
What is Extractor API?
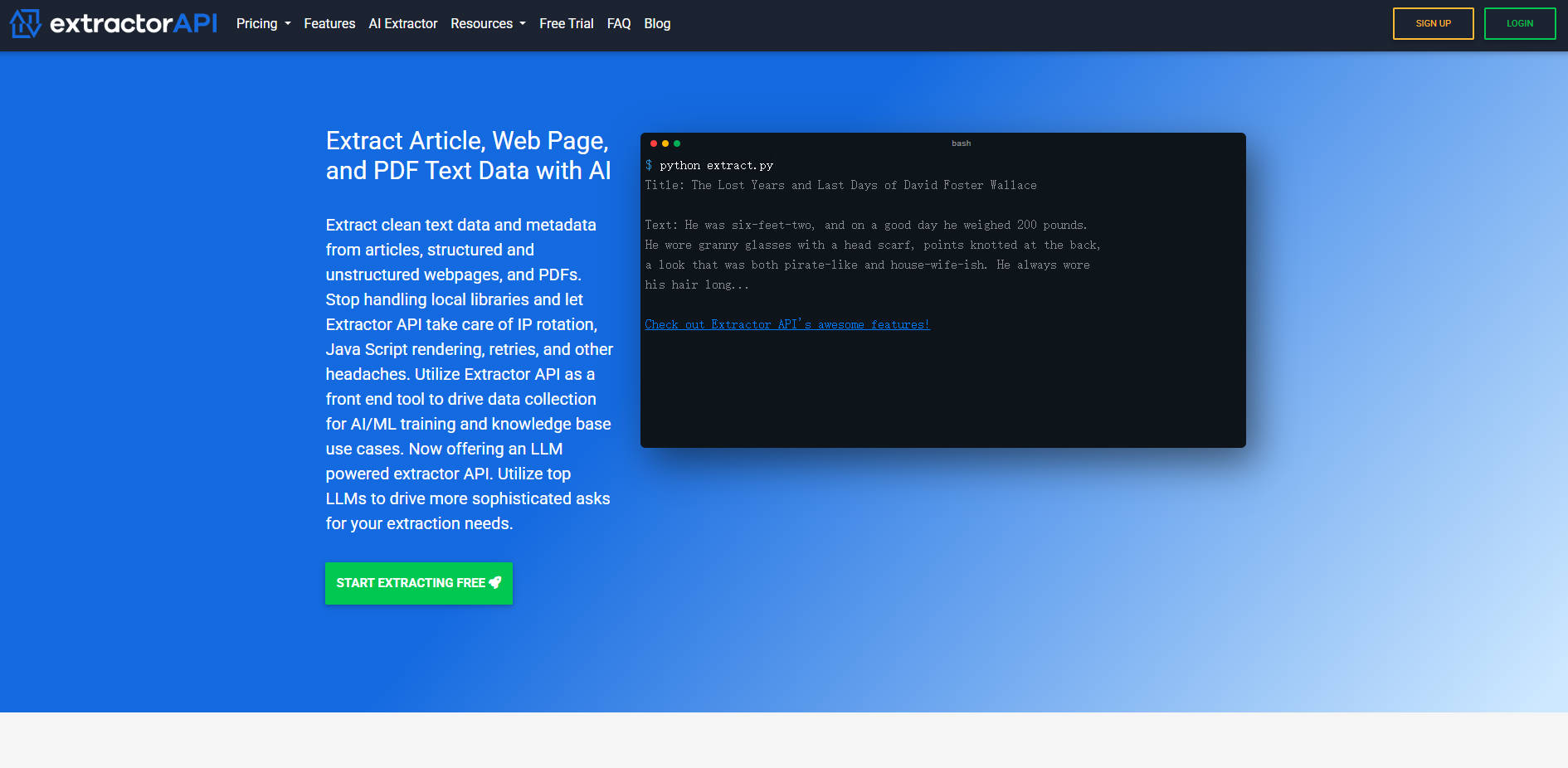
The Extractor API is a comprehensive, high-performance text extraction platform designed to simplify large-scale data collection. It addresses the inherent technical complexities of web scraping—such as managing IP rotation, retries, and dynamic JavaScript rendering—to deliver clean, structured text and valuable metadata from articles, structured/unstructured webpages, and PDFs. Data teams, AI/ML engineers, and knowledge base creators can rely on Extractor API to access previously inaccessible information efficiently and cost-effectively.
Key Features
🔌 Seamless Technical Resilience
You no longer need to manage complex infrastructure or local libraries. The Extractor API automatically handles common extraction pain points, including robust retries, continuous IP rotation, and necessary JavaScript rendering (available on paid tiers). This ensures high reliability and availability, allowing your team to focus solely on the data output, not the extraction mechanics.
🧠 LLM-Driven Sophisticated Extraction
Leverage the power of leading models, including OpenAI and Google LLMs, through the dedicated LLM-powered Extractor API. This capability moves beyond simple text parsing, enabling sophisticated extraction requirements, higher accuracy across diverse webpage formats, and the unique ability to "converse" with webpages via targeted prompts to pull nuanced information.
📄 Automated PDF Data Extraction
Easily integrate extraction workflows for both proprietary local documents and public-facing documents. This feature automates the process of pulling key datasets and clean text from unstructured PDFs, ensuring that valuable information locked within complex document formats can be quickly converted into usable data.
🔎 Global News Search API
Access the world’s news landscape with a single, dedicated API call. The News Search feature returns up to 100 relevant results per request, complete with essential metadata, providing a fast and efficient source for real-time or historical data streams crucial for market intelligence and trend analysis.
🖼️ Visual Extraction Tool for Rapid Deployment
For quick analysis or non-API workflows, the platform offers an intuitive online visual tool. Users can paste or upload up to 1,000 URLs at once for immediate text extraction, saving the resulting clean data to a persistent Jobs page for later retrieval in CSV or JSON format.
Use Cases
1. Fueling High-Quality AI/ML Training Data
Data teams utilize Extractor API as the critical first step in building reliable data pipelines. By collecting clean, structured text and metadata from thousands of sources, you ensure your downstream data warehouses and data lakes receive high-quality source material, driving more accurate training and better performance for your machine learning models.
2. Building Dynamic Knowledge Bases
Quickly and automatically ingest external information to build comprehensive knowledge bases. Use the PDF Data Extraction feature to pull key facts and figures from technical white papers, public reports, or documentation, ensuring your internal knowledge systems are perpetually up-to-date without manual data entry.
3. Targeted, Sophisticated Data QA
When standard extraction fails on complex, highly structured pages (like detailed product specifications or research summaries), the LLM-powered extractor provides the solution. By choosing a desired LLM and writing a precise prompt, you can interact with the webpage content programmatically, ensuring you only pull the exact, highly specific information required, even from complicated page structures.
Conclusion
The Extractor API delivers the necessary robustness and sophistication to transform complex web and document data into clean, actionable intelligence. By handling the technical prerequisites and offering cutting-edge AI tools, it ensures your data pipelines are reliable, efficient, and ready for advanced applications.
More information on Extractor API
Launched
2020-03
Pricing Model
Freemium
Starting Price
$33/ month
Global Rank
12055209
Follow
Month Visit
<5k
Tech used
Top 5 Countries
44.64%
36.93%
18.42%
India
France
United States
Traffic Sources
5.75%
1.47%
0.17%
9.98%
53.25%
29.08%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Nov 1, 2025)
Extractor API was manually vetted by our editorial team and was first featured on 2025-10-31.
Extractor API Alternatives
Load more Alternatives-

Parse Extract: Advanced data extraction & OCR for LLM pipelines. Transform complex documents & web data into clean, LLM-ready text. Cost-efficient & secure.
-

Effortlessly extract structured web data from any site using AI. No code needed! Define exactly what you need with prompts & schema.
-

Extract data from any unstructured document using Extracta.ai. Automatically parse scanned docs and retrieve the information that you need.
-

-

DocExtractor uses AI to extract data from unstructured documents accurately and quickly, saving time, minimizing errors, and enabling data-driven decisions. It processes various formats, integrates easily, and has multiple use cases in different industries.