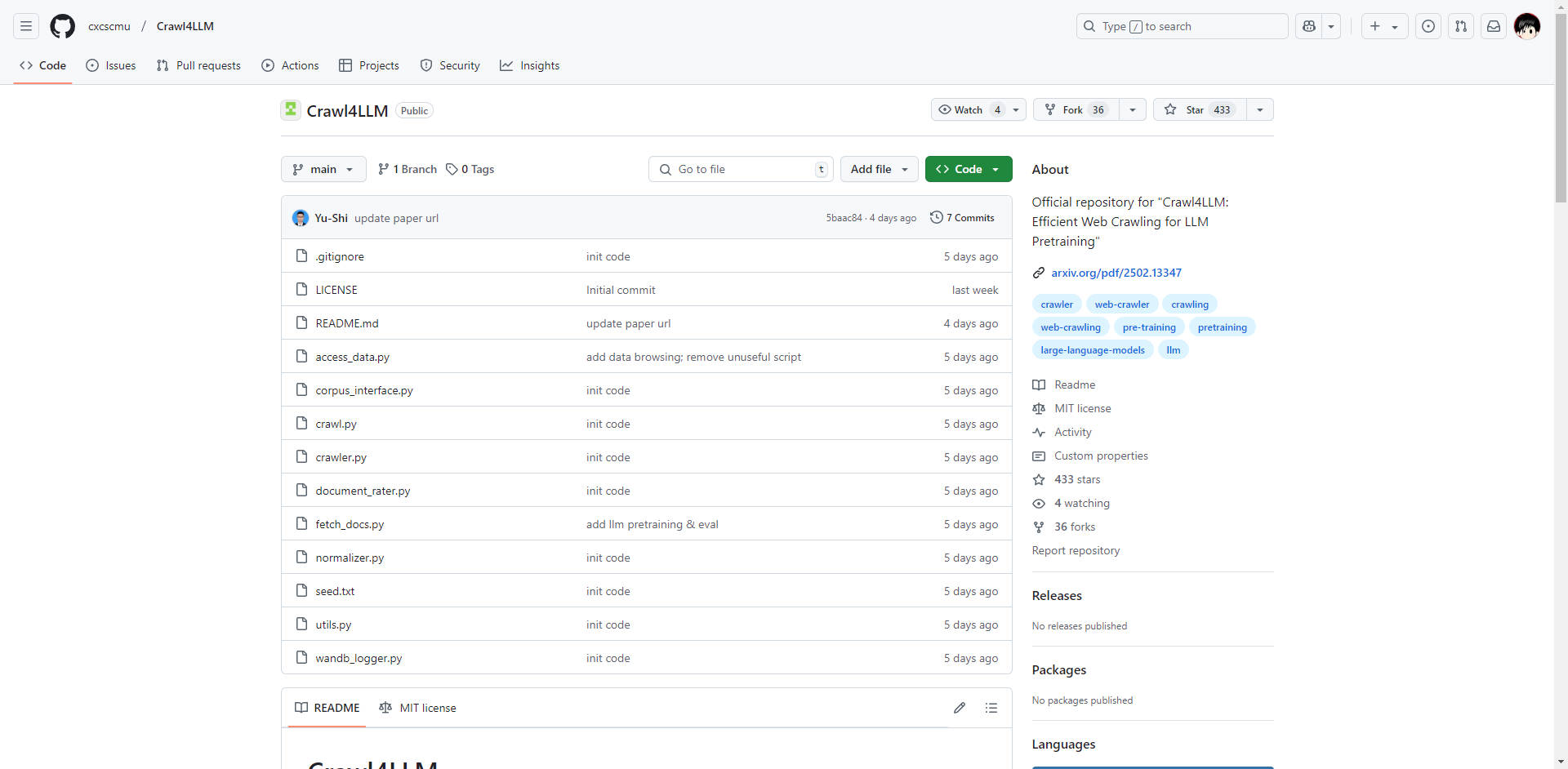
What is Crawl4LLM?
大規模言語モデル(LLM)の時代において、データ収集の質と効率は極めて重要です。従来のウェブクローラーは、ウェブの膨大な量に苦戦し、リソースの浪費や最適とは言えないトレーニングデータセットにつながることがよくあります。清華大学とカーネギーメロン大学の共同オープンソースプロジェクトであるCrawl4LLMは、この課題に直接取り組みます。これは、LLMの事前トレーニングのために、価値の高いウェブページの収集を優先するように設計されたインテリジェントなウェブクローリングシステムであり、データ収集効率をほぼ5倍に向上させます。
主な機能:
🤖 インテリジェントなウェブページ選択: 事前トレーニングされたインパクトスコアリングシステム(DCLM fastTextモデルを利用)を採用し、ウェブページコンテンツの価値をクロール前に評価します。これにより、価値の高いページが優先され、無関係または低品質のデータの収集を最小限に抑えます。技術的な詳細:スコアリングでは、コンテンツの品質、関連性、およびその他の指標を考慮し、LLMトレーニングに対するページの有用性を包括的に評価します。
⚙️ 複数のクローリングモード: さまざまなデータ収集のニーズに対応するための柔軟性を提供します。
インテリジェントモード: ウェブページの価値スコアに基づいてクローリング戦略を動的に調整します。これは、効率を最大化するためのコアモードです。
ランダムモード: ターゲットデータが不要なシナリオ向けに、従来のクローラーと同様のベースラインクローリングアプローチを提供します。
リンクベースモード: 発信リンクの数に基づいてページを優先し、広範なデータ収集に適しています。
💾 定期的なクローラ状態の保存: クローラの状態を定期的に保存することにより、堅牢なクローリングをサポートします。これにより、中断された最後の時点からクロールを再開できるため、データ損失を防ぎ、長時間のタスクでも効率的な動作を保証します。
📊 データの閲覧と可視化: クロールされたデータを閲覧し、クローリングの進捗状況と効果を可視化するための直感的なツールが含まれています。これにより、リアルタイム監視が可能になり、データ品質を即座に評価できます。
🔗 シームレスなDCLMフレームワークの統合: DCLM(Deep Learning Model)事前トレーニングフレームワークとの直接統合のために設計されています。これにより、データパイプラインが効率化され、クロールされたデータをLLMの事前トレーニングにすぐに使用できるようになり、データ転送と処理のオーバーヘッドが最小限に抑えられます。技術的な詳細:効率的なデータフローを促進し、クローラーとトレーニングプロセスの統合の複雑さを軽減します。
⚖️ ウェブサイトの負荷軽減: ターゲットウェブページをインテリジェントにフィルタリングし、ウェブサイトサーバーへの負荷を最小限に抑え、倫理的でコンプライアンスに準拠したクローリングプラクティスを推進します。
技術アーキテクチャ(概要):
Crawl4LLMのインテリジェンスは、そのコアコンポーネントから生まれます。
事前トレーニングされたインパクトスコアリング: DCLM fastTextモデルは、ウェブページコンテンツをスコアリングするために使用されます。このモデルは、コンテンツの品質、関連性、その他の要素を評価して、LLMトレーニングに対するページの価値を判断します。
優先度キューのスケジューリング: 優先度キューは、クローリングプロセスを管理するために使用されます。インパクトスコアの高いページが優先され、最も価値のあるデータが最初に収集されるようにします。
多次元データ評価: システムは、コンテンツの長さ、リンク数、インパクトスコアなどのさまざまなメトリックを考慮して、各ウェブページの全体的な評価を提供します。
シミュレーションと最適化: アルゴリズムの有効性を検証し、最適なクローリングパフォーマンスのためにパラメータを微調整するために、広範なシミュレーションが使用されました。
ユースケース:
大規模LLM事前トレーニング: LLM用の高品質トレーニングデータセットの作成を加速します。たとえば、新しい会話型AIモデルを開発している研究チームは、Crawl4LLMを使用してウェブから関連するテキストデータを効率的に収集し、トレーニング時間を短縮し、モデルのパフォーマンスを向上させることができます。
ターゲットを絞ったデータセットの構築: 特定のドメインまたはトピックに焦点を当てた専門的なデータセットを構築します。医療LLMを構築しているチームは、Crawl4LLMを使用して、評判の良い医療ウェブサイトや出版物からのデータの収集に焦点を当て、データセットがターゲットドメインに高度に関連していることを保証できます。
検索エンジンのインデックス作成の強化: 検索エンジンのインデックス作成に使用されるデータの品質を向上させます。Crawl4LLMは、価値の高いページを優先することで、検索エンジンが最も関連性の高い有益なコンテンツを特定してインデックスを作成するのに役立ち、より良い検索結果につながります。
ネットワークの監視と分析: Crawl4LLMは、価値のあるデータを特定することで、さまざまなソースから情報を効率的に収集および分析できます。
結論:
Crawl4LLMは、LLM事前トレーニングのためのウェブクローリングにおいて大きな進歩をもたらします。そのインテリジェントなウェブページ選択、柔軟なクローリングモード、およびDCLMフレームワークとのシームレスな統合は、高品質のLLMデータセットを構築しようとしている研究者や開発者に強力で効率的なソリューションを提供します。Crawl4LLMは、データ品質を優先し、リソースの無駄を最小限に抑えることにより、ユーザーがより短い時間でより効果的なLLMをトレーニングできるようにします。
More information on Crawl4LLM
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Crawl4LLM was manually vetted by our editorial team and was first featured on 2025-02-24.
Related Searches