What is Glm-4v-9b?
清華大学が開発したGLM-4V-9Bは、特に光学文字認識(OCR)において、さまざまなベンチマークで優れた性能を発揮する最先端のマルチモーダル言語モデルです。これは、チャット指向モデルを含むGLM-4シリーズに属します。GLM-4V-9Bの主要な特徴は、画像説明、視覚的な質問応答、マルチモーダル推論などのタスクを効果的に実行できるようにする、追加された視覚理解機能です。
主な機能
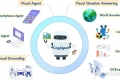
マルチモーダル理解と生成:GLM-4V-9Bは、画像の詳細で首尾一貫した説明を生成し、視覚コンテンツに関する質問に答え、視覚的な推論やOCRなどのタスクを実行できます。これにより、複雑なチャートや図を分析し、重要な情報を要約することが得意になります。
クロス言語サポート:このモデルは、中国語と英語の両方をサポートしており、世界中のユーザーベースにとって汎用性があります。複数の言語を処理できるため、さまざまな設定で適用範囲が広がります。
高度なチャットとマルチモーダル機能:視覚的およびテキストの対話に参加するなどの機能により、GLM-4V-9Bは、マルチモーダルな会話型AIアシスタントを開発するための強力なツールとして機能します。画像キャプション、視覚的な質問応答を処理し、コンテンツ生成に視覚的およびテキスト要素を統合できます。
More information on Glm-4v-9b
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Glm-4v-9b was manually vetted by our editorial team and was first featured on 2024-07-16.