What is Helicone AI Gateway?
Helicone AI Gateway is a high-performance, open-source routing layer designed for developers building with Large Language Models (LLMs). It acts as a single, unified endpoint for all your AI providers, simplifying integration, optimizing performance, and giving you precise control over costs and reliability. Think of it as the NGINX for LLMs—a fast, lightweight, and essential tool for production-grade AI applications.
Key Features
🌐 Unified API for 100+ Models Use the familiar OpenAI SDK syntax to interact with over 20 providers, including Anthropic, Google, AWS Bedrock, and more. You can switch between models like
gpt-4o-miniandclaude-3-5-sonnetwith a single line change, eliminating the need to learn and maintain separate integrations for each provider.⚡ Intelligent Routing & Load Balancing Automatically route requests to the optimal model or provider based on your defined strategy. Whether you need the absolute fastest response time, the lowest cost, or the highest reliability, the gateway’s built-in strategies (like latency-based routing and cost optimization) make smart decisions in real-time.
💰 Granular Cost & Usage Control Prevent runaway costs and usage abuse with powerful, easy-to-configure rate limiting. You can set precise limits based on request counts, token usage, or dollar amounts—globally, per-user, or per-team—to ensure your application stays within budget.
🚀 High-Performance Caching Dramatically reduce latency and API costs by caching responses for repeated queries. With support for Redis and S3 backends, Helicone AI Gateway can serve cached results in milliseconds, improving user experience and cutting expenses by up to 95% for common requests.
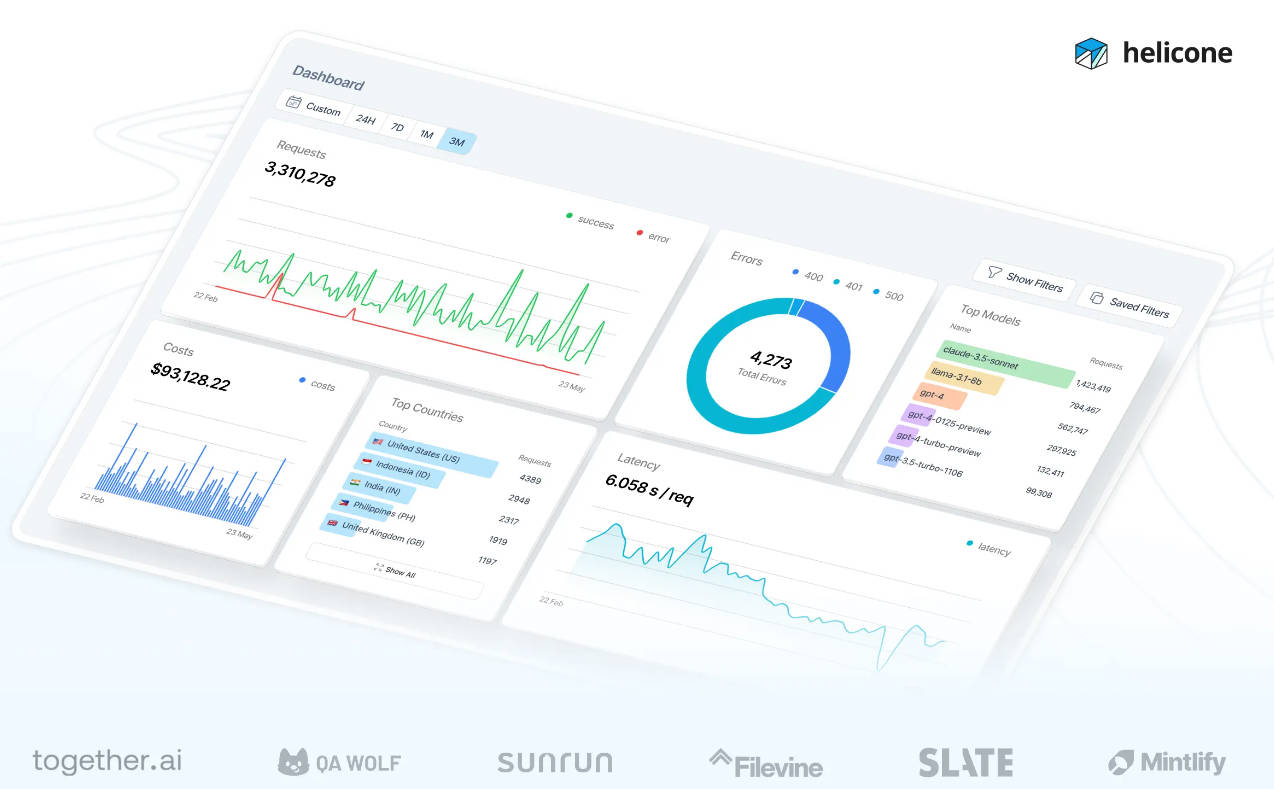
📊 Seamless Observability Gain deep insights into your LLM usage and performance with out-of-the-box integration with the Helicone observability platform. The gateway also supports OpenTelemetry, allowing you to export logs, metrics, and traces to your existing monitoring tools for unified debugging.
Use Cases
Build Fault-Tolerant AI Features: If your primary LLM provider (e.g., OpenAI) experiences an outage, you can configure the gateway to automatically failover to a secondary provider (e.g., Anthropic or Google). This ensures your application remains available and your users experience no disruption.
Optimize a Cost-Sensitive Chatbot: For an internal support bot, you can create a routing rule that sends simple, informational queries to a fast, inexpensive model. For complex, analytical queries, the gateway can automatically route to a more powerful and capable model, ensuring you only pay for high performance when you truly need it.
Scale a Public-Facing Application: When launching a new AI-powered feature, use caching to handle high volumes of common requests instantly and apply rate limits to individual users. This protects your application from abuse, ensures fair usage, and keeps your operational costs predictable as you scale.
Conclusion
Helicone AI Gateway provides the critical infrastructure needed to build, scale, and optimize LLM applications with confidence. By abstracting away the complexity of managing multiple AI providers, it empowers you to focus on creating value for your users while ensuring your application is fast, reliable, and cost-effective.
Explore the open-source repository or get started in seconds with the cloud-hosted version to take control of your AI integrations today.
More information on Helicone AI Gateway
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Helicone AI Gateway was manually vetted by our editorial team and was first featured on 2025-08-18.
Related Searches
Helicone AI Gateway Alternatives
Load more Alternatives-
LLM Gateway: Unify & optimize multi-provider LLM APIs. Route intelligently, track costs, and boost performance for OpenAI, Anthropic & more. Open-source.
-

Envoy AI Gateway is an open source project for using Envoy Gateway to handle request traffic from application clients to Generative AI services.
-

-
Experience the power of Portkey's AI Gateway - a game-changing tool for seamless integration of AI models into your app. Boost performance, load balancing, and reliability for resilient and efficient AI-powered applications.
-