
What is PDFMerse?
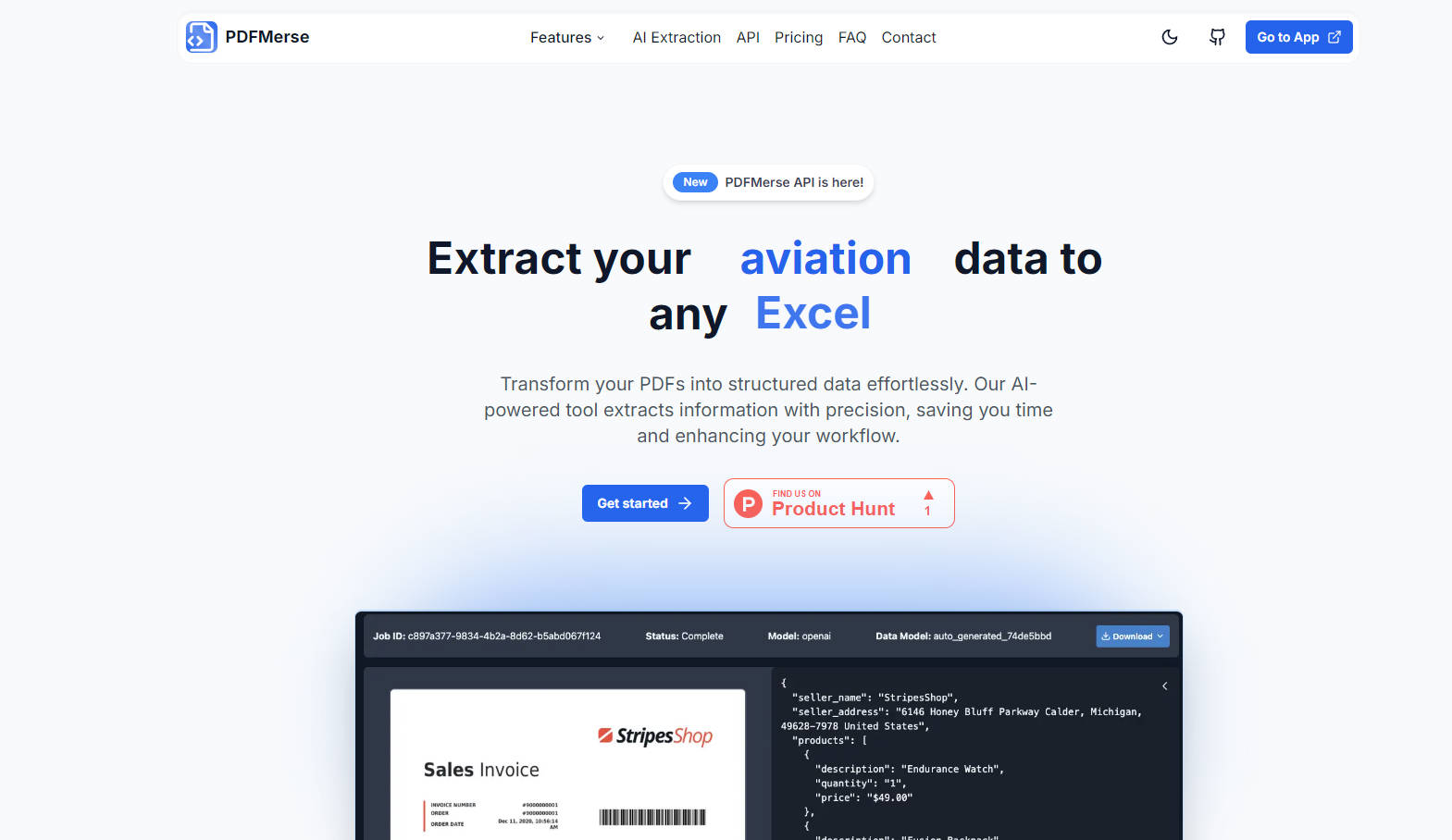
PDFMerse, a groundbreaking AI-driven tool, streamlines the conversion of static PDF data into structured, actionable formats like JSON, CSV, and Excel with exceptional accuracy. This platform revolutionizes document workflows, automating the extraction of information from complex files, including handwritten text, and offering multilanguage support, making data processing faster, cost-effective, and error-free.
Key Features:
Automated Data Extraction: PDFMerse automates the extraction of data from various PDF documents, eliminating hours of manual work.
Structured Data Guarantee: Extracted data is always structured and formatted for easy integration into your systems.
Highly Accurate & Validation-Integrated: Built-in validation ensures data accuracy and consistency, drastically reducing errors.
RESTful API for Seamless Integration: Integrate PDFMerse's powerful extraction features into your applications with a simple, high-performance API.
Custom Data Models: Describe the data you need to extract, and our AI generates the model, simplifying complex extraction tasks.
Use Cases:
Businesses processing invoices: Automatically extract details from invoices, saving hours on manual entry and minimizing errors.
Medical facilities handling patient records: Streamline patient data management by extracting medical records data into structured formats for easier electronic storage.
Legal firms organizing documents: Quickly organize and extract critical information from diverse legal documents, enhancing efficiency and client service quality.
Conclusion:
PDFMerse delivers unparalleled efficiency and accuracy in data extraction, transforming static PDFs into dynamic assets. Optimize your workflow, save time, and reduce costs with our AI-driven solution designed to handle your document data with precision. Try PDFMerse today and unlock the full potential of your PDF data.
FAQs:
Which types of PDFs does PDFMerse support?PDFMerse supports a wide range of PDF types, including complex documents like invoices, medical records, legal files, and more. It handles both structured and unstructured formats, with notable proficiency in handwritten text recognition.
What accuracy level can I expect from the data extraction?Extraction accuracy typically exceeds 95%, although this can vary based on PDF quality and complexity. PDFMerse's AI models are continuously refined to improve accuracy across various document categories.
Can I integrate PDFMerse's extraction capabilities into my own applications?Absolutely! Our RESTful API offers an efficient method to automate PDF data extraction in your applications, providing structured output formats that easily integrate with your systems.
More information on PDFMerse
Launched
2024-06
Pricing Model
Freemium
Starting Price
$5 /month
Global Rank
Follow
Month Visit
<5k
Tech used
Cloudflare CDN,Next.js,Gzip,OpenGraph,Webpack
PDFMerse was manually vetted by our editorial team and was first featured on 2024-08-17.
Related Searches
PDFMerse Alternatives
Load more Alternatives-

-

-

Parse Extract: Advanced data extraction & OCR for LLM pipelines. Transform complex documents & web data into clean, LLM-ready text. Cost-efficient & secure.
-
-
