What is Flyte?
Flyte es el robusto orquestador de flujos de trabajo de código abierto, diseñado específicamente para la ingeniería de pipelines de datos y Machine Learning de nivel de producción a gran escala. Aprovechando la potencia de Kubernetes, Flyte resuelve el desafío crítico de garantizar la reproducibilidad y escalabilidad en entornos de procesamiento distribuido. Ofrece a los científicos de datos e ingenieros de ML una plataforma unificada y nativa de la nube para definir, ejecutar y gestionar de manera eficiente flujos de trabajo complejos y de múltiples etapas utilizando entornos de programación familiares como el Python SDK.
Características Clave
Flyte está diseñado para trasladar sus modelos y transformaciones de datos sin interrupciones del desarrollo a entornos de producción fiables y a gran escala.
🛡️ Reproducibilidad Garantizada y Linaje de Datos
Flyte impone la inmutabilidad en todas las ejecuciones, lo que significa que el estado de cualquier ejecución de pipeline no puede ser alterado, garantizando que sus resultados sean completamente reproducibles en todo momento. Además, la plataforma rastrea automáticamente el Linaje de Datos, lo que le permite rastrear el movimiento y el historial de transformación de los datos a lo largo de todo el ciclo de vida del flujo de trabajo, algo crucial para la auditoría y depuración.
🚀 Interfaces Fuertemente Tipadas y Barreras de Protección de Datos
A diferencia de los planificadores básicos, Flyte incorpora un robusto motor de tipos. Al definir barreras de protección de datos utilizando los tipos de Flyte, usted valida sus datos en cada paso del flujo de trabajo. Esto previene errores de tipo en tiempo de ejecución, impone la consistencia y asegura la integridad de los datos en pipelines complejos y de múltiples etapas, aumentando la fiabilidad general.
🐳 Control y Aislamiento de Recursos Nativos de la Nube
Flyte está diseñado para la computación distribuida, utilizando contenedores para proporcionar aislamiento de dependencias para cada tarea, eliminando conflictos de dependencias entre las diferentes etapas de su pipeline. Puede asignar dinámicamente recursos específicos —incluida la aceleración por GPU— a nivel de tarea, e incluso programar flujos de trabajo en instancias Spot o preemptibles de bajo costo.
🔁 Control de Ejecución Granular y Recuperación de Fallos
Acelere sus ciclos de iteración con controles de ejecución avanzados. Si un pipeline de múltiples etapas falla, Flyte le permite recuperar solo las tareas fallidas en lugar de reiniciar todo el flujo de trabajo. También puede volver a ejecutar una única tarea al nivel más granular sin modificar el estado anterior, reduciendo significativamente el tiempo de depuración y el desperdicio computacional.
🌐 Soporte Multi-Lenguaje y Multi-Entorno
Aunque ofrece SDKs completos para Python, Java, Scala y JavaScript, Flyte también soporta código escrito en cualquier lenguaje utilizando contenedores raw. Esta flexibilidad garantiza que pueda consolidar diversas tareas computacionales bajo una única capa de orquestación, desplegable en AWS, GCP, Azure o en clústeres de Kubernetes on-premises.
Casos de Uso
Flyte está diseñado para manejar escenarios complejos del mundo real a lo largo del ciclo de vida de datos y ML, garantizando la fiabilidad desde la experimentación hasta el despliegue.
- Puesta en Producción de la Sintonización Fina de Modelos de Lenguaje Grandes: Utilice la capacidad de Flyte para asignar y controlar recursos de GPU y su tipado fuerte para gestionar de forma fiable la compleja preparación de datos, el entrenamiento distribuido (por ejemplo, la sintonización fina de modelos como Code Llama) y el despliegue de modelos grandes, asegurando que el entorno de entrenamiento y los datos permanezcan consistentes en todas las ejecuciones.
- Previsión y Análisis de Datos Escalables: Orqueste trabajos masivos de procesamiento de datos que requieran marcos de computación distribuida como Spark o Horovod. Las tareas de mapeo de Flyte y su paralelismo inherente le permiten escalar eficientemente las computaciones, como la previsión de ventas o la consulta compleja de secuencias de nucleótidos, minimizando la sobrecarga de configuración y maximizando el rendimiento.
- Promoción Simplificada de Desarrollo a Producción: Gestione todo el ciclo de vida de MLOps con facilidad. Flyte simplifica la transición de un entorno de desarrollo o staging a producción tanto como cambiar la configuración del dominio, proporcionando una ruta estable y versionada para desplegar flujos de trabajo sin reestructurar el código subyacente.
¿Por Qué Elegir Flyte?
Flyte se diferencia de los planificadores tradicionales al centrarse en los requisitos centrales de los flujos de trabajo modernos y complejos de datos y ML: confianza, flexibilidad y eficiencia operativa.
- Confianza Verificable a Través de la Inmutabilidad: Al imponer ejecuciones inmutables y proporcionar linaje de datos automático, Flyte garantiza que cada ejecución de pipeline sea auditable y reproducible. Este nivel de fiabilidad intrínseca es fundamental para aplicaciones de misión crítica donde los resultados deben ser consistentes.
- Flujos de Trabajo Adaptables y Dinámicos: Consiga una flexibilidad superior con características como los Dynamic Workflows (que pueden cambiar la estructura de ejecución basándose en datos en tiempo de ejecución), el Branching (ejecutando selectivamente partes del flujo de trabajo) y la capacidad de esperar entradas externas antes de proceder. Esto permite que sus pipelines se adapten a entradas en tiempo real y a requisitos de negocio cambiantes.
- Eficiencia Operativa y Control de Costos: Reduzca los costos operativos y el tiempo de obtención de resultados. Al permitir el almacenamiento en caché a nivel de tarea, la recuperación de fallos que solo afecta a las tareas fallidas y la capacidad de aprovechar instancias preemptibles rentables, Flyte optimiza tanto el tiempo del desarrollador como el gasto en la nube.
Conclusión
Flyte proporciona la estructura, fiabilidad y escalabilidad necesarias para transformar código experimental de ciencia de datos en pipelines robustos y listos para producción. Al priorizar la reproducibilidad, el tipado fuerte y el control granular sobre los recursos distribuidos, Flyte empodera a los equipos para que se centren en la innovación en lugar de en la complejidad de la infraestructura.
Explore la documentación completa y los tutoriales para ver cómo Flyte puede revolucionar la orquestación de sus flujos de trabajo de datos y ML.
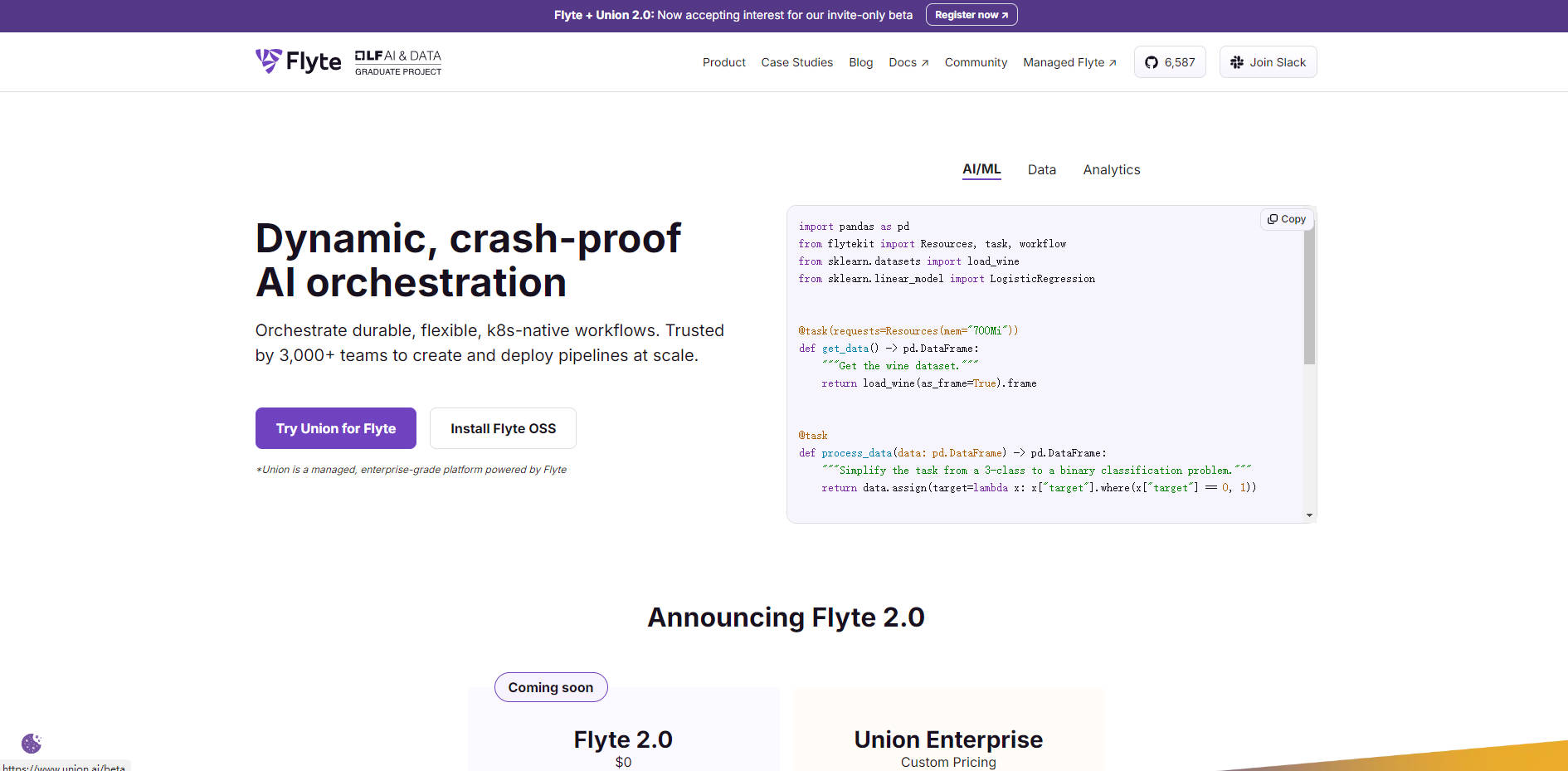
More information on Flyte
Launched
2016-07
Pricing Model
Free
Starting Price
Global Rank
776413
Follow
Month Visit
36.1K
Tech used
Top 5 Countries
22.6%
12.73%
9.31%
8.33%
6.48%
United States
France
Vietnam
Russia
India
Traffic Sources
4.59%
0.87%
0.11%
10.27%
49.99%
34.03%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Nov 15, 2025)
Flyte was manually vetted by our editorial team and was first featured on 2025-11-15.