What is Crawl4LLM?
The quality and efficiency of data acquisition are paramount in the era of large language models (LLMs). Traditional web crawlers often struggle with the sheer volume of the web, leading to wasted resources and suboptimal training datasets. Crawl4LLM, a collaborative open-source project from Tsinghua University and Carnegie Mellon University, directly addresses this challenge. It's an intelligent web crawling system designed to prioritize the collection of high-value web pages specifically for LLM pre-training, achieving a nearly 5x improvement in data acquisition efficiency.
Key Features:
🤖 Intelligent Web Page Selection: Employs a pre-trained impact scoring system (utilizing the DCLM fastText model) to evaluate the value of web page content before crawling. This prioritizes high-value pages, minimizing the collection of irrelevant or low-quality data. Technical Detail: The scoring considers content quality, relevance, and other indicators, providing a comprehensive assessment of a page's usefulness for LLM training.
⚙️ Multiple Crawling Modes: Offers flexibility to adapt to various data acquisition needs:
Intelligent Mode: Dynamically adjusts the crawling strategy based on the web page value scores. This is the core mode for maximizing efficiency.
Random Mode: Provides a baseline crawling approach, similar to traditional crawlers, for scenarios where targeted data is not required.
Link-Based Mode: Prioritizes pages based on the number of outgoing links, suitable for broad data collection.
💾 Periodic Crawler State Saving: Supports robust crawling by periodically saving the crawler's state. This allows for resuming crawls from the last interruption point, preventing data loss and ensuring efficient operation, even during long-running tasks.
📊 Data Browsing and Visualization: Includes intuitive tools for browsing crawled data and visualizing the crawling progress and effectiveness. This provides real-time monitoring and allows for immediate assessment of the data quality.
🔗 Seamless DCLM Framework Integration: Designed for direct integration with the DCLM (Deep Learning Model) pre-training framework. This streamlines the data pipeline, enabling crawled data to be immediately used for LLM pre-training, minimizing data transfer and processing overhead. Technical Detail: Facilitates efficient data flow and reduces the complexity of integrating the crawler with the training process.
⚖️ Reduced Website Load: Intelligently filters target web pages, minimizing the pressure on website servers and promoting ethical and compliant crawling practices.
Technical Architecture (brief overview):
Crawl4LLM's intelligence comes from its core components:
Pre-trained Impact Scoring: The DCLM fastText model is used to score web page content. This model assesses content quality, relevance, and other factors to determine a page's value for LLM training.
Priority Queue Scheduling: A priority queue is used to manage the crawling process. Pages with higher impact scores are prioritized, ensuring that the most valuable data is collected first.
Multi-Dimensional Data Evaluation: The system considers various metrics, including content length, link count, and the impact score, to provide a holistic assessment of each web page.
Simulation and Optimization: Extensive simulations were used to validate the algorithm's effectiveness and to fine-tune parameters for optimal crawling performance.
Use Cases:
Large-Scale LLM Pre-training: Accelerate the creation of high-quality training datasets for LLMs. For instance, a research team developing a new conversational AI model can use Crawl4LLM to efficiently gather relevant text data from the web, reducing training time and improving model performance.
Targeted Dataset Construction: Build specialized datasets focused on specific domains or topics. A team building a medical LLM could use Crawl4LLM to focus on collecting data from reputable medical websites and publications, ensuring the dataset is highly relevant to the target domain.
Enhanced Search Engine Indexing: Improve the quality of data used for search engine indexing. By prioritizing high-value pages, Crawl4LLM can help search engines identify and index the most relevant and informative content, leading to better search results.
Network Monitoring and Analysis: By identifying valuable data, Crawl4LLM can efficiently gather and analyze information from various sources.
Conclusion:
Crawl4LLM offers a significant advancement in web crawling for LLM pre-training. Its intelligent web page selection, flexible crawling modes, and seamless integration with the DCLM framework provide a powerful and efficient solution for researchers and developers seeking to build high-quality LLM datasets. By prioritizing data quality and minimizing resource waste, Crawl4LLM empowers users to train more effective LLMs in less time.
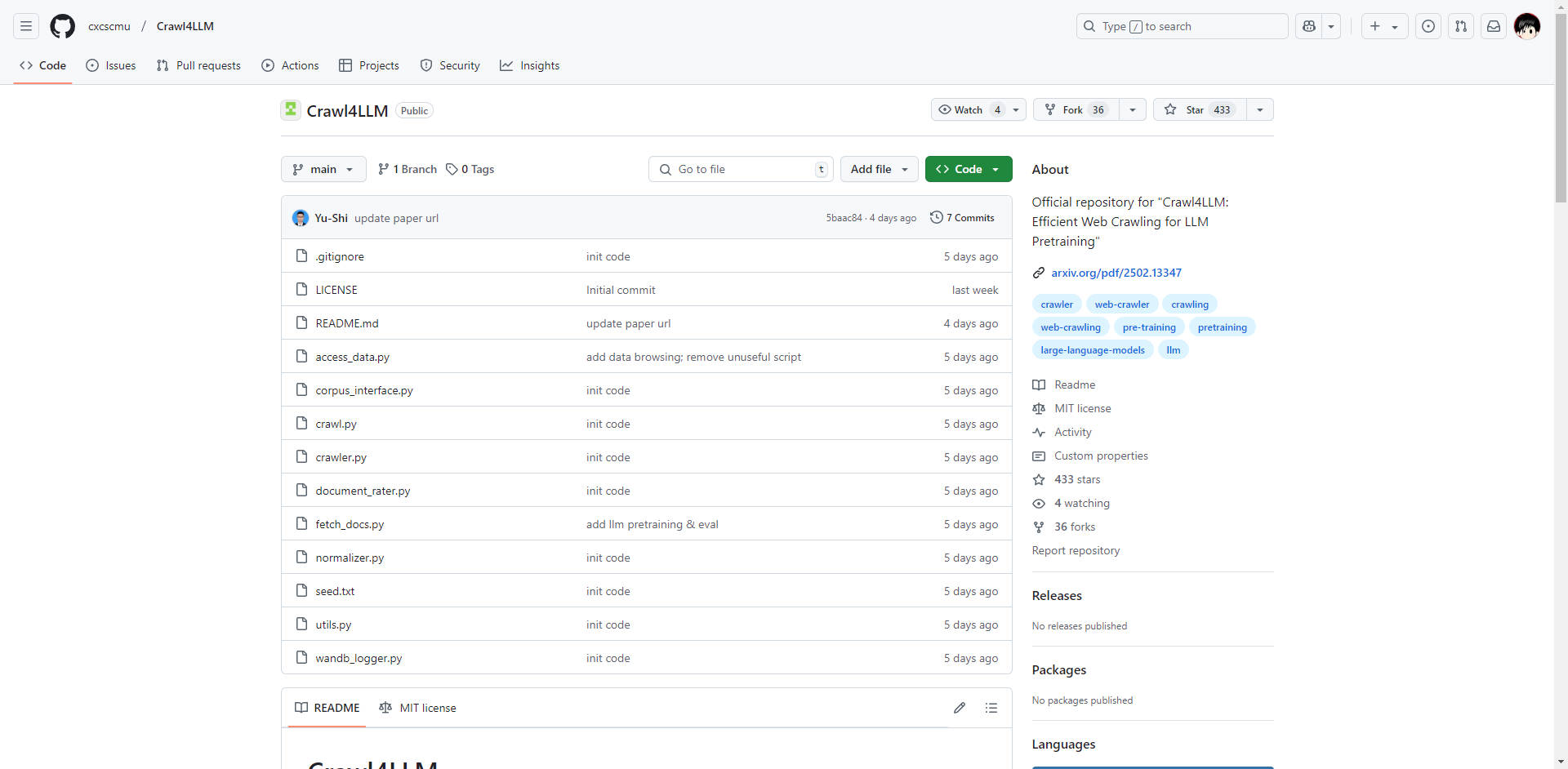
More information on Crawl4LLM
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Crawl4LLM was manually vetted by our editorial team and was first featured on 2025-02-24.
Related Searches
Crawl4LLM Alternatives
Load more Alternatives-

This is a zero-latency web crawler especially designed for retrieval-based LLM development
-

-

-

-