
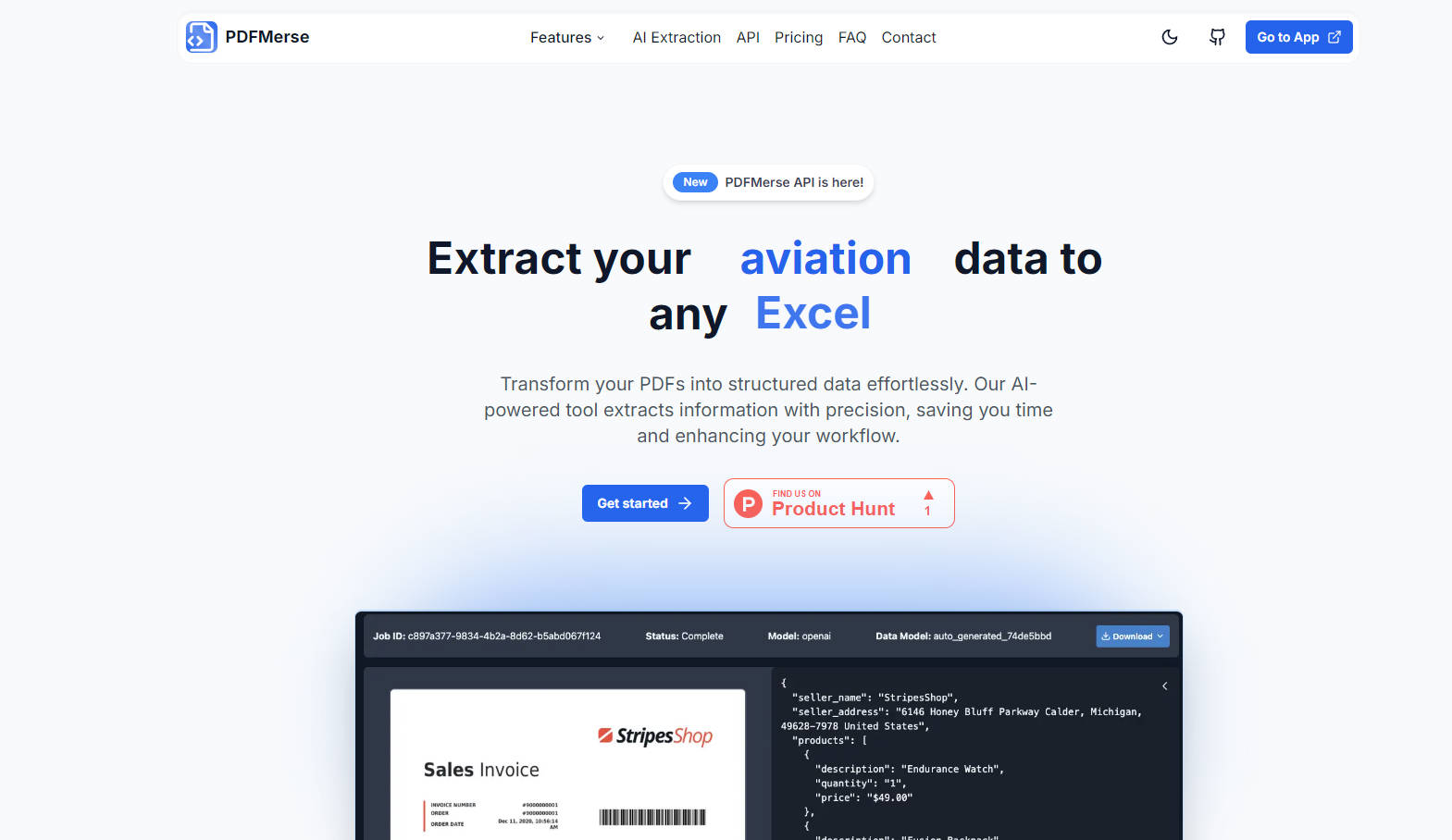
What is PDFMerse?
PDFMerse, революционный инструмент на основе искусственного интеллекта, оптимизирует преобразование статических данных PDF в структурированные, пригодные для использования форматы, такие как JSON, CSV и Excel, с исключительной точностью. Эта платформа революционизирует документооборот, автоматизируя извлечение информации из сложных файлов, включая рукописный текст, и предлагая поддержку нескольких языков, что делает обработку данных более быстрой, экономичной и без ошибок.
Ключевые особенности:
Автоматизированное извлечение данных: PDFMerse автоматизирует извлечение данных из различных документов PDF, устраняя часы ручного труда.
Гарантия структурированных данных: Извлеченные данные всегда структурированы и отформатированы для удобной интеграции в ваши системы.
Высокая точность и встроенная валидация: Встроенная валидация гарантирует точность и согласованность данных, значительно сокращая количество ошибок.
RESTful API для бесшовной интеграции: Интегрируйте мощные функции извлечения PDFMerse в свои приложения с помощью простого, высокопроизводительного API.
Пользовательские модели данных: Опишите данные, которые вам нужно извлечь, и наш ИИ сгенерирует модель, упрощая сложные задачи извлечения.
Примеры использования:
Компании, обрабатывающие счета-фактуры: Автоматически извлекайте данные из счетов-фактур, экономя часы на ручном вводе и минимизируя ошибки.
Медицинские учреждения, работающие с медицинскими картами пациентов: Оптимизируйте управление данными пациентов, извлекая данные из медицинских карт в структурированные форматы для более удобного электронного хранения.
Юридические фирмы, организующие документы: Быстро организуйте и извлеките важную информацию из различных юридических документов, повышая эффективность и качество обслуживания клиентов.
Заключение:
PDFMerse обеспечивает непревзойденную эффективность и точность извлечения данных, превращая статические PDF в динамические активы. Оптимизируйте свой рабочий процесс, экономите время и сокращайте расходы с помощью нашего решения на основе искусственного интеллекта, разработанного для точной обработки данных ваших документов. Попробуйте PDFMerse сегодня и раскройте весь потенциал ваших данных PDF.
Часто задаваемые вопросы:
Какие типы PDF поддерживает PDFMerse?PDFMerse поддерживает широкий спектр типов PDF, включая сложные документы, такие как счета-фактуры, медицинские карты, юридические файлы и многое другое. Он обрабатывает как структурированные, так и неструктурированные форматы, с заметной эффективностью в распознавании рукописного текста.
Какой уровень точности я могу ожидать от извлечения данных?Точность извлечения обычно превышает 95%, хотя это может варьироваться в зависимости от качества и сложности PDF. Модели ИИ PDFMerse постоянно совершенствуются для повышения точности в различных категориях документов.
Могу ли я интегрировать возможности извлечения PDFMerse в свои собственные приложения?Конечно! Наш RESTful API предлагает эффективный способ автоматизации извлечения данных PDF в ваших приложениях, предоставляя структурированные выходные форматы, которые легко интегрируются с вашими системами.
More information on PDFMerse
Launched
2024-06
Pricing Model
Freemium
Starting Price
$5 /month
Global Rank
Follow
Month Visit
<5k
Tech used
Cloudflare CDN,Next.js,Gzip,OpenGraph,Webpack
PDFMerse was manually vetted by our editorial team and was first featured on 2024-08-17.
Related Searches
PDFMerse Альтернативи
Больше Альтернативи-

-

-

Parse Extract: Передовое извлечение данных и ОРС для конвейеров LLM. Превращает сложные документы и веб-данные в чистый текст, готовый для обработки LLM. Экономично и безопасно.
-
-
