
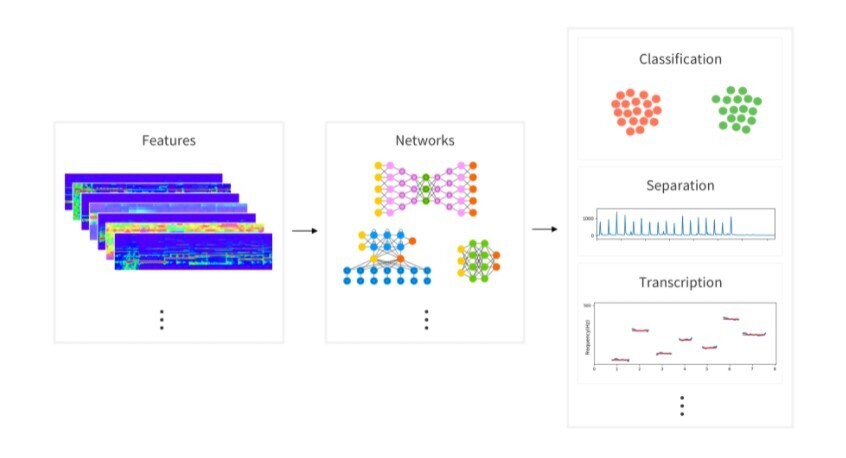
What is AudioFlux?
AudioFluxは、オーディオ分類、音声強調、オーディオ/音楽の分離、音楽情報検索、自動音声認識など、さまざまなオーディオ関連タスク向けに設計された包括的なオーディオ機能抽出および組み合わせツールです。多角的な特徴抽出と組み合わせ機能、およびディープラーニングネットワークモデルを提供し、多様なオーディオ分野の研究開発を促進します。
主な特徴:
1️⃣ 効率的なデータ処理:?
アルゴリズムモジュールが分離されているため、大規模なデータセットから高速かつ効率的に特徴を抽出でき、オーディオ分析や研究のためのワークフローが合理化されます。
2️⃣ 多角的な特徴抽出:?
メルスペクトログラムやMFCC特徴など、さまざまなオーディオ特徴を提供し、さまざまなオーディオ処理タスクに対応します。
3️⃣ ディープラーニングの統合:?
さまざまなディープラーニングネットワークモデルを組み込み、ニューラルネットワークの力を活用して特徴を抽出し、高精度の結果を実現します。
ユースケース:
1️⃣ オーディオ分類:?
音楽のジャンル、話者の識別、環境音の認識など、定義済みのカテゴリにオーディオ信号を分類します。
2️⃣ 音声強調:?️
バックグラウンドノイズを除去して明瞭度を高めることで音声信号の品質を向上させ、音声認識やコミュニケーションなどのアプリケーションに適しています。
3️⃣ 音楽情報検索:?
音楽から特徴を抽出して、音楽検索、レコメンデーション、分析を容易にし、音楽コンテンツの効率的な整理と発見を可能にします。
結論:
AudioFluxは、研究者や開発者がさまざまなオーディオタスクでディープラーニングモデルを活用できるようにする、強力なオーディオ機能抽出および組み合わせツールとして際立っています。その包括的な機能とユーザーフレンドリーなインターフェースは、オーディオ関連の研究開発を進める上で貴重なリソースです。AudioFluxは、オーディオデータから有意義な洞察を抽出する能力を備えており、さまざまなオーディオアプリケーションで革新を促進し、性能を向上させる可能性を秘めています。
More information on AudioFlux
Launched
2022-05
Pricing Model
Free
Starting Price
Global Rank
34774623
Follow
Month Visit
<5k
Tech used
Google Analytics,Google Tag Manager,Sphinx,jQuery,Pygments,Underscore.js,HSTS,Nginx
Top 5 Countries
100%
United States
Traffic Sources
7.01%
0.78%
0.05%
15.14%
31.63%
45.4%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
AudioFlux was manually vetted by our editorial team and was first featured on 2023-03-27.
Related Searches
AudioFlux 代替ソフト
もっと見る 代替ソフト-

-

-

-

-

Aero-1-Audio:15分間の連続した音声処理に最適化された、効率的な15億パラメータモデル。セグメンテーションなしで、高精度なASR(自動音声認識)と理解を実現。オープンソースで公開!