What is BenchX?
Developing sophisticated AI agents presents unique challenges, especially when it comes to truly understanding and improving their performance. Going beyond simple pass/fail metrics is crucial for building reliable and accurate systems. BenchX provides a dedicated platform to help you rigorously evaluate and iterate on your AI agents. By enabling controlled experiments and delivering deep, actionable insights, BenchX helps you accelerate development cycles and build more effective AI applications based on solid data.
Key Features
📊 Capture Detailed Execution Insights: Go beyond surface-level results. BenchX allows you to record the specific steps your agent takes (
Decision Path), the data it accesses (Files Explored), and compare its output directly against the expected results (Your Output vs Expected Output). For deep dives,Raw Execution Logsare always available. This granular data helps pinpoint exactly where and why your agent succeeds or fails.📈 Unlock Advanced Performance Metrics: Move past single accuracy scores. BenchX provides a richer set of metrics and visualizations, offering a comprehensive view of your agent's behavior. This allows for more nuanced analysis, helping you uncover subtle issues and fine-tune performance with greater precision.
🏷️ Organize with Versioned Experiments: Keep your development process structured. BenchX automatically tracks and organizes your experiment history, linking every report directly to the specific version of your experiment code. This ensures reproducibility and makes it easy to compare performance across iterations without losing valuable insights.
⚙️ Run Reliable, Isolated Tests: Focus on your agent's logic, not infrastructure setup. You provide the task-handling code within a Docker image; BenchX manages the rest, feeding benchmark tasks to your code in isolated containers. This ensures consistent and controlled execution environments for dependable results.
🔄 Integrate Seamlessly into Workflows: Automate your evaluation process. BenchX offers a public API, allowing you to incorporate benchmark runs directly into your CI/CD pipelines. This enables continuous testing and performance tracking as part of your standard development lifecycle.
Use Cases
Comparing Agent Architectures: You've developed two different approaches for a task, like document summarization. Using BenchX, you can run both agent versions against the same benchmark dataset. Instead of just seeing accuracy percentages, you can compare their
Decision PathsandFiles Exploredto understand how each approach tackles the problem, leading to a more informed decision on which architecture to pursue.Debugging Complex Failures: Your code generation agent occasionally produces incorrect output, but simple error logs aren't revealing the root cause. With BenchX, you can re-run the failing benchmark tasks and examine the detailed
Raw Execution Logsand the step-by-stepDecision Path. This detailed view helps you trace the agent's logic and identify the specific point of failure much faster than manual debugging.Ensuring Consistent Performance: Before deploying a new version of your customer support agent, you need to ensure it hasn't regressed on key capabilities. By integrating BenchX into your CI/CD pipeline via its API, you automatically run a core benchmark suite with every build. If performance metrics drop below a defined threshold compared to the previous
Versioned Experiment, the deployment can be automatically halted, preventing regressions from reaching production.
Conclusion
BenchX provides the structure and detailed insights necessary for systematic AI agent improvement. By facilitating controlled experiments, offering deep performance visibility beyond basic accuracy, and integrating with your development tools, BenchX helps you iterate faster and build more reliable, effective AI agents. Move from guesswork to data-driven decisions in your agent development process.
More information on BenchX
Launched
2024-10
Pricing Model
Contact for Pricing
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Next.js
BenchX was manually vetted by our editorial team and was first featured on 2025-04-08.
Related Searches
BenchX Alternatives
Load more Alternatives-

-

-

-

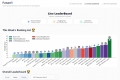
Choose the best AI agent for your needs with the Agent Leaderboard—unbiased, real-world performance insights across 14 benchmarks.
-