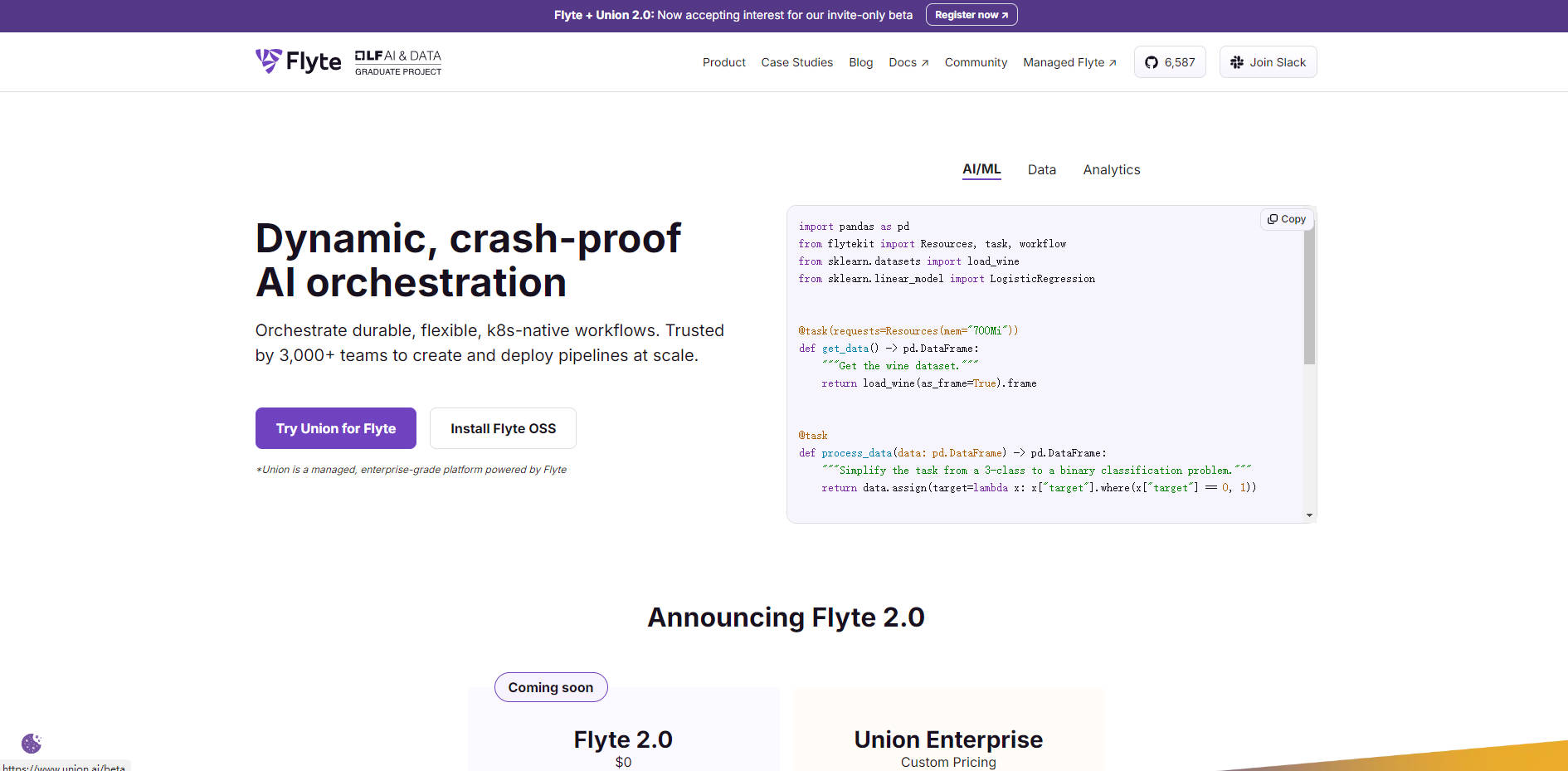
What is Flyte?
Flyte 是一個強大、開源的工作流程編排工具,專為大規模建構生產級資料和機器學習管線而設計。借助 Kubernetes 的強大功能,Flyte 解決了在分散式處理環境中確保可重現性和可擴展性的關鍵挑戰。它為資料科學家和機器學習工程師提供了一個統一的雲原生平台,讓他們能夠使用熟悉的程式設計環境(例如 Python SDK)來定義、執行並有效管理複雜的多階段工作流程。
主要功能
Flyte 旨在將您的模型和資料轉換從開發環境無縫推動到可靠的大規模生產環境。
🛡️ 保證可重現性與資料血緣
Flyte 對所有執行強制執行不可變性,這表示任何管線執行的狀態都不能被更改,確保您的結果每次都完全可重現。此外,該平台自動追蹤資料血緣,讓您能夠追蹤資料在整個工作流程生命週期中的移動和轉換歷史,這對於稽核和偵錯至關重要。
🚀 強型別介面與資料防護欄
與基本的排程器不同,Flyte 整合了一個強大的型別引擎。透過使用 Flyte 型別定義資料防護欄,您可以在工作流程的每個步驟驗證您的資料。這可以防止執行時型別錯誤,確保一致性,並保障複雜多階段管線中的資料完整性,從而提高整體可靠性。
🐳 雲原生資源控制與隔離
Flyte 專為分散式運算而設計,利用容器為每個任務提供依賴隔離,消除管線不同階段之間的依賴衝突。您可以在任務層級動態分配特定資源,包括 GPU 加速,甚至可以在節省成本的 Spot 或搶佔式執行個體上排程工作流程。
🔁 精細執行控制與故障恢復
透過進階執行控制加速您的迭代週期。如果多階段管線失敗,Flyte 讓您能夠只恢復失敗的任務,而不是重新啟動整個工作流程。您也可以在最細微的層級重新執行單一任務,而無需修改先前的狀態,大幅減少偵錯時間和計算浪費。
🌐 多語言與多環境支援
Flyte 提供針對 Python、Java、Scala 和 JavaScript 的完整 SDK,同時也支援使用原始容器編寫的*任何*語言程式碼。這種靈活性確保您可以將多樣化的運算任務整合在單一編排層之下,並可部署到 AWS、GCP、Azure 或內部部署的 Kubernetes 叢集。
使用案例
Flyte 旨在處理資料和機器學習生命週期中複雜的實際場景,確保從實驗到部署的可靠性。
- 大型語言模型微調的生產化:利用 Flyte 分配和控制 GPU 資源的能力及其強型別特性,可靠地管理複雜的資料準備、分散式訓練(例如微調 Code Llama 等模型)以及大型模型的部署,確保訓練環境和資料在不同執行中保持一致。
- 可擴展的資料預測與分析:編排需要 Spark 或 Horovod 等分散式運算框架的大規模資料處理任務。Flyte 的映射任務和內在的平行處理能力讓您能夠有效率地擴展運算,例如銷售預測或複雜核苷酸序列查詢,在最大化吞吐量的同時,將設定開銷降到最低。
- 簡化從開發到生產的推廣:輕鬆管理整個 MLOps 生命週期。Flyte 讓從開發或預備環境轉移到生產環境,就像改變網域設定一樣簡單,提供穩定、版本化的路徑來部署工作流程,而無需重構底層程式碼。
為何選擇 Flyte?
Flyte 透過專注於現代複雜資料和機器學習工作流程的核心需求——信任、彈性與營運效率,使自己區別於傳統排程器。
- 透過不可變性建立可驗證的信任:透過強制執行不可變的執行並提供自動資料血緣,Flyte 確保每次管線執行都可稽核且可重現。這種內在的可靠性對於結果必須一致的關鍵任務應用程式至關重要。
- 適應性與動態工作流程:透過動態工作流程(可根據執行時資料改變執行結構)、分支(選擇性執行工作流程的部分)以及在繼續之前等待外部輸入的能力,實現卓越的靈活性。這讓您的管線能夠適應即時輸入和不斷變化的業務需求。
- 營運效率與成本控制:降低營運成本和達成結果的時間。透過任務層級快取、只針對失敗任務的故障恢復,以及利用具成本效益的搶佔式執行個體的能力,Flyte 優化了開發人員時間和雲端支出。
結論
Flyte 提供了將實驗性資料科學程式碼轉變為強大、可投入生產的管線所需的結構、可靠性和可擴展性。透過優先考慮可重現性、強型別和對分散式資源的精細控制,Flyte 賦予團隊專注於創新,而非基礎設施複雜性的能力。
探索全面的文件和教學,了解 Flyte 如何徹底改變您的資料和機器學習工作流程編排。
More information on Flyte
Launched
2016-07
Pricing Model
Free
Starting Price
Global Rank
776413
Follow
Month Visit
36.1K
Tech used
Top 5 Countries
22.6%
12.73%
9.31%
8.33%
6.48%
United States
France
Vietnam
Russia
India
Traffic Sources
4.59%
0.87%
0.11%
10.27%
49.99%
34.03%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Nov 15, 2025)
Flyte was manually vetted by our editorial team and was first featured on 2025-11-15.