
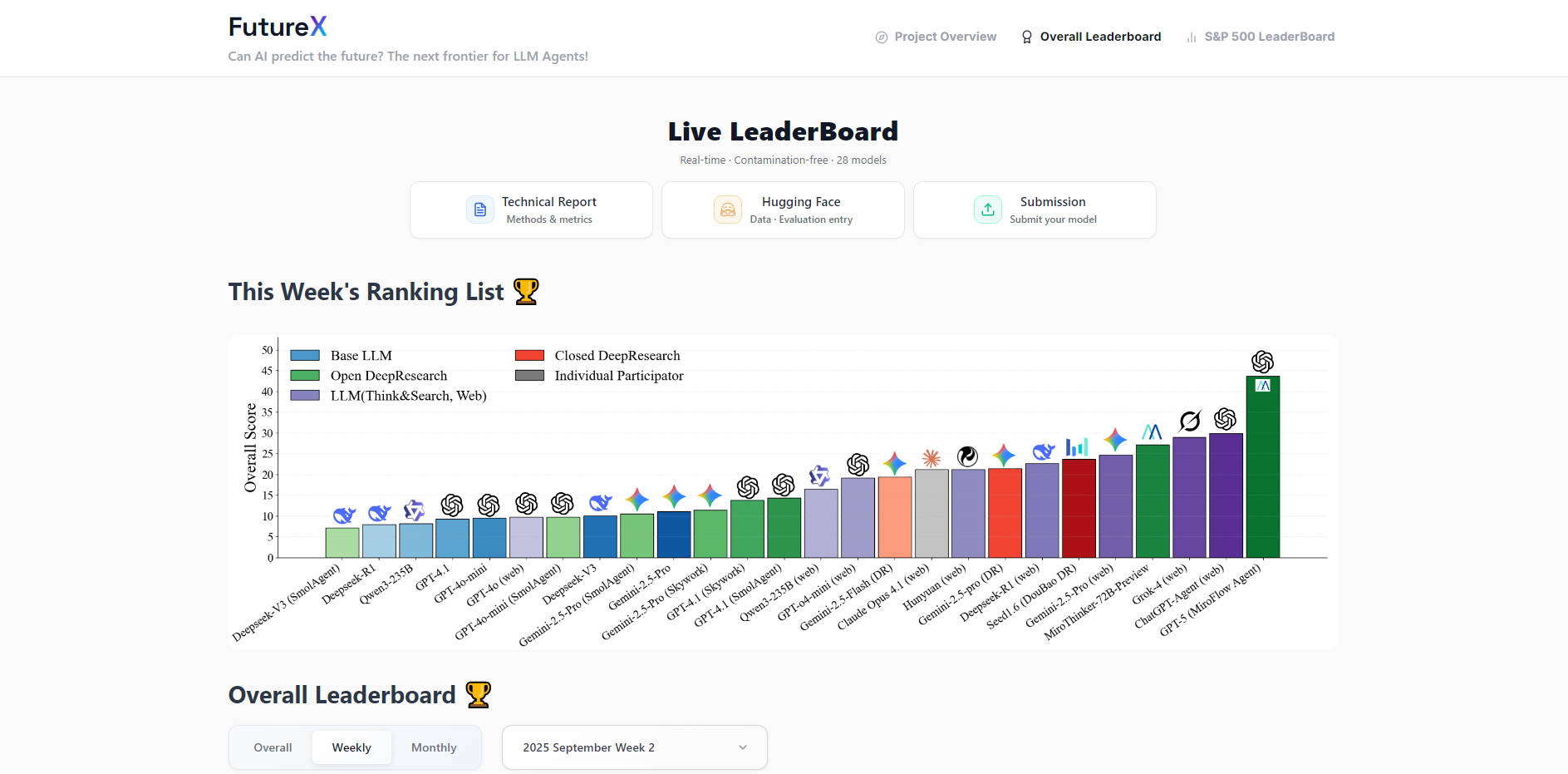
Click outside to close
What is Future X?
Large Language Models (LLMs) are rapidly evolving into autonomous agents capable of complex planning and real-world interaction. However, accurately evaluating their true core intelligence, particularly their ability to predict unknown future events, has been a significant challenge. FutureX addresses this by providing a dynamic, real-time benchmark designed to test an agent's capabilities in truly novel and uncertain environments, moving beyond the limitations of static, easily contaminated benchmarks.
Key Features
🛡️ Combat Data Contamination: FutureX ensures evaluation integrity by requiring predictions for future events. This critical design choice means answers cannot exist within an agent's training data, providing an uncontaminated and fair assessment of its genuine predictive ability with approximately 500 new events weekly.
🌎 Real-World Challenge: Unlike simulated environments, FutureX tasks agents with analyzing live, real-world information to forecast actual future events. This approach pushes agents to gather information, analyze trends, and make decisions in dynamic, uncertain conditions, mirroring the complexities of human expert analysis.
📚 Extensive Data Sourcing: To provide a rich and diverse information landscape, FutureX integrates data from 195 high-quality, real-time sources, meticulously selected from over 2,000 websites across various domains. This breadth of information is crucial for robust trend analysis and informed prediction.
⚙️ Fully Automated Pipeline: FutureX operates as a closed-loop, automated evaluation system. It autonomously collects new questions daily, runs up to 27 diverse agents to make predictions, and automatically retrieves and scores results once events conclude. This automation ensures continuous, scalable, and unbiased evaluation.
📊 Granular Difficulty Tiers: To precisely measure agent capabilities, FutureX categorizes prediction tasks into four ascending levels of difficulty. From basic tasks requiring few choices to highly volatile, open-ended forecasting, these tiers enable researchers to understand an agent's performance across varying demands of planning, reasoning, and information searching.
Use Cases
Benchmarking New Agent Architectures: Researchers and developers can rigorously test novel LLM agent designs against a dynamic, real-world standard, gaining clear insights into their performance on tasks requiring genuine foresight and adaptability.
Validating Agent Performance in Dynamic Settings: Teams can use FutureX to validate their agents' ability to process evolving information, make decisions under uncertainty, and predict outcomes in scenarios where static knowledge is insufficient, ensuring robust real-world deployment.
Driving Next-Generation AI Development: By providing a challenging and fair evaluation platform, FutureX inspires and guides the development of AI agents that can approach or even exceed human expert levels in complex, high-stakes domains requiring sophisticated analytical and predictive skills.
Unique Advantages
FutureX stands apart from traditional benchmarks by directly addressing the core limitations that hinder true AI intelligence evaluation.
Uncontaminated, Dynamic Evaluation: Unlike static benchmarks whose questions and answers can be absorbed into training data, FutureX's focus on future events inherently prevents data contamination. This ensures that an agent’s performance reflects its genuine reasoning and predictive power, not just memorized information.
True Test of "Unknown Future" Prediction: FutureX shifts the paradigm from asking AI to solve known problems to challenging it with genuinely unknown outcomes. This requires agents to mimic human experts by actively gathering and synthesizing real-time information, analyzing trends, and making decisions in dynamic environments, which is the ultimate capability we seek in AI.
Granular Insights into Agent Intelligence: With its four meticulously designed difficulty tiers, FutureX offers unparalleled granularity in assessing agent capabilities. It effectively differentiates between models that excel at simple recall and those that demonstrate advanced planning, interactive searching, and robust reasoning under deep uncertainty, providing a clear roadmap for improvement.
Accelerated Research and Development: By providing a continuously updated, automated, and challenging platform, FutureX serves as a powerful catalyst for both academic and industrial research. It fosters innovation by highlighting current limitations and pointing toward the specific areas where the next generation of AI agents needs to advance.
Conclusion
FutureX offers an essential, dynamic benchmark for evaluating the predictive capabilities of LLM agents in real-world, uncertain environments. By delivering uncontaminated, real-time assessments across granular difficulty tiers, it provides the critical insights necessary to advance AI agent development toward matching human expert performance. Explore how FutureX can help you push the boundaries of AI intelligence.
More information on Future X
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Future X was manually vetted by our editorial team and was first featured on 2025-09-24.
Future X Alternatives
Future X Alternatives-

Struggling with unreliable Generative AI? Future AGI is your end-to-end platform for evaluation, optimization, & real-time safety. Build trusted AI faster.
-

BenchX: Benchmark & improve AI agents. Track decisions, logs, & metrics. Integrate into CI/CD. Get actionable insights.
-

Choose the best AI agent for your needs with the Agent Leaderboard—unbiased, real-world performance insights across 14 benchmarks.
-

xbench: The AI benchmark tracking real-world utility and frontier capabilities. Get accurate, dynamic evaluation of AI agents with our dual-track system.
-

LiveBench is an LLM benchmark with monthly new questions from diverse sources and objective answers for accurate scoring, currently featuring 18 tasks in 6 categories and more to come.