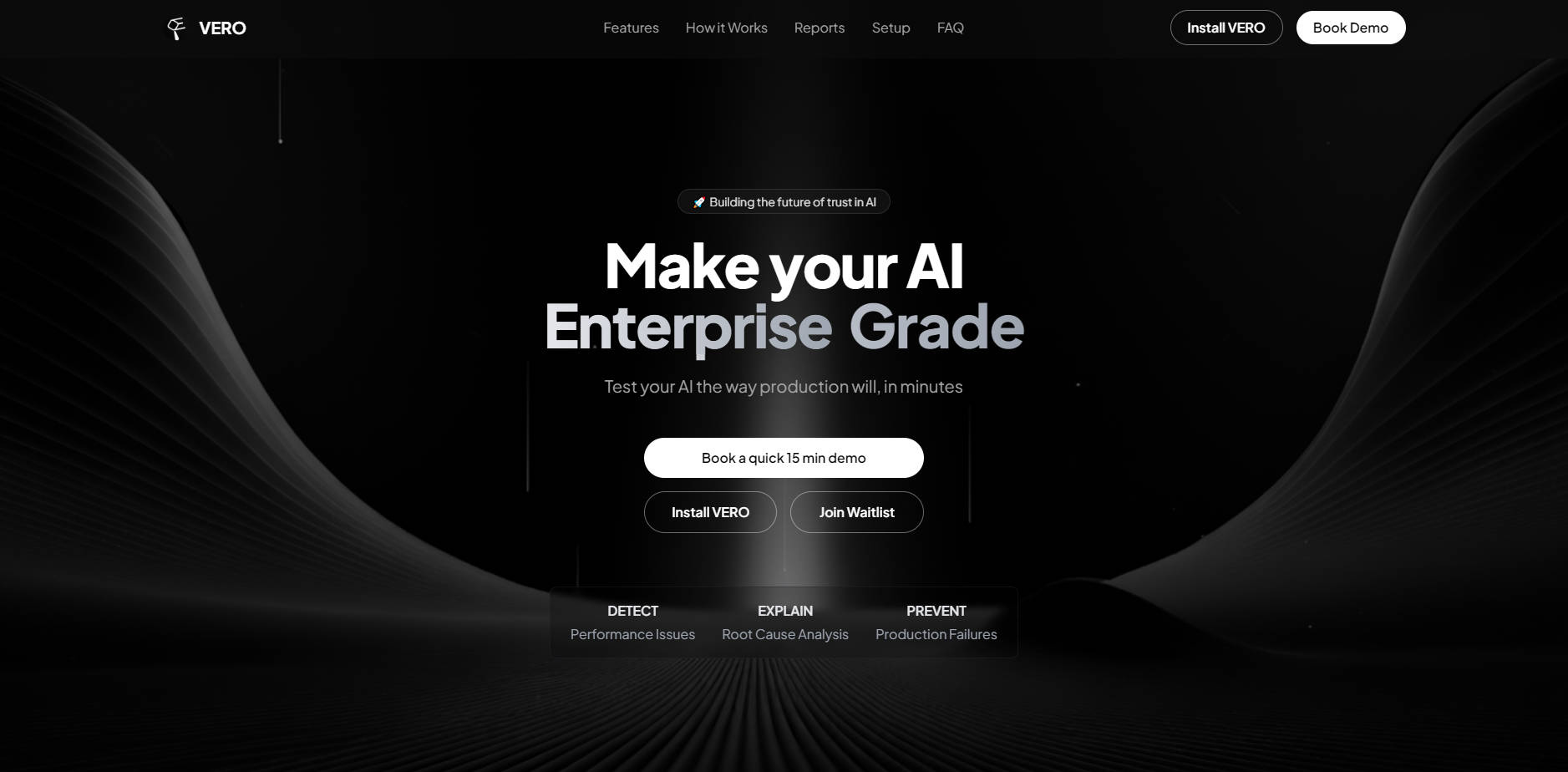
What is Vero ?
VERO is a comprehensive AI Evaluation Framework designed to bring enterprise-grade reliability and trust to your large language model (LLM) pipelines. It addresses the critical challenge of AI uncertainty by enabling development teams to quickly detect performance issues, explain root causes, and prevent costly production failures. VERO empowers developers, product managers, and stakeholders to transform lengthy QA cycles from weeks into minutes of data-driven confidence.
Key Features
VERO provides the tools necessary to test your AI system the way production will run, ensuring robustness across complex Retrieval-Augmented Generation (RAG) and other AI architectures.
⚡ Lightning Fast Reports
Our optimized evaluation engine delivers comprehensive performance reports in hours, not days. You gain immediate, data-driven insights when you need them most, dramatically accelerating your iteration speed and allowing for rapid intervention before deployment.
🔎 End-to-End Pipeline Insights
VERO audits each block of your AI pipeline—including the Retriever, Reranker, and Generation components—to ensure compliance and optimal functioning. Reports are specialized to provide detailed metrics (like Context Sufficiency and Hallucination scores) tailored specifically for developers, product managers, and executive stakeholders.
🛠️ Actionable Diagnostics and Fixes
VERO moves beyond simple failure detection. Reports provide clear, actionable fixes and suggested strategies to fine-tune your pipeline for performance uplift. For instance, if the pipeline misses nuanced context, VERO might diagnose the issue and suggest specific retrieval strategy changes, such as implementing a Hybrid-Retrieval method like BM-25 alongside semantic search.
🔄 Robust Version Control
Maintain unparalleled confidence by tracking changes and comparing performance over time. VERO provides robust version control for your AI pipeline configurations, allowing you to clearly visualize the performance uplift between versions (e.g., comparing V1.0 to V2.1) after implementing fixes.
Use Cases
VERO integrates seamlessly into your workflow, providing tangible value across the AI development lifecycle:
1. Fine-Tuning RAG Components
A development team is struggling with accurate information recall in their internal knowledge RAG system. Using VERO's detailed reports, they analyze the Retriever metrics, identifying a low Domain Accuracy score (82%). The report diagnoses that the current chunking strategy is inadequate for complex domain-specific evidence. By acting on the suggested fix—refining embedding techniques and adjusting the chunking strategy—the team quickly drives the Domain Accuracy score higher, ensuring the model elevates concise trial evidence rather than just general definitions.
2. Demonstrating Performance Uplift to Stakeholders
A Product Manager needs to justify the resources spent on the latest AI model update. They use VERO's Version Control feature to compare performance metrics. The report clearly shows that after incorporating VERO's suggested fixes, Relevancy jumped from 82% to 95%, and Precision improved from 85% to 98%. This data provides non-technical stakeholders with objective proof of the AI's quality improvement and return on investment.
3. Continuous Compliance and Monitoring
An enterprise organization requires continuous monitoring to maintain compliance standards (e.g., preventing toxic language or ensuring domain alignment). VERO is integrated into the CI/CD pipeline, automatically running validations using custom metrics (like Faithfulness and Toxic Language detection). Any score deviation triggers an alert and an immediate diagnostic report, preventing non-compliant models from reaching production.
Why Choose VERO?
VERO offers a straightforward, four-step process to transform AI uncertainty into confidence, providing a competitive edge through speed and depth of insight.
Audit Every Block: Unlike basic LLM evaluation tools, VERO provides deep, component-level analysis (Retriever, Reranker, Generator) necessary for complex RAG architectures. This functional insight ensures you know exactly where a failure originates.
From Insight to Impact: We don't just identify issues; we deliver the clear, actionable diagnostics required to implement immediate, targeted fixes, significantly reducing debugging time and accelerating time-to-market.
Confidence Through Metrics: Our extensive library of pre-built tests—covering Answer Relevancy, Faithfulness, Domain Alignment, and Custom Metrics—allows you to validate performance against the exact benchmarks production requires.
Conclusion
VERO provides the reliability framework necessary to elevate your AI systems to enterprise grade. Stop guessing about your model's performance and start proving your AI works with verifiable, data-driven reports.
Explore how VERO can help you achieve unparalleled confidence in your AI pipeline. Book a quick 15-minute demo today.
More information on Vero
Launched
Pricing Model
Free Trial
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Vero was manually vetted by our editorial team and was first featured on 2025-10-30.
Vero Alternatives
Load more Alternatives-

-
-

Companies of all sizes use Confident AI justify why their LLM deserves to be in production.
-
-