
What is PDFMerse?
PDFMerse, un outil révolutionnaire alimenté par l'IA, simplifie la conversion de données PDF statiques en formats structurés et exploitables tels que JSON, CSV et Excel avec une précision exceptionnelle. Cette plateforme révolutionne les flux de travail de documents, automatisant l'extraction d'informations à partir de fichiers complexes, y compris le texte manuscrit, et offrant un support multilingue, rendant le traitement des données plus rapide, plus rentable et sans erreur.
Fonctionnalités clés:
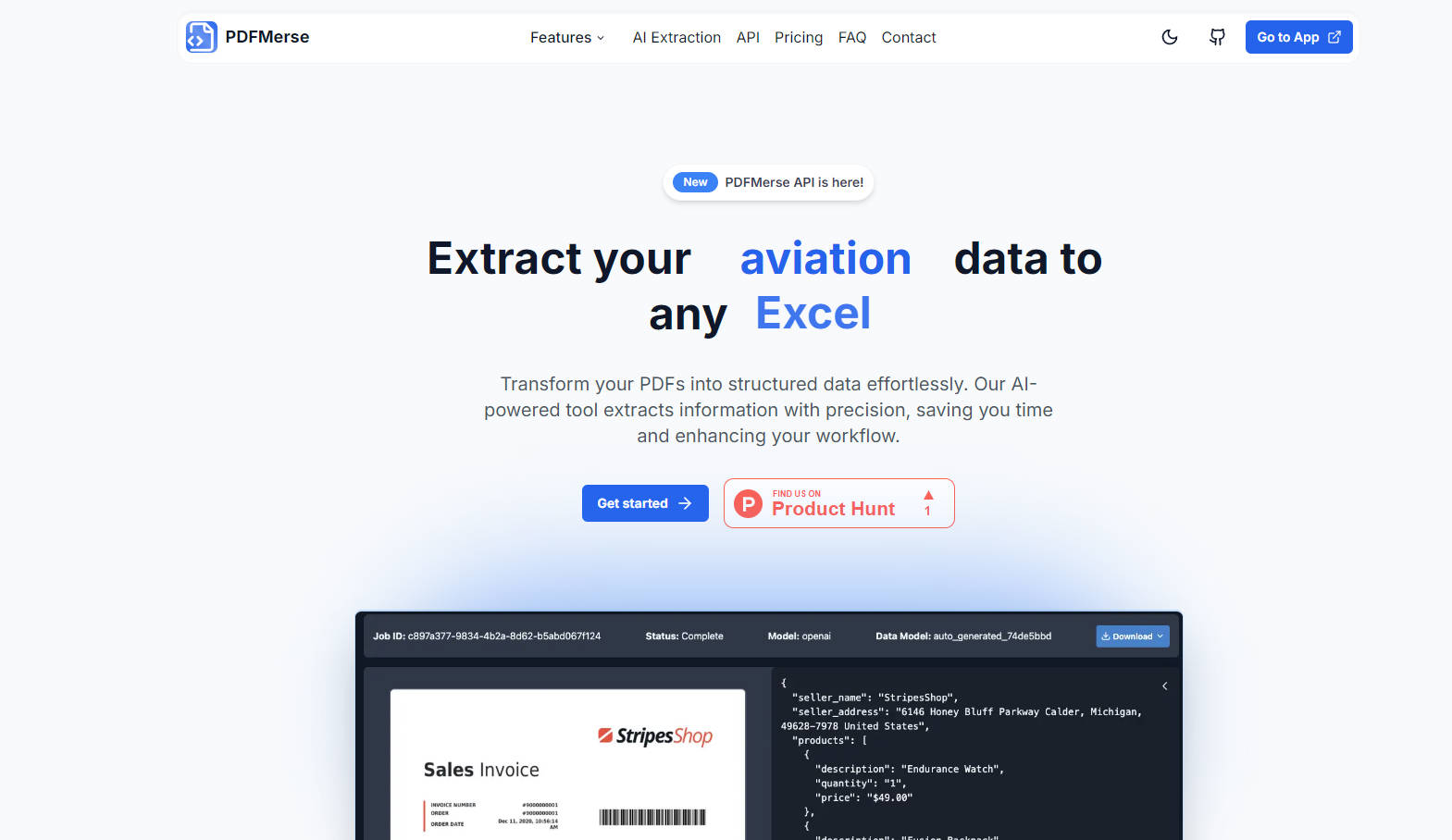
Extraction de données automatisée: PDFMerse automatise l'extraction de données à partir de divers documents PDF, éliminant des heures de travail manuel.
Garantie de données structurées: Les données extraites sont toujours structurées et formatées pour une intégration facile dans vos systèmes.
Extrêmement précis et intégrant la validation: La validation intégrée garantit la précision et la cohérence des données, réduisant considérablement les erreurs.
API RESTful pour une intégration transparente: Intégrez les puissantes fonctionnalités d'extraction de PDFMerse dans vos applications avec une API simple et performante.
Modèles de données personnalisés: Décrivez les données que vous devez extraire, et notre IA génère le modèle, simplifiant les tâches d'extraction complexes.
Cas d'utilisation:
Entreprises traitant des factures: Extrayez automatiquement les détails des factures, économisez des heures de saisie manuelle et minimisez les erreurs.
Établissements médicaux gérant les dossiers des patients: Rationalisez la gestion des données des patients en extrayant les données des dossiers médicaux dans des formats structurés pour un stockage électronique plus facile.
Cabinets d'avocats organisant des documents: Organisez et extrayez rapidement des informations critiques à partir de divers documents juridiques, améliorant l'efficacité et la qualité du service client.
Conclusion:
PDFMerse offre une efficacité et une précision inégalées en matière d'extraction de données, transformant les PDF statiques en actifs dynamiques. Optimisez votre flux de travail, gagnez du temps et réduisez les coûts avec notre solution basée sur l'IA conçue pour gérer vos données de documents avec précision. Essayez PDFMerse dès aujourd'hui et libérez tout le potentiel de vos données PDF.
FAQ:
Quels types de PDF PDFMerse prend-il en charge? PDFMerse prend en charge une large gamme de types de PDF, y compris des documents complexes comme les factures, les dossiers médicaux, les dossiers juridiques, etc. Il gère les formats structurés et non structurés, avec une compétence notable en reconnaissance de texte manuscrit.
Quel niveau de précision puis-je attendre de l'extraction de données? La précision de l'extraction dépasse généralement 95%, bien que cela puisse varier en fonction de la qualité et de la complexité du PDF. Les modèles d'IA de PDFMerse sont continuellement affinés pour améliorer la précision dans diverses catégories de documents.
Puis-je intégrer les capacités d'extraction de PDFMerse dans mes propres applications? Absolument! Notre API RESTful offre une méthode efficace pour automatiser l'extraction de données PDF dans vos applications, fournissant des formats de sortie structurés qui s'intègrent facilement à vos systèmes.
More information on PDFMerse
Launched
2024-06
Pricing Model
Freemium
Starting Price
$5 /month
Global Rank
Follow
Month Visit
<5k
Tech used
Cloudflare CDN,Next.js,Gzip,OpenGraph,Webpack
PDFMerse was manually vetted by our editorial team and was first featured on 2024-08-17.
Related Searches
PDFMerse Alternatives
Plus Alternatives-

-

-

Parse Extract : Extraction de données avancée et OCR pour les pipelines de LLM. Transformez des documents complexes et des données web en un texte épuré et optimisé pour les LLM. Rentable et sécurisé.
-
-
