
What is AudioFlux?
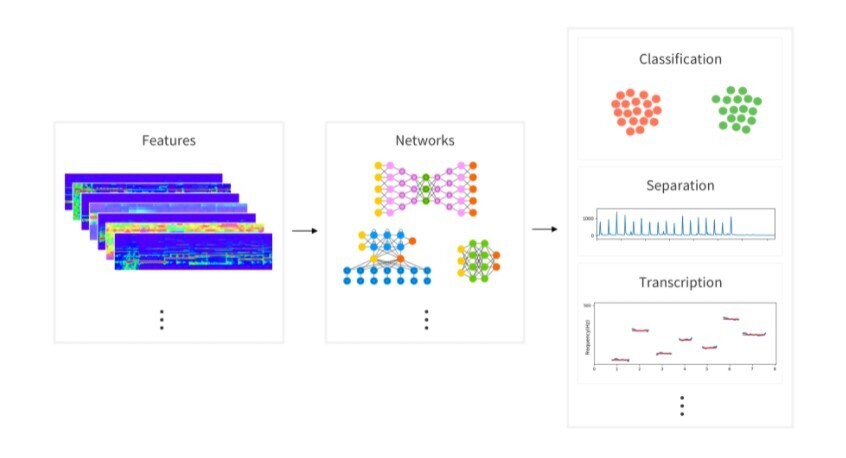
AudioFlux es una herramienta integral de extracción y combinación de características de audio diseñada para diversas tareas relacionadas con el audio, incluida la clasificación de audio, la mejora del habla, la separación de audio/música, la recuperación de información musical y el reconocimiento automático del habla. Ofrece capacidades sistemáticas de extracción y combinación de características multidimensionales, junto con modelos de red de aprendizaje profundo para facilitar la investigación y el desarrollo en diversos campos de audio.
Características principales:
1️⃣ Procesamiento de datos eficiente:?
-
Los módulos de algoritmo desacoplados permiten una extracción rápida y eficiente de características de grandes conjuntos de datos, lo que agiliza el flujo de trabajo para el análisis e investigación de audio.
2️⃣ Extracción de características multidimensionales:?
-
Proporciona una amplia gama de características de audio, incluidos el espectrograma mel y las características MFCC, que se adaptan a diferentes tareas de procesamiento de audio.
3️⃣ Integración de aprendizaje profundo:?
-
Incorpora varios modelos de red de aprendizaje profundo para aprovechar el poder de las redes neuronales para la extracción de características, lo que permite resultados de alta precisión.
Casos de uso:
1️⃣ Clasificación de audio:?
-
Clasifica las señales de audio en categorías predefinidas, como género musical, identificación del hablante y reconocimiento de sonido ambiental.
2️⃣ Mejora del habla:?️
-
Mejora la calidad de las señales de voz eliminando el ruido de fondo y mejorando la claridad, haciéndolas adecuadas para aplicaciones como el reconocimiento y la comunicación de voz.
3️⃣ Recuperación de información musical:?
-
Extrae características de la música para facilitar la búsqueda, recomendación y análisis de música, lo que permite una organización y descubrimiento eficientes del contenido musical.
Conclusión:
AudioFlux se destaca como una poderosa herramienta para la extracción y combinación de características de audio, que permite a los investigadores y desarrolladores aprovechar los modelos de aprendizaje profundo para diversas tareas de audio. Sus características integrales y su interfaz fácil de usar lo convierten en un recurso valioso para avanzar en la investigación y el desarrollo relacionados con el audio. Con su capacidad para extraer información significativa de los datos de audio, AudioFlux tiene el potencial de impulsar la innovación y mejorar el rendimiento en una amplia gama de aplicaciones de audio.
More information on AudioFlux
Launched
2022-05
Pricing Model
Free
Starting Price
Global Rank
34774623
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,Sphinx,jQuery,Pygments,Underscore.js,HSTS,Nginx
Top 5 Countries
100%
United States
Traffic Sources
7.01%
0.78%
0.05%
15.14%
31.63%
45.4%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
AudioFlux was manually vetted by our editorial team and was first featured on 2023-03-27.
Related Searches
AudioFlux Alternativas
Más Alternativas-

Flux.1 AI Image Generator de BlackForestLabs convierte texto en imágenes de alta calidad. Con modelos avanzados de hasta 12 000 millones de parámetros, ofrece salida de alta resolución y compatibilidad con múltiples plataformas. Ideal para profesionales, desarrolladores y uso personal.
-

-

-

Audiocraft es una biblioteca para procesamiento y generación de audio con aprendizaje profundo. Cuenta con el estado
-

Aero-1-Audio: Modelo eficiente de 1.500 millones de parámetros para el procesamiento continuo de audio de hasta 15 minutos. Reconocimiento automático del habla (ASR) y comprensión precisos sin necesidad de segmentación. ¡De código abierto!