What is ManyLLM ?
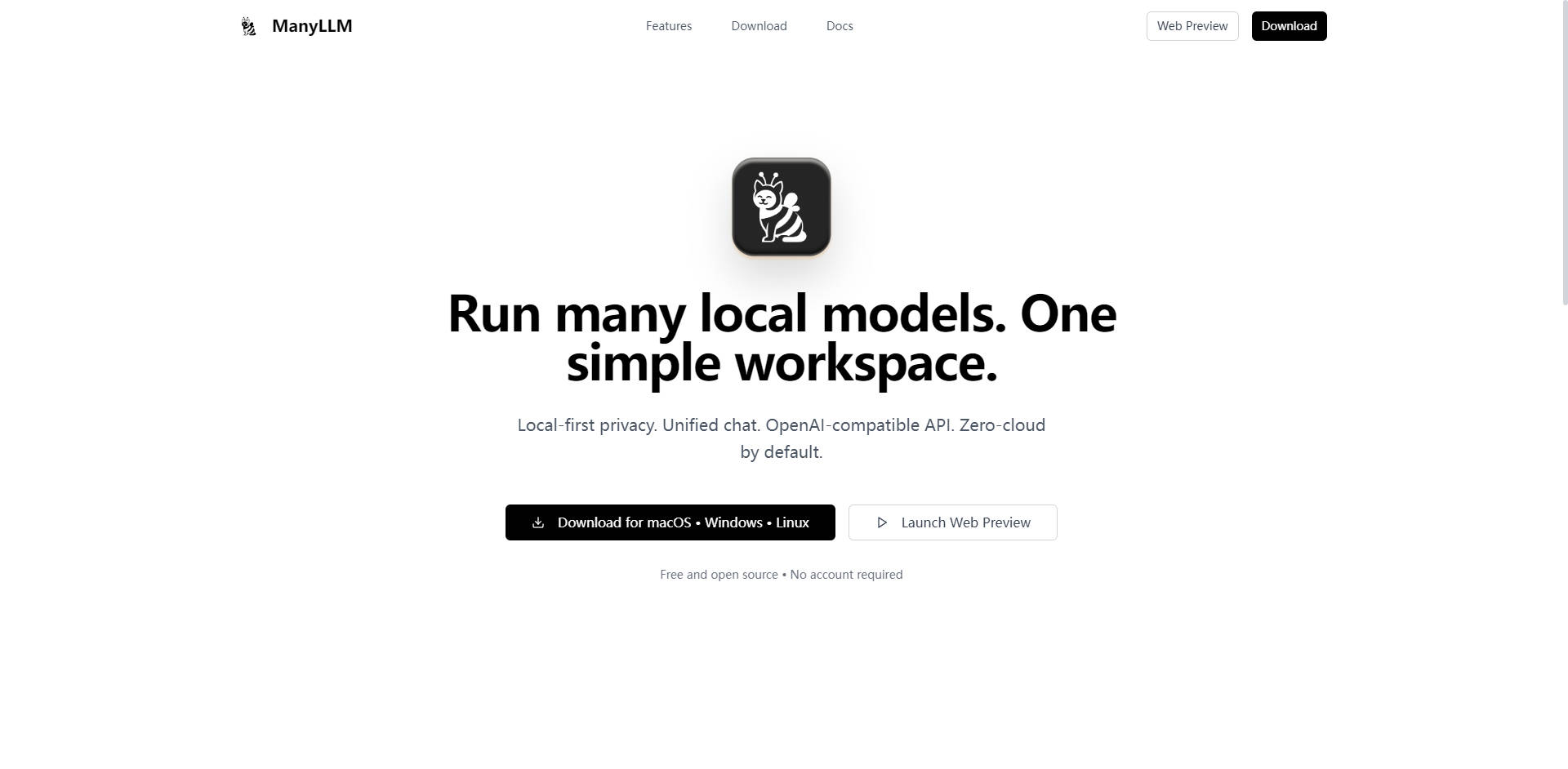
ManyLLM 是一个强大且隐私至上的界面,专为在一个统一的工作空间内运行、管理和整合多个本地大型语言模型(LLMs)而设计。它提供了一个集中、高效且用户友好的解决方案,解决了管理分散式本地 AI 运行时所带来的挑战。ManyLLM 专为开发者、研究人员和注重隐私的团队打造,确保您的 AI 工作流程安全、灵活,并完全在本地执行。
主要特性
ManyLLM 提供您所需的一切,助您充分发挥本地 AI 模型的强大能力,同时确保企业级的隐私保护和无缝集成体验。
🧠 高级模型管理
ManyLLM 凭借智能运行时检测功能,让您能够无缝运行多个本地 LLMs。它会自动识别并集成包括 Ollama、llama.cpp 和 MLX 在内的流行运行时。这一能力使您无需重启系统即可轻松切换模型,同时优化内存和 GPU 使用,确保本地性能达到巅峰。
📂 工作空间、上下文与本地 RAG
通过整合专有数据,您可以有效组织项目,并实现上下文感知的对话。ManyLLM 提供简单的拖放功能,让您轻松将文件添加到专用工作空间,进而启动本地嵌入和向量搜索。这为本地检索增强生成(RAG)提供了强大支持,确保您的模型响应严格基于您的私有文档。
🔗 兼容 OpenAI 的本地 API
ManyLLM 提供标准 OpenAI API 的即插即用替代方案,暴露如 /v1/chat/completions 等端点,使您无需修改即可将本地模型无缝集成到现有应用程序和脚本中。此功能让开发者能够利用高性能的本地模型,同时保持与现有工具和框架的良好兼容性。
🔒 零云隐私架构
ManyLLM 让您对工作流程拥有完全的掌控和安全保障。它秉持“本地优先”的原则,意味着所有数据处理、存储和交互都完全在您的设备上进行。通过默认执行零云策略,ManyLLM 有效消除了数据传输风险,确保了最大程度的隐私合规性。
💬 统一聊天与流式传输
通过一致且统一的聊天界面,您可以与所有支持的模型进行交互。ManyLLM 提供实时流式响应、对话历史搜索,并支持自定义系统提示和参数以实现精确的模型行为。您还可以将对话导出为多种格式,方便文档记录和管理。
应用场景
ManyLLM 旨在加速开发、研究和数据分析等对隐私和控制要求极高的领域的工作流程。
1. 安全、上下文感知的文档分析 对于处理高度敏感文档的法律、金融或专有研究团队,您可以创建一个专属的 ManyLLM 工作空间,上传文件,并利用本地 RAG 系统进行查询。由于从嵌入创建到模型推理的整个过程都在本地进行,您能够获得深入而准确的洞察,同时避免将机密数据上传至外部服务器的风险。
2. 快速 AI 应用原型开发 构建 AI 驱动功能的开发者可以利用 ManyLLM 兼容 OpenAI 的本地 API,快速进行原型开发和集成测试。在初始开发阶段,无需依赖昂贵且受速率限制的云 API,而是可以使用高速的本地模型(如 Llama 3)作为即插即用的替代方案,从而显著加快迭代速度并降低成本。
3. 模型对比基准测试 需要评估不同开源模型性能的研究人员(例如,比较 7B 模型与 70B 模型的连贯性),可以利用 ManyLLM 集成的模型管理和性能监控工具。它支持在运行时和模型之间轻松即时切换,确保在标准化测试中,能够公平地比较输出质量、速度和资源利用率。
为何选择 ManyLLM?
ManyLLM 通过统一通常碎片化的本地 LLM 管理生态系统,以其独特的灵活性、集成性和安全性组合而脱颖而出。
运行时统一: 不同于那些将您局限于单一运行时或生态系统的工具,ManyLLM 能够自动管理并统一 Ollama、llama.cpp 和 MLX。这种灵活性确保您能够以最少的设置障碍,使用最广泛的开源模型。
无缝集成: 兼容 OpenAI 的本地 API 将本地模型从孤立的实验转变为可随时集成的组件。这对于那些既需要本地控制,又要求标准 API 格式以实现生产就绪的开发者来说至关重要。
隐私无忧: ManyLLM 优先采用“本地优先”的架构,提供真正的隐私解决方案。您的数据始终保留在您的硬件上,这为那些无法容忍云端暴露的敏感项目提供了坚实的保障。
总结
ManyLLM 赋能开发者、研究人员和注重隐私的组织,使其能够在安全、精简且高度灵活的环境中,充分发挥本地 AI 模型的潜力。它不仅提供了日常使用所需的功能熟悉度,更具备高级工作流程所需的强大集成能力。
探索 ManyLLM 如何统一您的本地 AI 工作流程并保护您的数据。立即下载,在几分钟内即可开始运行本地模型。
More information on ManyLLM
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
ManyLLM was manually vetted by our editorial team and was first featured on 2025-11-08.