What is BenchX?
開發複雜的 AI 代理程式帶來獨特的挑戰,尤其是在真正理解和改善其效能方面。超越簡單的通過/失敗指標,對於構建可靠且準確的系統至關重要。BenchX 提供了一個專用的平台,幫助您嚴格評估和迭代您的 AI 代理程式。透過啟用受控實驗並提供深入、可操作的洞見,BenchX 協助您加速開發週期,並根據可靠的數據構建更有效的 AI 應用程式。
主要特色
📊 捕捉詳細的執行洞見: 超越表面層次的結果。BenchX 允許您記錄代理程式採取的具體步驟 (
Decision Path)、其存取的資料 (Files Explored),並將其輸出與預期結果直接比較 (Your Output vs Expected Output)。對於深入研究,Raw Execution Logs始終可用。這些細微的資料有助於精確定位您的代理程式成功或失敗的地點和原因。📈 解鎖進階效能指標: 擺脫單一的準確度分數。BenchX 提供更豐富的指標和視覺化效果,從而提供代理程式行為的全面視圖。這有助於進行更細緻的分析,協助您發現細微的問題並以更高的精度微調效能。
🏷️ 使用版本控制實驗進行組織: 保持開發過程的結構化。BenchX 自動追蹤和組織您的實驗歷史記錄,將每個報告直接連結到特定版本的實驗程式碼。這確保了可重現性,並可以輕鬆比較各個迭代的效能,而不會遺失寶貴的洞見。
⚙️ 執行可靠、隔離的測試: 專注於您的代理程式邏輯,而不是基礎設施設定。您在 Docker 映像中提供任務處理程式碼;BenchX 管理其餘部分,在隔離的容器中將基準測試任務饋送到您的程式碼。這確保了一致且受控的執行環境,以獲得可靠的結果。
🔄 無縫整合到工作流程中: 自動化您的評估流程。BenchX 提供了一個公共 API,允許您將基準測試直接整合到您的 CI/CD 管道中。這可以在標準開發生命週期中實現持續測試和效能追蹤。
使用案例
比較代理程式架構: 您已經為一個任務開發了兩種不同的方法,例如文件摘要。使用 BenchX,您可以針對同一個基準資料集執行這兩個代理程式版本。您不僅可以看到準確度百分比,還可以比較它們的
Decision Paths和Files Explored,以了解每種方法如何處理問題,從而針對要採用哪種架構做出更明智的決策。偵錯複雜的失敗: 您的程式碼生成代理程式偶爾會產生不正確的輸出,但簡單的錯誤日誌無法揭示根本原因。借助 BenchX,您可以重新執行失敗的基準測試任務,並檢查詳細的
Raw Execution Logs和逐步的Decision Path。這種詳細的視圖可協助您追蹤代理程式的邏輯,並比手動偵錯更快地識別出具體的失敗點。確保一致的效能: 在部署新版本的客戶支援代理程式之前,您需要確保它沒有在關鍵功能上退步。透過透過其 API 將 BenchX 整合到您的 CI/CD 管道中,您可以自動對每個建置執行核心基準測試套件。如果效能指標低於先前
Versioned Experiment的定義閾值,則可以自動停止部署,從而防止退步影響生產環境。
結論
BenchX 提供了系統化 AI 代理程式改進所需的結構和詳細洞見。透過促進受控實驗、提供超越基本準確度的深入效能可見性,以及與您的開發工具整合,BenchX 可協助您更快地迭代並構建更可靠、更有效的 AI 代理程式。在您的代理程式開發過程中,從猜測轉向數據驅動的決策。
More information on BenchX
Launched
2024-10
Pricing Model
Contact for Pricing
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Next.js,Gzip,OpenGraph,Webpack
BenchX was manually vetted by our editorial team and was first featured on 2025-04-08.
Related Searches
BenchX 替代方案
更多 替代方案-

-

-

-

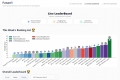
透過 Agent Leaderboard 選擇最符合您需求的 AI 代理程式——此排行榜提供橫跨 14 項基準的公正、真實效能見解。
-