
What is FastRouter.ai?
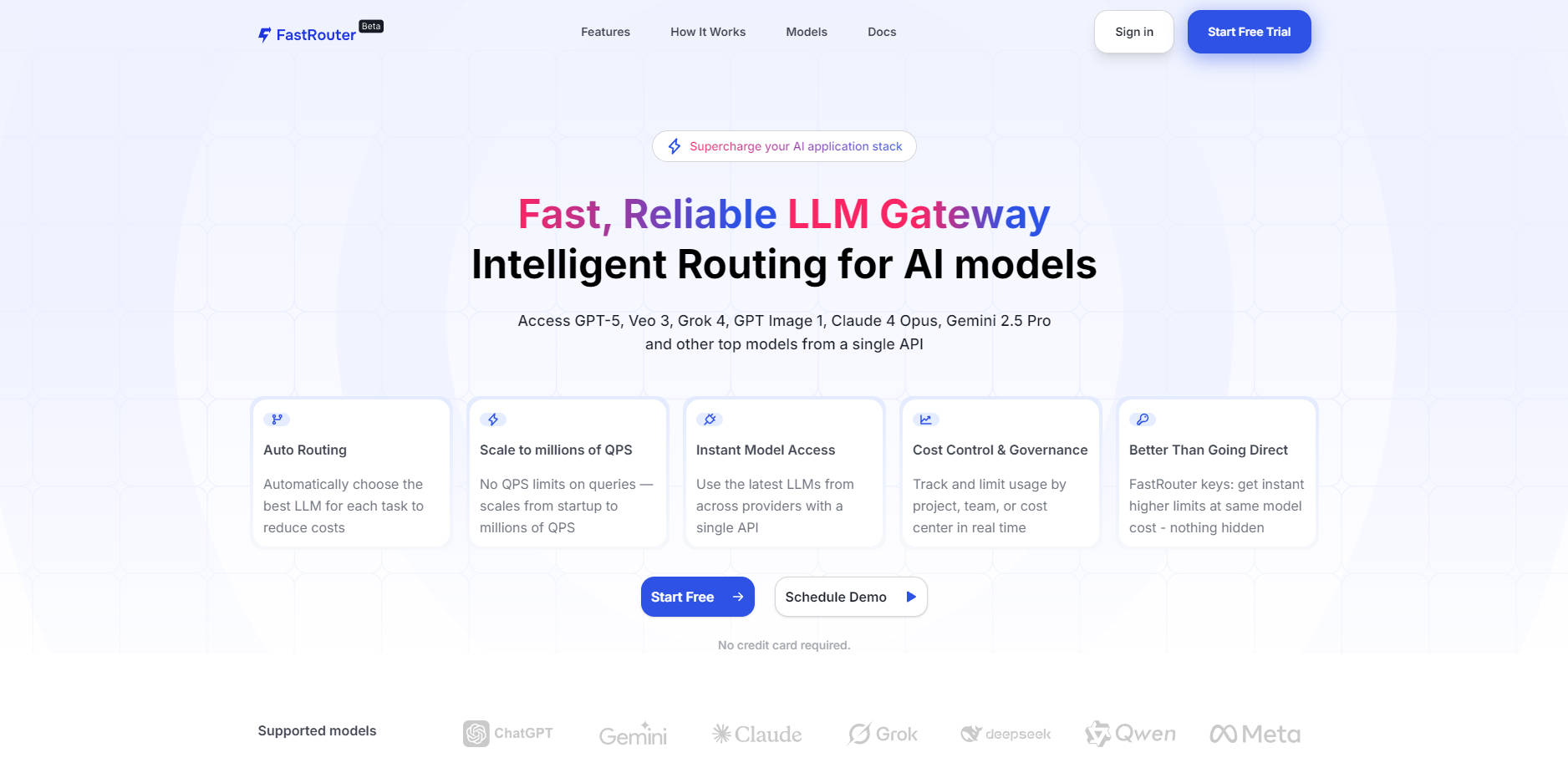
FastRouter.ai is the intelligent infrastructure layer designed to simplify, optimize, and scale your production AI applications. It solves the critical challenges of managing complexity, ensuring reliability, and controlling costs across a multi-provider Large Language Model (LLM) environment. By offering a single, unified API compatible with OpenAI, FastRouter empowers developers and engineering leaders to instantly access the best models from GPT, Claude, Gemini, Grok, and over 100 others without complex code refactoring or vendor lock-in.
Key Features
FastRouter provides the necessary intelligence and infrastructure for building and deploying robust, cost-efficient AI applications at any scale.
🚀 Intelligent Smart Routing
Dynamically evaluate every request based on cost, latency, and required output quality. FastRouter automatically routes the call to the optimal model endpoint in real-time, ensuring you maximize performance while minimizing expenses—all with zero manual oversight required.
🔗 Unified API for 100+ Models
Connect seamlessly to a vast ecosystem of leading text, image, and audio models (including GPT-5, Veo 3, Claude 4 Opus, and more) through a single, OpenAI-compatible endpoint. This drop-in replacement eliminates the need to manage multiple SDKs, instantly simplifying your integration and allowing you to utilize the latest AI technology instantly.
🛡️ Instant Failover & High Availability (InstaSwitch)
Ensure uninterrupted service for your users. FastRouter continuously monitors provider endpoints for outages, rate limits, and degradation. If an issue is detected, the system automatically switches the request to a healthy, available endpoint, guaranteeing high availability and reliability for your mission-critical applications.
💰 Real-Time Cost Control & Smart Budgeting
Gain granular financial governance over your AI usage. Define specific budgets, set rate limits, and manage model permissions per project, team, or API key. The platform provides real-time visibility into tokens consumed and costs incurred, allowing you to identify spikes and automate routing to cheaper models when quality requirements permit.
📈 Built for Hyperscale
Scale effortlessly from initial development to enterprise-level demand without platform switching or QPS limitations. FastRouter is engineered to handle massive throughput, easily managing over one million queries per second (1M+ QPS), providing the stability required for rapid growth.
Use Cases
FastRouter.ai translates infrastructure complexity into actionable business benefits across various roles:
| User Scenario | Challenge Solved | Tangible Outcome |
|---|---|---|
| Engineering Leaders | Mitigating reliability risks and escalating AI infrastructure costs. | Reduce Risk & Cost: Automatically cut AI spending by leveraging dynamic routing to cheaper, high-quality models, while instant failover ensures enterprise-grade reliability and security. |
| Developers | Slow integration processes and managing multiple provider APIs/SDKs. | Accelerate Deployment: Use a single API key and simply replace your base URL. This drop-in replacement for the OpenAI API enables instant benefits (routing, failover) with zero code changes, allowing you to ship features faster. |
| Product Teams | Delivering consistent quality and response times to end-users. | Enhance User Experience: Ensure your product always uses the optimal model for the task, resulting in faster response times, predictable costs, and consistently high-quality outputs, regardless of underlying provider fluctuations. |
Why Choose FastRouter.ai?
FastRouter is designed to be inherently better than going direct to individual LLM providers by providing an essential optimization layer that delivers measurable improvements in efficiency and governance.
Instant Access to Higher Limits: Start leveraging higher API rate limits immediately through FastRouter keys at the same underlying model cost, avoiding the typical onboarding friction and delay associated with obtaining enterprise limits directly from providers.
True Zero-Code Failover: Unlike custom failover implementations that require development and maintenance, FastRouter monitors and switches endpoints automatically and instantly, providing a complete, managed high-availability solution out of the box.
Optimized Performance by Default: FastRouter’s Intelligent Routing is continuously evaluating latency and cost, meaning your application is inherently running more efficiently than one relying on a static, single-provider endpoint. You gain up to a 70% potential reduction in AI spending while improving overall system reliability.
Conclusion
FastRouter.ai provides the crucial intelligence and infrastructure required to move AI applications from proof-of-concept to highly reliable, cost-efficient production scale. By unifying model access, automating optimization, and guaranteeing high availability, FastRouter allows your teams to focus purely on innovation rather than infrastructure management.
More information on FastRouter.ai
Launched
2025-03
Pricing Model
Free Trial
Starting Price
Global Rank
13018322
Follow
Month Visit
<5k
Tech used
Top 5 Countries
90.49%
9.51%
United States
United Kingdom
Traffic Sources
0.43%
0.13%
0.02%
1.31%
4.12%
93.87%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Oct 29, 2025)
FastRouter.ai was manually vetted by our editorial team and was first featured on 2025-10-29.
FastRouter.ai Alternatives
Load more Alternatives-

ModelPilot unifies 30+ LLMs via one API. Intelligently optimize cost, speed, quality & carbon for every request. Eliminate vendor lock-in & save.
-

-

Stop overpaying & fearing AI outages. MakeHub's universal API intelligently routes requests for peak speed, lowest cost, and instant reliability across providers.
-

-

Helicone AI Gateway: Unify & optimize your LLM APIs for production. Boost performance, cut costs, ensure reliability with intelligent routing & caching.