能力,港中文贾佳亚和麻省理工学院为研究人员、学者和读者开辟了新的可能性。这项技术不仅扩展了大型语言模型的上下文窗口,还展示了对行业中长文本能力的重新思考和关注。
More information on LongLoRA
Launched
2024
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
LongLoRA was manually vetted by our editorial team and was first featured on 2023-10-10.
Related Searches
LongLoRA 替代方案
更多 替代方案-

-
-
清华大学推出的革命性语言模型 LongWriter,能够生成多达 20,000 字的文本。它是作家、记者等人士的理想工具,能够显著提高内容创作的效率和质量。
-

-
