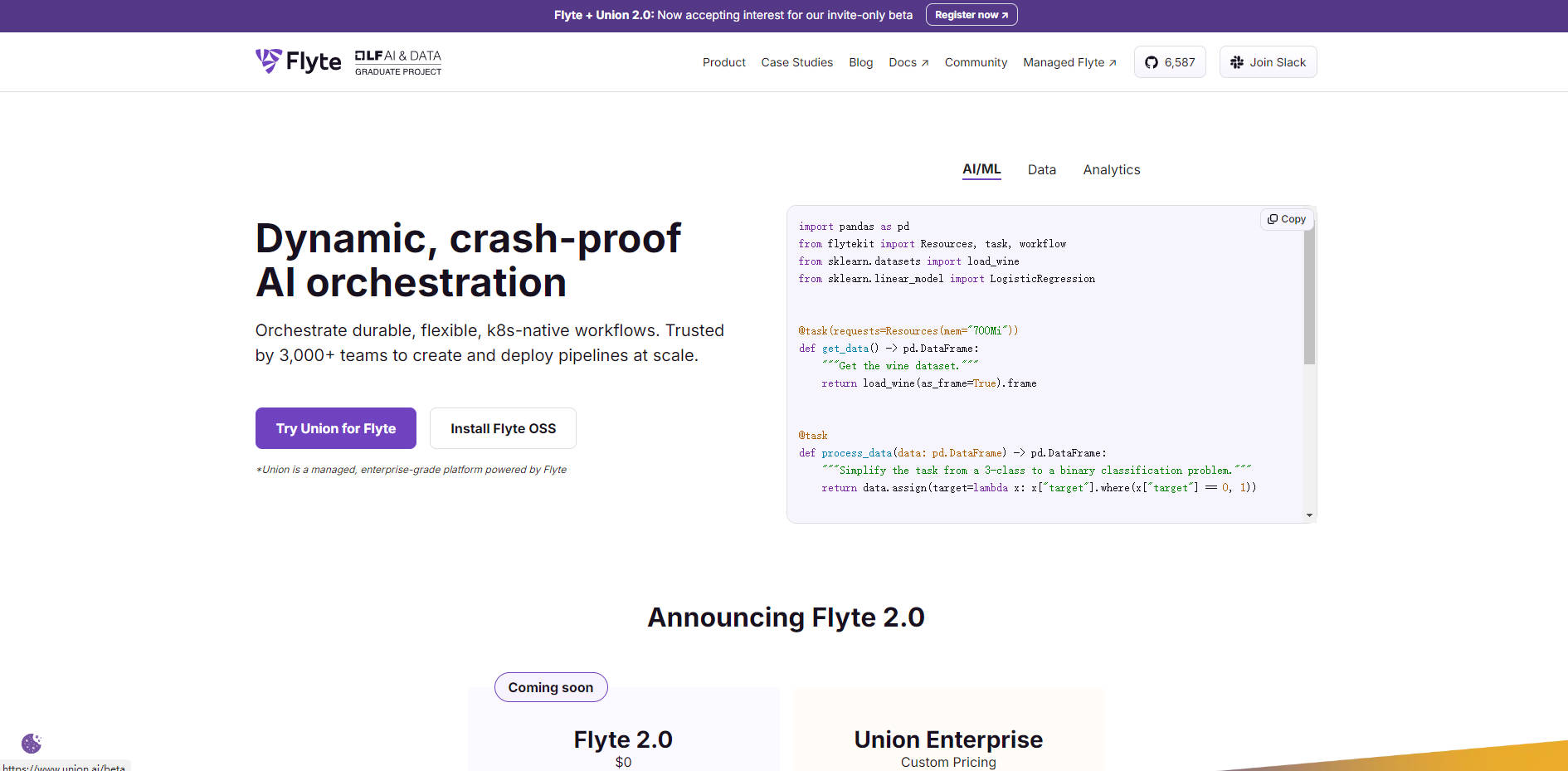
What is Flyte?
Flyte is the robust, open-source workflow orchestrator built specifically for engineering production-grade data and Machine Learning pipelines at scale. Leveraging the power of Kubernetes, Flyte solves the critical challenge of ensuring reproducibility and scalability in distributed processing environments. It provides data scientists and ML engineers with a unified, cloud-native platform to define, execute, and efficiently manage complex, multi-stage workflows using familiar programming environments like the Python SDK.
Key Features
Flyte is engineered to move your models and data transformations seamlessly from development into reliable, large-scale production environments.
🛡️ Guaranteed Reproducibility and Data Lineage
Flyte enforces immutability for all executions, meaning the state of any pipeline run cannot be altered, guaranteeing that your results are fully reproducible every time. Furthermore, the platform automatically tracks Data Lineage, allowing you to trace the movement and transformation history of data throughout the entire workflow lifecycle, which is crucial for auditing and debugging.
🚀 Strongly Typed Interfaces and Data Guardrails
Unlike basic schedulers, Flyte incorporates a robust type engine. By defining data guardrails using Flyte types, you validate your data at every step of the workflow. This prevents runtime type errors, enforces consistency, and ensures data integrity across complex, multi-stage pipelines, increasing overall reliability.
🐳 Cloud-Native Resource Control and Isolation
Flyte is designed for distributed computing, utilizing containers to provide dependency isolation for every task, eliminating dependency conflicts between different stages of your pipeline. You can dynamically allocate specific resources—including GPU acceleration—at the task level, and even schedule workflows on cost-saving Spot or preemptible instances.
🔁 Granular Execution Control and Failure Recovery
Accelerate your iteration cycles with advanced execution controls. If a multi-stage pipeline fails, Flyte enables you to recover only the failed tasks rather than restarting the entire workflow. You can also rerun a single task at the most granular level without modifying the previous state, significantly reducing debugging time and computational waste.
🌐 Multi-Language and Multi-Environment Support
While offering comprehensive SDKs for Python, Java, Scala, and JavaScript, Flyte also supports code written in any language using raw containers. This flexibility ensures that you can consolidate diverse computational tasks under a single orchestration layer, deployable across AWS, GCP, Azure, or on-premises Kubernetes clusters.
Use Cases
Flyte is designed to handle complex, real-world scenarios across the data and ML lifecycle, ensuring reliability from experimentation to deployment.
- Productionizing Large Language Model Fine-Tuning: Use Flyte’s ability to allocate and control GPU resources and its strong typing to reliably manage the complex data preparation, distributed training (e.g., fine-tuning models like Code Llama), and deployment of large models, ensuring that the training environment and data remain consistent across runs.
- Scalable Data Forecasting and Analysis: Orchestrate massive data processing jobs that require distributed computation frameworks like Spark or Horovod. Flyte’s map tasks and inherent parallelism allow you to efficiently scale out computations, such as sales forecasting or complex nucleotide sequence querying, minimizing configuration overhead while maximizing throughput.
- Simplified Development-to-Production Promotion: Manage the entire MLOps lifecycle with ease. Flyte makes the transition from a development or staging environment to production as simple as changing the domain setting, providing a stable, versioned path for deploying workflows without restructuring the underlying code.
Why Choose Flyte?
Flyte differentiates itself from traditional schedulers by focusing on the core requirements of modern, complex data and ML workflows: trust, flexibility, and operational efficiency.
- Verifiable Trust through Immutability: By enforcing immutable executions and providing automatic data lineage, Flyte ensures that every pipeline run is auditable and reproducible. This level of intrinsic reliability is foundational for mission-critical applications where results must be consistent.
- Adaptable and Dynamic Workflows: Achieve superior flexibility with features like Dynamic Workflows (which can change execution structure based on runtime data), Branching (selectively executing parts of the workflow), and the ability to wait for external inputs before proceeding. This allows your pipelines to adapt to real-time inputs and changing business requirements.
- Operational Efficiency and Cost Control: Reduce operational costs and time-to-result. By allowing task-level caching, failure recovery targeting only failed tasks, and the ability to leverage cost-effective preemptible instances, Flyte optimizes both developer time and cloud spend.
Conclusion
Flyte provides the structure, reliability, and scalability required to transform experimental data science code into robust, production-ready pipelines. By prioritizing reproducibility, strong typing, and granular control over distributed resources, Flyte empowers teams to focus on innovation rather than infrastructure complexity.
Explore the comprehensive documentation and tutorials to see how Flyte can revolutionize your data and ML workflow orchestration.
More information on Flyte
Launched
2016-07
Pricing Model
Free
Starting Price
Global Rank
776413
Follow
Month Visit
36.1K
Tech used
Top 5 Countries
22.6%
12.73%
9.31%
8.33%
6.48%
United States
France
Vietnam
Russia
India
Traffic Sources
4.59%
0.87%
0.11%
10.27%
49.99%
34.03%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Nov 15, 2025)
Flyte was manually vetted by our editorial team and was first featured on 2025-11-15.