
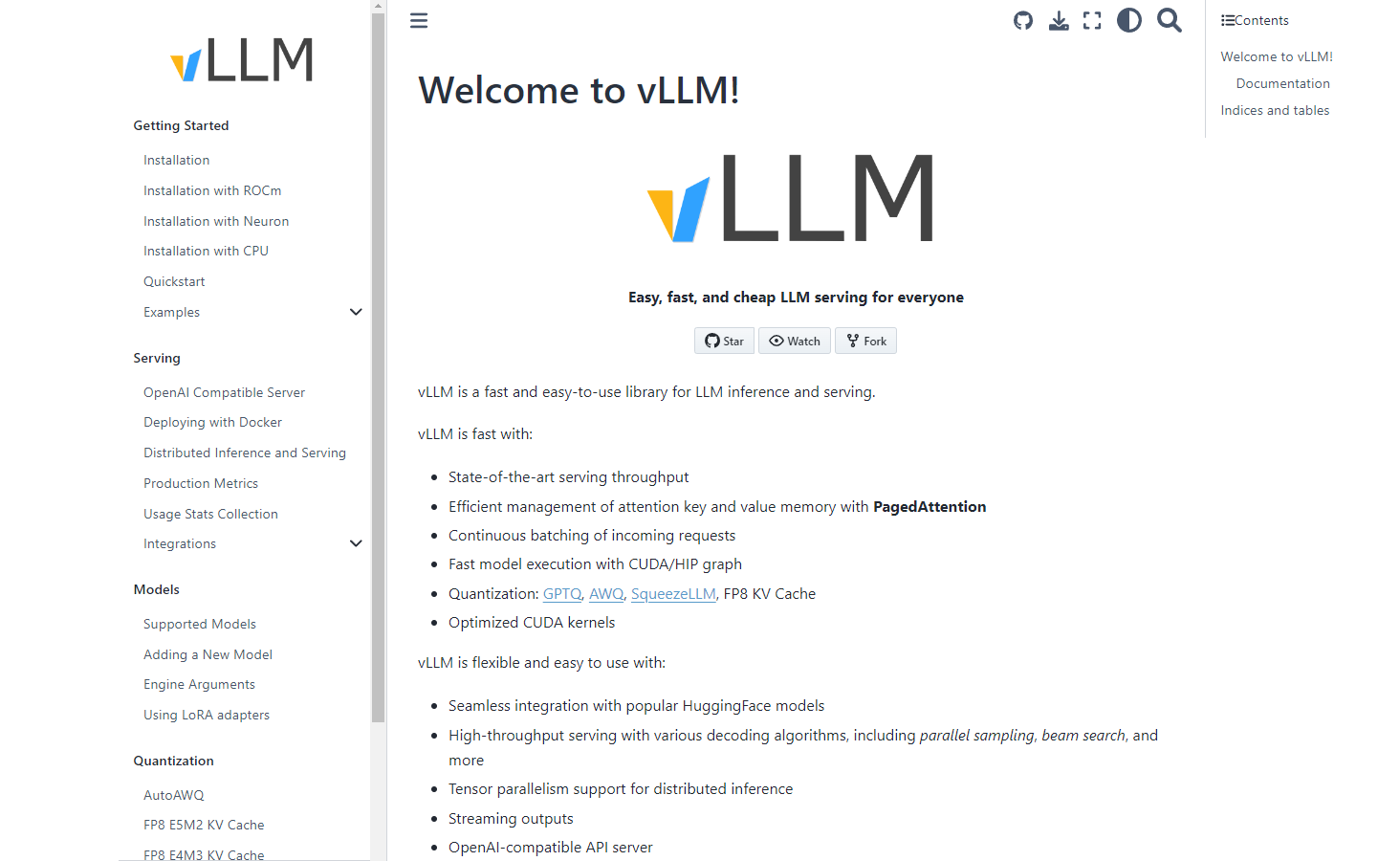
What is VLLM?
vLLM is a fast, flexible, and easy-to-use library for large language model (LLM) inference and serving. It provides state-of-the-art serving throughput, efficient management of attention key and value memory, and support for a wide range of popular Hugging Face models, including Aquila, Baichuan, BLOOM, ChatGLM, GPT-2, GPT-J, LLaMA, and many others.
Key Features
High Performance: vLLM is designed for fast and efficient LLM inference, with features like continuous batching of incoming requests, CUDA/HIP graph execution, and optimized CUDA kernels.
Flexible and Easy to Use: vLLM seamlessly integrates with popular Hugging Face models, supports various decoding algorithms (parallel sampling, beam search, etc.), and offers tensor parallelism for distributed inference. It also provides an OpenAI-compatible API server and streaming output capabilities.
Comprehensive Model Support: vLLM supports a wide range of LLM architectures, including Aquila, Baichuan, BLOOM, ChatGLM, GPT-2, GPT-J, LLaMA, and many more. It also includes experimental features like prefix caching and multi-LoRA support.
Use Cases
vLLM is a powerful tool for developers, researchers, and organizations looking to deploy and serve large language models in a fast, efficient, and flexible manner. It can be used for a variety of applications, such as:
Chatbots and conversational AI: vLLM can power chatbots and virtual assistants with its high-throughput serving capabilities and support for various decoding algorithms.
Content generation: vLLM can be used to generate high-quality text, such as articles, stories, or product descriptions, across a wide range of domains.
Language understanding and translation: vLLM's support for multilingual models can be leveraged for tasks like text classification, sentiment analysis, and language translation.
Research and experimentation: vLLM's ease of use and flexibility make it a valuable tool for researchers and developers working on advancing the field of large language models.
Conclusion
vLLM is a cutting-edge library that simplifies the deployment and serving of large language models, offering unparalleled performance, flexibility, and model support. Whether you're a developer, researcher, or organization looking to harness the power of LLMs, vLLM provides a robust and user-friendly solution to meet your needs.
More information on VLLM
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
VLLM was manually vetted by our editorial team and was first featured on 2024-04-29.
Related Searches
VLLM Alternatives
Load more Alternatives-

-

-
-

Introducing StreamingLLM: An efficient framework for deploying LLMs in streaming apps. Handle infinite sequence lengths without sacrificing performance and enjoy up to 22.2x speed optimizations. Ideal for multi-round dialogues and daily assistants.
-
