What is Crawl4LLM?
在大语言模型 (LLM) 时代,数据采集的质量和效率至关重要。传统的网络爬虫往往难以应对海量网络信息,导致资源浪费和训练数据集欠佳。Crawl4LLM 是由清华大学和卡内基梅隆大学合作开发的开源项目,旨在直接解决这一难题。它是一种智能网络爬取系统,专门用于优先收集对 LLM 预训练具有高价值的网页,从而将数据采集效率提高了近 5 倍。
主要特性:
🤖 智能网页选择: 采用预训练的影响力评分系统(利用 DCLM fastText 模型)在爬取之前评估网页内容的价值。这可以优先选择高价值页面,最大限度地减少无关或低质量数据的收集。技术细节: 评分会考虑内容质量、相关性和其他指标,从而全面评估页面对 LLM 训练的有用性。
⚙️ 多种爬取模式: 提供灵活性,以适应各种数据采集需求:
智能模式: 根据网页价值评分动态调整爬取策略。这是最大限度提高效率的核心模式。
随机模式: 提供类似于传统爬虫的基准爬取方法,适用于不需要目标数据的场景。
基于链接的模式: 根据传出链接的数量对页面进行优先级排序,适用于广泛的数据收集。
💾 定期爬虫状态保存: 通过定期保存爬虫的状态来支持稳健的爬取。这允许从上次中断点恢复爬取,防止数据丢失并确保高效运行,即使在长时间运行的任务期间也是如此。
📊 数据浏览和可视化: 包括用于浏览爬取的数据和可视化爬取进度和有效性的直观工具。这提供了实时监控,并允许立即评估数据质量。
🔗 无缝 DCLM 框架集成: 专为与 DCLM(深度学习模型)预训练框架直接集成而设计。这简化了数据管道,使爬取的数据能够立即用于 LLM 预训练,从而最大限度地减少数据传输和处理开销。技术细节: 促进高效的数据流,并降低将爬虫与训练过程集成的复杂性。
⚖️ 减少网站负载: 智能过滤目标网页,最大限度地减少网站服务器的压力,并促进合乎道德且合规的爬取实践。
技术架构(简要概述):
Crawl4LLM 的智能性来自其核心组件:
预训练的影响力评分: DCLM fastText 模型用于对网页内容进行评分。该模型评估内容质量、相关性和其他因素,以确定页面对 LLM 训练的价值。
优先级队列调度: 优先级队列用于管理爬取过程。具有较高影响力评分的页面将优先处理,确保首先收集最有价值的数据。
多维度数据评估: 该系统考虑各种指标,包括内容长度、链接计数和影响力评分,以提供对每个网页的整体评估。
模拟和优化: 广泛的模拟用于验证算法的有效性,并调整参数以获得最佳的爬取性能。
使用案例:
大规模 LLM 预训练: 加速为 LLM 创建高质量的训练数据集。例如,开发新型会话 AI 模型的研发团队可以使用 Crawl4LLM 从网络高效收集相关文本数据,从而缩短训练时间并提高模型性能。
有针对性的数据集构建: 构建专注于特定领域或主题的专业数据集。构建医学 LLM 的团队可以使用 Crawl4LLM 专注于从信誉良好的医学网站和出版物收集数据,确保数据集与目标领域高度相关。
增强的搜索引擎索引: 提高用于搜索引擎索引的数据质量。通过优先选择高价值页面,Crawl4LLM 可以帮助搜索引擎识别和索引最相关和信息丰富的内容,从而获得更好的搜索结果。
网络监控和分析: 通过识别有价值的数据,Crawl4LLM 可以有效地从各种来源收集和分析信息。
结论:
Crawl4LLM 在 LLM 预训练的网络爬取方面取得了重大进展。其智能网页选择、灵活的爬取模式以及与 DCLM 框架的无缝集成,为寻求构建高质量 LLM 数据集的研究人员和开发人员提供了强大而高效的解决方案。通过优先考虑数据质量并最大限度地减少资源浪费,Crawl4LLM 使使用者能够在更短的时间内训练出更有效的 LLM。
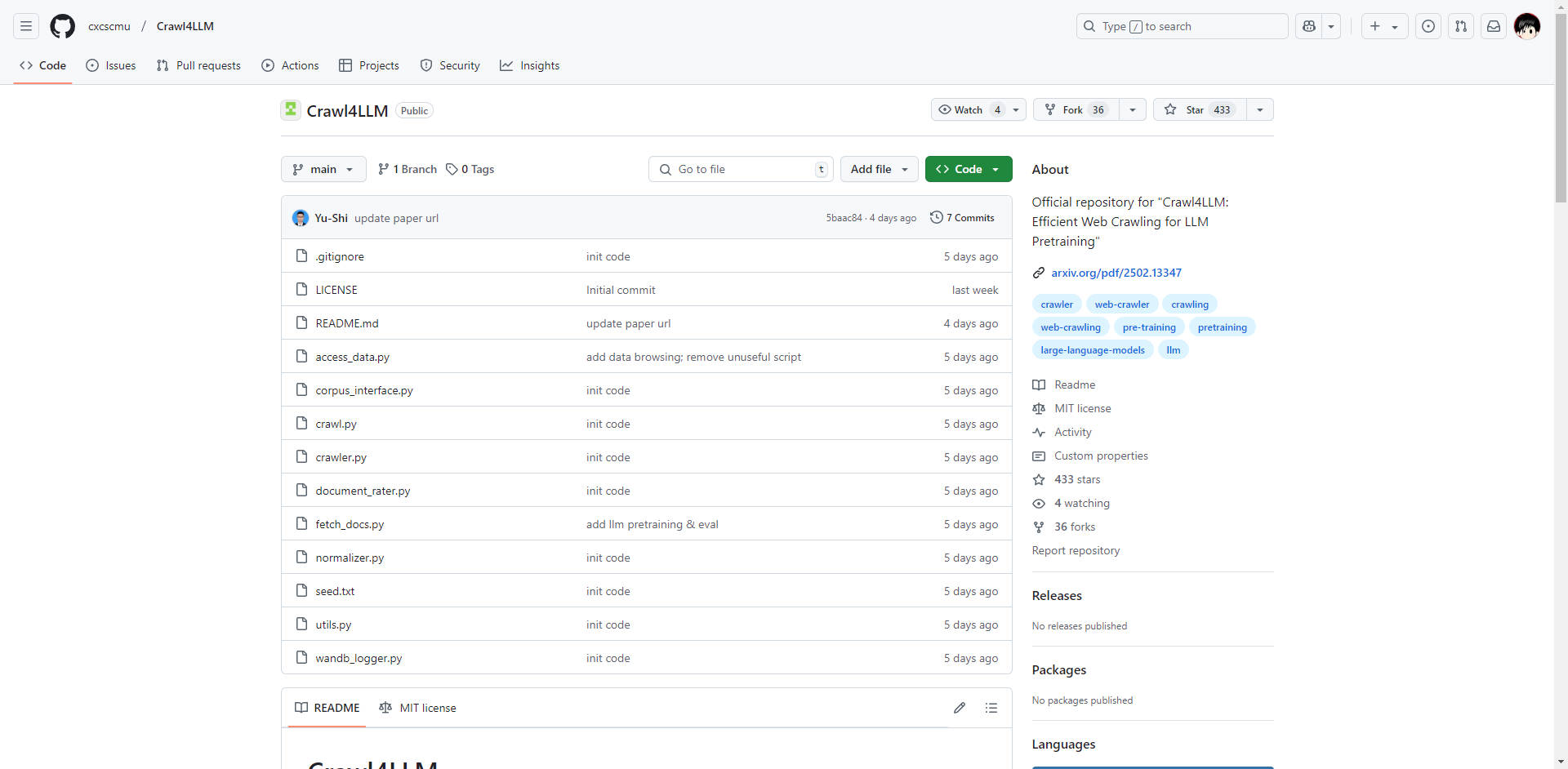
More information on Crawl4LLM
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Crawl4LLM was manually vetted by our editorial team and was first featured on 2025-02-24.
Related Searches