
Click outside to close
What is ExtractAny?
ExtractAny 是一個智慧型資料擷取平台,旨在將非結構化的網頁內容轉換為清晰、條理分明的資料。如果您需要在不編寫程式碼的情況下,從網站、文件或 PDF 中提取特定資訊,此工具能為您自動化整個過程。它運用強大的 AI 引擎,您只需透過簡單的指令引導,即可獲得精確且結構完善的所需資料。
主要功能
✍️ 提示詞導向的 AI 擷取 只需使用簡單的英文指令,即可精準告知 AI 欲擷取的內容——無論是聯絡資訊、產品規格或價格。這種透過提示詞驅動的方法,讓您能精準掌控擷取流程,確保 AI 僅專注於您重視的資訊。
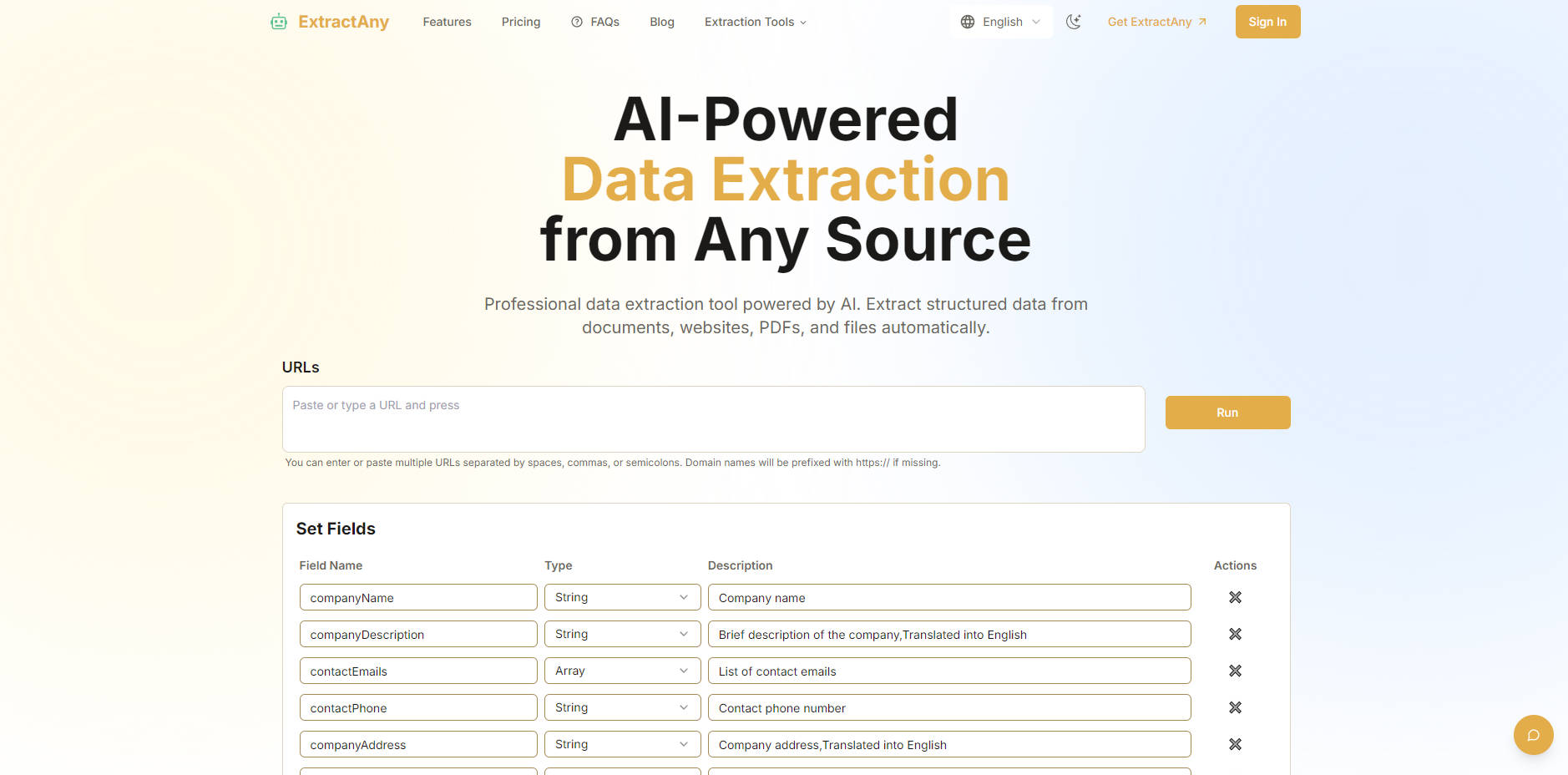
🏗️ 無程式碼視覺化結構建構器 透過直覺、視覺化的編輯器定義您所需的輸出資料結構。您可以指定欄位、資料類型(如文字或陣列),甚至建立巢狀結構,以完全符合您的精確需求。這確保了您的最終資料格式一致,可立即使用,無需任何程式設計。
🧩 進階結構辨識 ExtractAny 專為處理現代網站的複雜性而設計。其 AI 能智慧地解析並從複雜的版面配置中擷取資料,包括多層次清單、複雜表格以及動態載入的內容區塊,確保您能從其他工具可能失敗的來源中獲得完整且精確的結果。
⚡ 即時執行與匯出 無需任何設定或部署,即可即時執行您的資料擷取任務。只需輸入目標網址,定義您的資料結構,幾秒鐘內即可獲得結果。完成後,您可以立即將結構化資料匯出為 JSON 或 CSV 檔案,便於分析或整合至您的應用程式中。
ExtractAny 如何解決您的問題:
ExtractAny 專為實際且真實世界的資料收集任務而設計。以下是您可以立即運用它的幾個範例:
適用於市場與競爭者分析: 想像一下,您需要比較 50 個競爭產品的功能和定價。無需花費數小時手動從他們的網站上複製貼上,您可以設定 ExtractAny 自動造訪每個頁面,並將產品名稱、價格、主要功能和規格擷取到結構化的試算表中。這將原本需要數天的任務,轉化為您可在幾分鐘內完成的工作。
適用於 SEO 與內容策略: 透過使用 ExtractAny 收集專案的結構化資料,您可以迅速擴展您的內容工作。例如,指示 AI 爬取一系列文章,並擷取其 FAQ(常見問題)部分中的所有問答內容。然後,您可以使用這些結構化資料來產生綱要標記(Schema Markup)、識別內容缺口,或為您的網站建立全面的知識庫。
適用於銷售與潛在客戶開發: 自動化建立潛在客戶名單的繁瑣過程。向 ExtractAny 提供一份公司網站清單,並指示它尋找並擷取關鍵聯絡資訊,例如公司名稱、地址、電話號碼和電子郵件地址。此工具將提供一份清晰、條理分明的名單,供您的銷售團隊立即使用。
The ExtractAny Advantage: 獨特的擷取方法
不同於依賴嚴格、基於程式碼規則的傳統網路爬蟲,ExtractAny 結合了兩個強大的概念: 提示詞 (Prompts) + 綱要 (Schema)。
您無需了解 HTML 或 CSS 選擇器。您只需用自然語言來 描述 您想要的資料(即提示詞 Prompt),並 定義 您所需的資料結構(即綱要 Schema)。這種獨特的工作流程,使 ExtractAny 不僅功能極其強大,而且易於使用,讓技術人員和非技術使用者都能輕鬆執行複雜的資料擷取任務。
結論:
ExtractAny 從根本上簡化了將雜亂、非結構化網頁內容轉換為有價值的結構化資料的過程。它為分析師、研究人員、開發人員以及任何需要高效收集資訊的人,提供了一個快速、可靠且無需程式碼的解決方案。透過將 AI 驅動的擷取能力掌握在您手中,您可以省下無數小時的手動工作,將精力集中在資料的運用上,而非僅僅是收集。
More information on ExtractAny
Launched
2025-05
Pricing Model
Freemium
Starting Price
$9.9 USD
Global Rank
Follow
Month Visit
<5k
Tech used
ExtractAny was manually vetted by our editorial team and was first featured on 2025-07-12.
ExtractAny 替代
ExtractAny 替代-

將任何網站轉化為結構化的 API 或整潔的資料來源。運用 AI 與無程式碼工具,輕鬆擷取網路資料。實現強大而簡便的網路爬取。
-

Extractor API:運用 AI,從任何網頁、PDF 或新聞中提取乾淨、結構化的資料。自動化複雜的網路爬蟲,並善用 LLMs 獲取深入見解。
-
AnyPicker: AI 賦能的無程式碼網路爬蟲。輕鬆點擊滑鼠,即可從任何網站擷取結構化資料並匯出至試算表。安全無虞,隱私保障。
-

Parse Extract: 先進的資料萃取與光學字元辨識技術,專為大型語言模型(LLM)管線設計。能將繁雜的文件與網路數據,轉化為清晰易懂、可供LLM使用的文本。兼具成本效益與安全保障。
-
