
What is PDFMerse?
PDFMerseは、画期的なAI駆動型ツールであり、静的なPDFデータをJSON、CSV、Excelなどの構造化された実用的な形式に変換するプロセスを、卓越した精度で合理化します。このプラットフォームは、手書きテキストを含む複雑なファイルからの情報の抽出を自動化し、多言語サポートを提供することで、ドキュメントワークフローに革命をもたらし、データ処理をより高速、費用対効果が高く、エラーのないものにします。
主な機能:
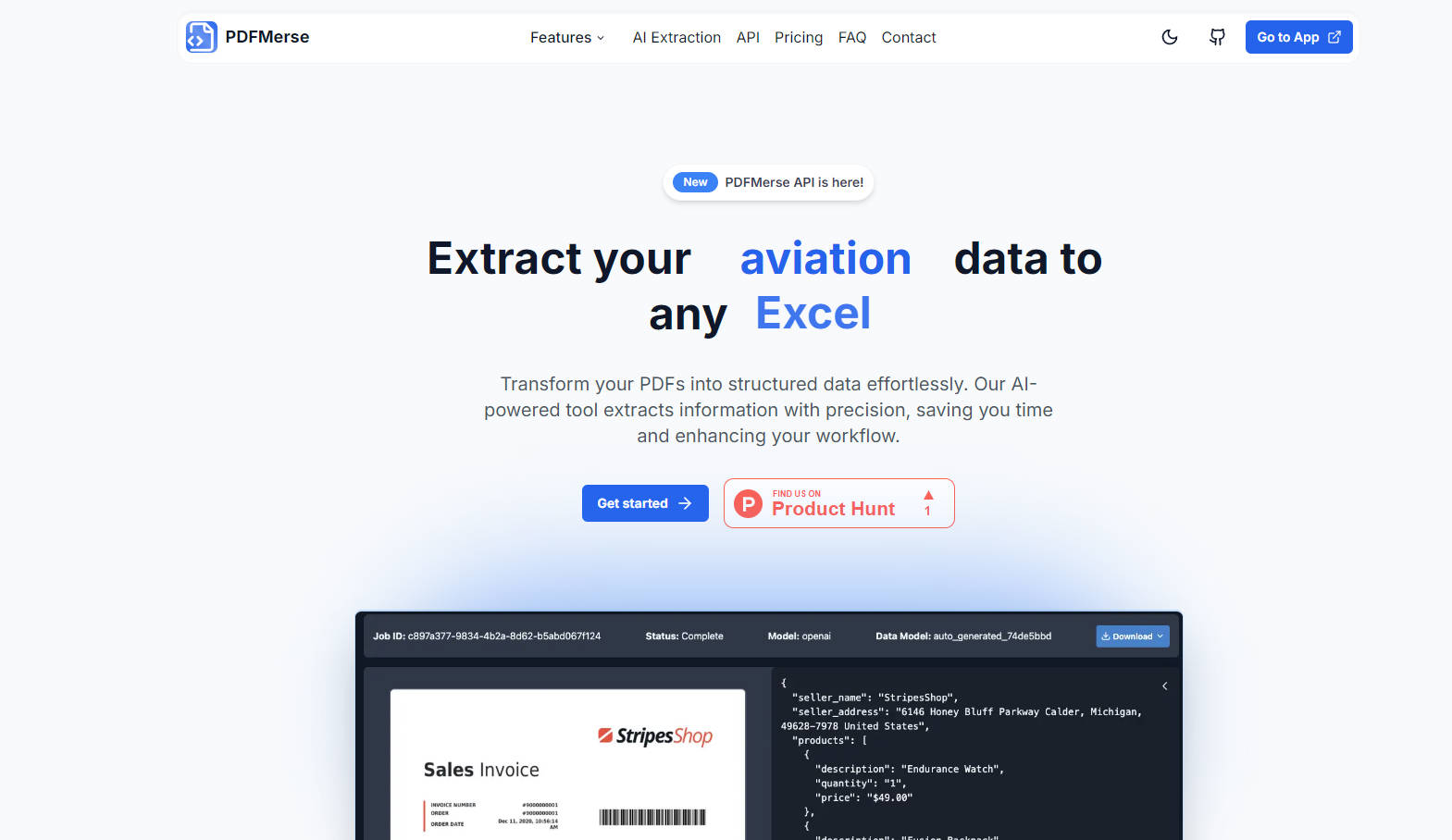
自動データ抽出: PDFMerseは、さまざまなPDFドキュメントからのデータ抽出を自動化し、手作業による何時間もかかる作業を削減します。
構造化データ保証: 抽出されたデータは常に構造化され、フォーマット化されているため、システムへの統合が容易です。
高精度&検証統合: 組み込みの検証により、データの精度と一貫性が確保され、エラーが大幅に削減されます。
シームレスな統合のためのRESTful API: シンプルで高性能なAPIを使用して、PDFMerseの強力な抽出機能をアプリケーションに統合します。
カスタムデータモデル: 抽出する必要があるデータを記述すると、AIがモデルを生成し、複雑な抽出タスクを簡素化します。
ユースケース:
請求書処理を行う企業: 請求書から詳細を自動的に抽出し、手動入力にかかる時間を節約し、エラーを最小限に抑えます。
患者記録を扱う医療施設: 患者データ管理を合理化し、医療記録データを構造化された形式に抽出することで、電子保管を容易にします。
文書を整理する法律事務所: 多様な法律文書から重要な情報を迅速に整理および抽出し、効率性と顧客サービスの質を向上させます。
結論:
PDFMerseは、データ抽出において比類のない効率性と精度を提供し、静的なPDFを動的な資産に変えます。AI駆動型ソリューションでワークフローを最適化し、時間を節約し、コストを削減しましょう。これは、ドキュメントデータを正確に処理するために設計されています。今すぐPDFMerseを試して、PDFデータの可能性を最大限に引き出しましょう。
よくある質問:
PDFMerseはどのタイプのPDFをサポートしていますか?PDFMerseは、請求書、医療記録、法律ファイルなど、複雑なドキュメントを含む、幅広いPDFタイプをサポートしています。構造化された形式と構造化されていない形式の両方を処理し、手書きテキスト認識に優れた能力を発揮します。
データ抽出からどの程度の精度が期待できますか?抽出精度は通常95%を超えますが、PDFの品質と複雑さによって異なる場合があります。PDFMerseのAIモデルは、さまざまなドキュメントカテゴリにおける精度を向上させるために継続的に改善されています。
PDFMerseの抽出機能を独自のアプリケーションに統合できますか?もちろんです!RESTful APIは、アプリケーションでPDFデータ抽出を自動化し、システムに簡単に統合できる構造化された出力形式を提供するための効率的な方法を提供します。
More information on PDFMerse
Launched
2024-06
Pricing Model
Freemium
Starting Price
$5 /month
Global Rank
Follow
Month Visit
<5k
Tech used
Cloudflare CDN,Next.js,Gzip,OpenGraph,Webpack
PDFMerse was manually vetted by our editorial team and was first featured on 2024-08-17.
Related Searches
PDFMerse 代替ソフト
もっと見る 代替ソフト-

-

-

Parse Extract: LLMパイプライン向けの高度なデータ抽出とOCR。 複雑なドキュメントやウェブデータを、クリーンでLLMに最適なテキストへと変換します。 費用対効果に優れ、高いセキュリティを実現します。
-
-
