What is Adala?
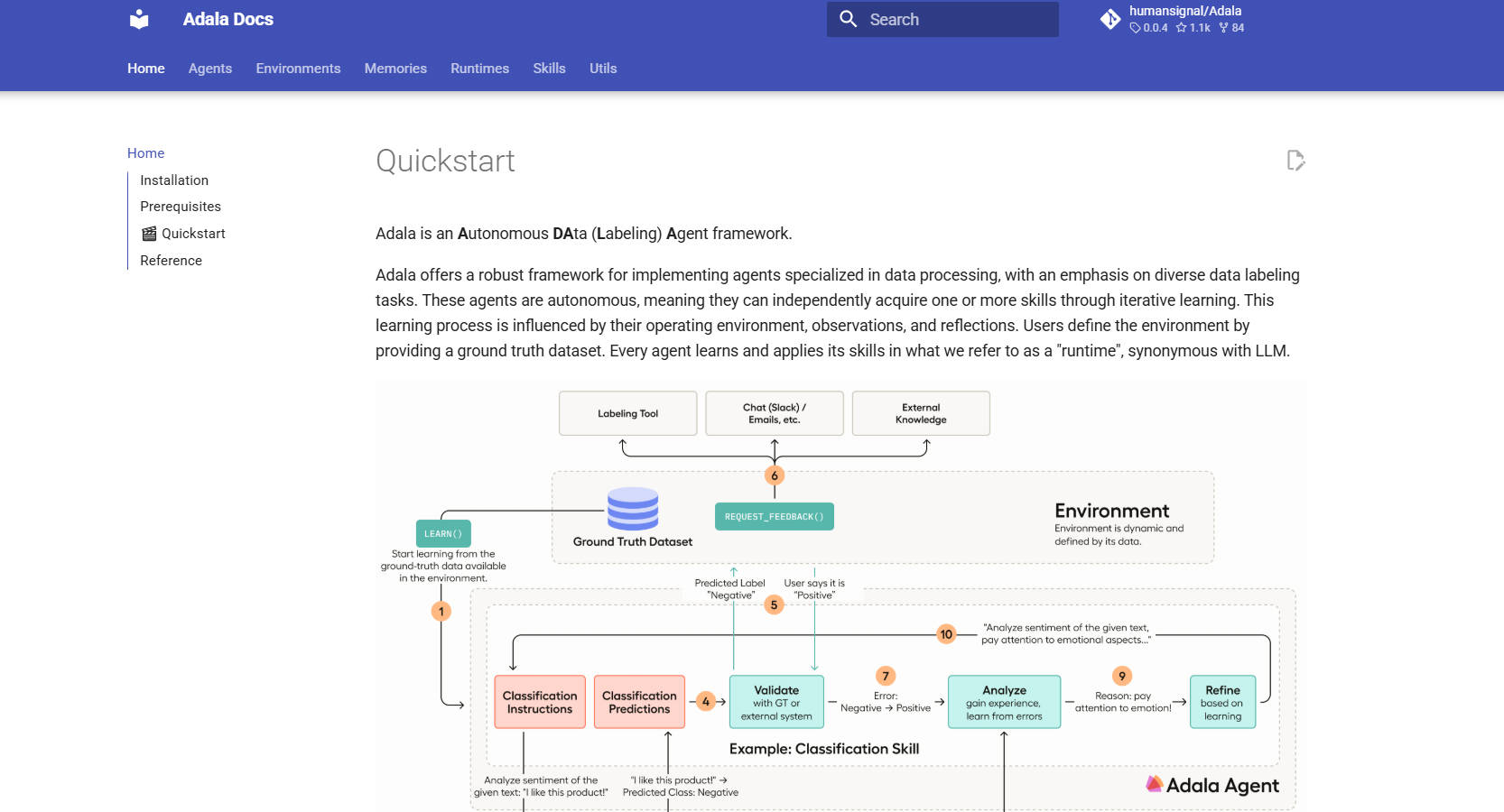
数据标注和处理可能会成为 AI 开发的瓶颈。Adala 是一种自主数据标注代理框架,旨在简化此过程。它使您能够构建智能代理,这些代理可以学习并适应您的特定数据需求,从而确保可靠且一致的结果。与手动、重复性任务不同,Adala 允许您专注于更高级别的 AI 开发。
主要特性:
🤖 构建可靠的代理: 创建基于您提供的真实数据的基础代理。这种基础方法确保您的代理产生可信且一致的输出,这对于数据完整性至关重要。
⚙️ 控制代理输出: 微调您的代理所拥有的每项技能的所需输出。您可以设置特定的约束,范围从严格的指南到基于代理学习的更灵活、适应性强的响应。
专注于数据处理: 为各种数据处理任务定制代理。虽然它们擅长数据标注,但 Adala 的灵活性扩展到各种以数据为中心的需求。
🧠 启用自主学习: Adala 代理不仅仅是预先编程的;它们会学习。通过与环境互动、观察和反思,它们会迭代且独立地发展和完善自己的技能。
🛠️ 利用灵活且可扩展的运行时: 在多个运行时 (LLMs) 上部署单项技能,从而实现动态架构,如师生模型。开放框架鼓励社区贡献,从而促进持续发展和适应。
🚀 轻松定制: 开发和定制代理,以快速解决您独特的挑战。Adala 的设计最大限度地减少了学习曲线,使您能够高效地启动和运行。
使用案例:
AI 工程师工作流程增强: 假设您正在构建一个复杂的 AI 系统,该系统需要多个数据预处理步骤。借助 Adala,您可以设计一个由相互连接的模块化代理组成的系统,每个代理处理一个特定任务。这种模块化允许更轻松地维护、更新和扩展您的 AI 管道。您可以自由地专注于生产级别的系统,将低级别的 ML 细节抽象到 Adala 和 LLMs。
机器学习研究实验: 作为一名研究人员,您正在探索复杂的问题分解。Adala 提供了一个平台来试验不同的代理架构和技能组合,使您能够在受控环境中测试关于因果推理和问题解决方法的假设。
数据科学家预处理/后处理: 您有一个大型数据集,需要在模型训练之前进行清理和转换。您可以部署 Adala 代理来自动执行这些任务,而无需编写大量自定义脚本。例如,一个代理可能处理缺失值插补,而另一个代理执行特征缩放,所有这些都在 Python 笔记本环境中进行。
结论:
Adala 提供了一种强大而灵活的数据标注和处理方法。通过利用基于您的数据的自主代理,您可以实现更高的效率、可靠性和对 AI 开发工作流程的控制。无论您是 AI 工程师、机器学习研究人员还是数据科学家,Adala 都能提供简化任务并专注于创新的工具。
More information on Adala
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Adala was manually vetted by our editorial team and was first featured on 2025-02-23.
Related Searches