What is Tonic Textual?
Tonic Textual은 세계 최초의 대규모 언어 모델(LLM) 전용 보안 데이터 레이크하우스로, AI 혁신의 선두에 서 있습니다. 이 획기적인 플랫폼은 비정형 데이터를 원활하게 통합, 보호 및 준비하여 기업이 생성형 AI의 잠재력을 최대한 활용할 수 있도록 지원합니다. Tonic Textual은 개인 정보 보호 및 효율성에 중점을 두어 사용자가 비정형 데이터를 몇 분 만에 추출, 관리, 강화 및 AI 애플리케이션에 배포할 수 있도록 합니다.
주요 기능
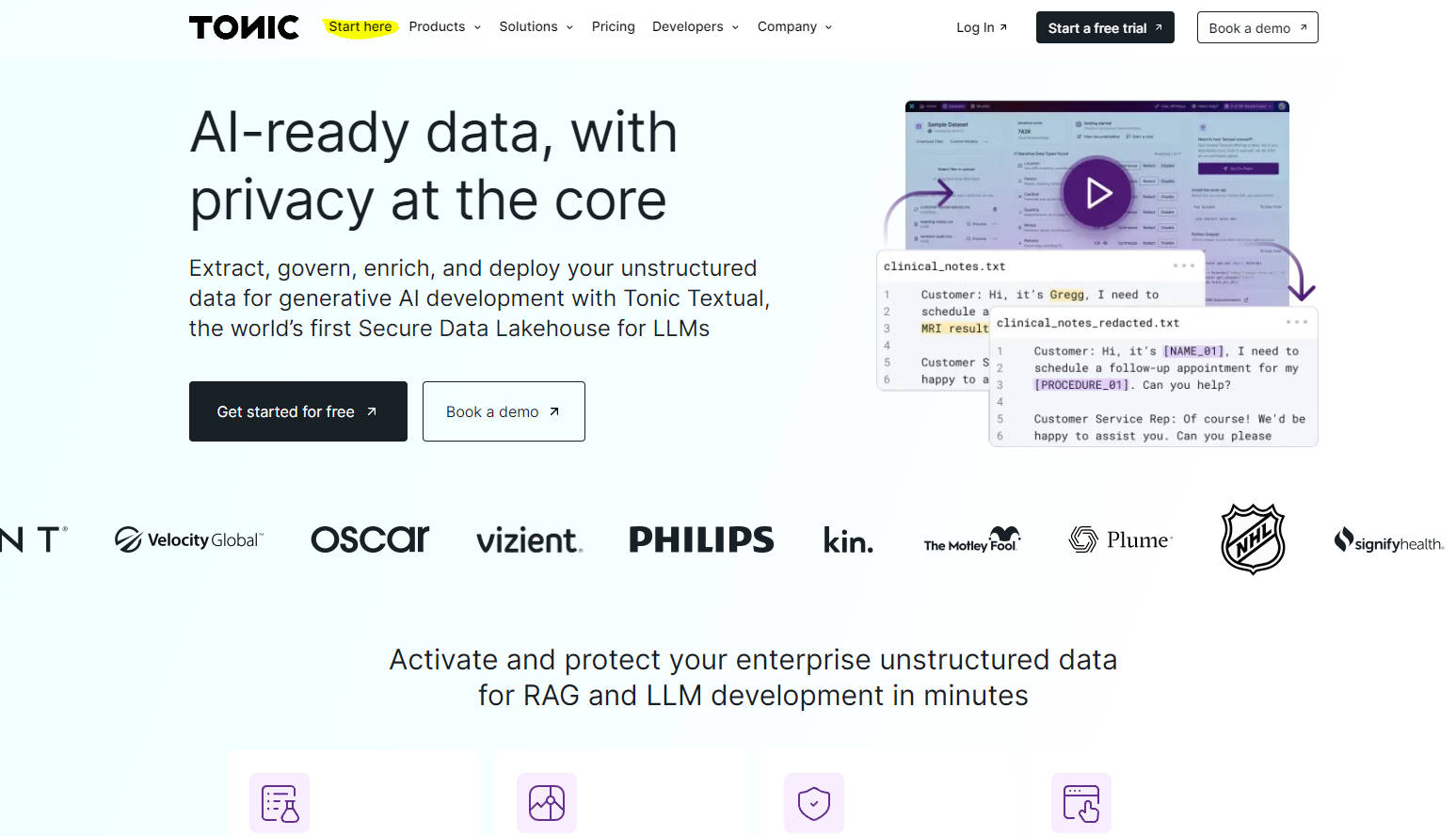
자동 데이터 추출 ?: 클라우드 데이터 저장소에서 직접 비정형 데이터를 자동으로 추출, 구조화 및 표준화하여 AI 준비 형식으로 변환하는 효율적인 파이프라인을 구축합니다.
고급 데이터 강화 ?: Textual의 NER(Named Entity Recognition) 모델을 활용하여 고품질 메타데이터 및 사용자 지정 엔터티 태그로 데이터를 강화하여 RAG(Recursive Autoencoders)의 성능과 정확성을 높입니다.
강력한 데이터 거버넌스 ?: 민감한 엔터티를 발견, 태그 지정 및 삭제하여 민감하고 독점적인 데이터를 보호하여 모델 메모리 및 데이터 유출을 방지합니다. 의미적 사실성을 유지하기 위해 합성 데이터로 삭제를 다시 시드합니다.
원활한 통합 및 배포 ?: RAG 및 미세 조정을 위한 선도적인 임베딩 모델, 벡터 데이터베이스 및 AI 개발자 플랫폼과 통합하여 다운스트림 AI 프로세스에서 데이터 사용을 용이하게 합니다.
사용 사례
금융 기관: Tonic Textual은 텍스트 데이터에서 민감한 정보를 자동으로 식별하고 삭제하여 금융 기관이 GDPR 및 기타 데이터 개인 정보 보호 규정을 준수하도록 지원합니다.
의료 제공자: 이 플랫폼은 의료 분야에서 비정형 의료 기록 내의 개인 건강 정보를 감지하고 보호하여 환자 기밀성을 보장합니다.
법률 회사: 법률 전문가는 Tonic Textual을 사용하여 법률 문서의 민감한 정보를 관리하고 삭제하여 AI를 활용한 법률 연구 및 분석을 수행하는 동시에 클라이언트 개인 정보를 보호합니다.
결론
Tonic Textual은 단순한 데이터 관리 도구가 아니라 기업이 비정형 데이터와 상호 작용하는 방식에 혁명을 일으킵니다. Tonic Textual은 개인 정보 보호와 효율성을 우선시함으로써 생성형 AI의 잠재력을 해방하는 동시에 민감한 정보가 보호되도록 합니다. 데이터 과학을 극대화하고 데이터 준비를 최소화하는 Tonic Textual로 AI의 미래를 받아들이세요.
More information on Tonic Textual
Launched
2017-12
Pricing Model
Free Trial
Starting Price
Global Rank
466366
Follow
Month Visit
78.1K
Tech used
Google Tag Manager,HubSpot Analytics,Microsoft Clarity,Webflow,Amazon AWS CloudFront,JSDelivr,Google Fonts,JavaScript Cookie,jQuery,Gzip,OpenGraph
Top 5 Countries
54.93%
3.01%
2.83%
2.43%
2.21%
United States
India
Vietnam
France
Nigeria
Traffic Sources
3.07%
1.24%
0.1%
9.41%
43.2%
42.96%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 24, 2025)
Tonic Textual was manually vetted by our editorial team and was first featured on 2024-05-29.
Related Searches
Tonic Textual 대체품
더보기 대체품-

-

-

Tensorlake Cloud는 문서 수집 및 데이터 오케스트레이션을 위한 플랫폼입니다. 실제 문서를 사람이 이해하는 방식과 유사하게 레이아웃을 파악하여 분석하고, 프로덕션 환경에 바로 적용 가능한 Python 기반 워크플로우를 대규모로 구축할 수 있습니다.
-
NaturalText A.I.를 사용하여 데이터에 숨겨진 통찰력을 발견하세요. 문서와 텍스트 기반 데이터에서 관계를 파악하고, 컬렉션을 구축하며, 패턴을 분석하세요.
-