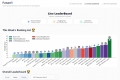
What is BenchX?
开发复杂的 AI 智能体面临着独特的挑战,尤其是在真正理解和提升其性能方面。要构建可靠且准确的系统,仅仅依靠简单的通过/失败指标是远远不够的。BenchX 提供了一个专门的平台,帮助您严格评估和迭代您的 AI 智能体。通过支持受控实验并提供深入、可操作的见解,BenchX 帮助您加速开发周期,并基于可靠的数据构建更有效的 AI 应用程序。
主要特性
📊 捕获详细的执行洞察: 超越表面层面的结果。BenchX 允许您记录智能体采取的具体步骤 (
Decision Path,决策路径),它访问的数据 (Files Explored,文件浏览),并将它的输出与预期的结果直接进行比较 (Your Output vs Expected Output,您的输出 vs 预期输出)。对于深入分析,始终可以获取Raw Execution Logs(原始执行日志)。这种细粒度的数据有助于精确定位您的智能体成功或失败的确切位置和原因。📈 解锁高级性能指标: 不再局限于单一的准确率分数。BenchX 提供了一组更丰富的指标和可视化,从而能够全面了解您的智能体的行为。这有助于进行更细致的分析,帮助您发现细微的问题,并以更高的精度微调性能。
🏷️ 使用版本化实验进行组织: 保持开发流程的结构化。BenchX 自动跟踪和组织您的实验历史记录,将每个报告直接链接到特定版本的实验代码。这确保了可重复性,并可以轻松地比较不同迭代的性能,而不会丢失有价值的见解。
⚙️ 运行可靠、隔离的测试: 专注于智能体的逻辑,而不是基础设施设置。您在 Docker 镜像中提供任务处理代码;BenchX 管理其余的部分,在隔离的容器中将基准测试任务馈送到您的代码中。这确保了一致且受控的执行环境,从而获得可靠的结果。
🔄 无缝集成到工作流程中: 自动化您的评估过程。BenchX 提供了一个公共 API,允许您将基准测试运行直接整合到您的 CI/CD 管道中。这使得能够进行持续测试和性能跟踪,作为标准开发生命周期的一部分。
使用案例
比较智能体架构: 您为一项任务开发了两种不同的方法,例如文档摘要。使用 BenchX,您可以针对相同的基准数据集运行两个智能体版本。除了查看准确率百分比之外,您还可以比较它们的
Decision Paths(决策路径)和Files Explored(文件浏览)以了解每种方法如何解决问题,从而对要采用哪种架构做出更明智的决定。调试复杂故障: 您的代码生成智能体会偶尔产生不正确的输出,但简单的错误日志无法揭示根本原因。使用 BenchX,您可以重新运行失败的基准测试任务,并检查详细的
Raw Execution Logs(原始执行日志)和逐步的Decision Path(决策路径)。这种详细的视图可帮助您跟踪智能体的逻辑,并比手动调试更快地识别出具体的故障点。确保一致的性能: 在部署新版本的客户支持智能体之前,您需要确保它没有在关键功能上出现退化。通过通过 API 将 BenchX 集成到您的 CI/CD 管道中,您可以自动对每个构建运行核心基准测试套件。如果与之前的
Versioned Experiment(版本化实验)相比,性能指标低于定义的阈值,则可以自动停止部署,防止退化影响到生产环境。
结论
BenchX 提供了系统性地改进 AI 智能体所需的结构和详细的见解。通过促进受控实验、提供超越基本准确率的深入性能可见性,以及与您的开发工具集成,BenchX 帮助您更快地迭代并构建更可靠、更有效的 AI 智能体。在您的智能体开发过程中,将猜测转变为数据驱动的决策。
More information on BenchX
Launched
2024-10
Pricing Model
Contact for Pricing
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Next.js,Gzip,OpenGraph,Webpack
BenchX was manually vetted by our editorial team and was first featured on 2025-04-08.
Related Searches
BenchX 替代方案
更多 替代方案-

-

-

-

借助 Agent Leaderboard,选择最适合您需求的 AI 智能体——它提供跨 14 项基准的公正、真实的性能洞察。
-