
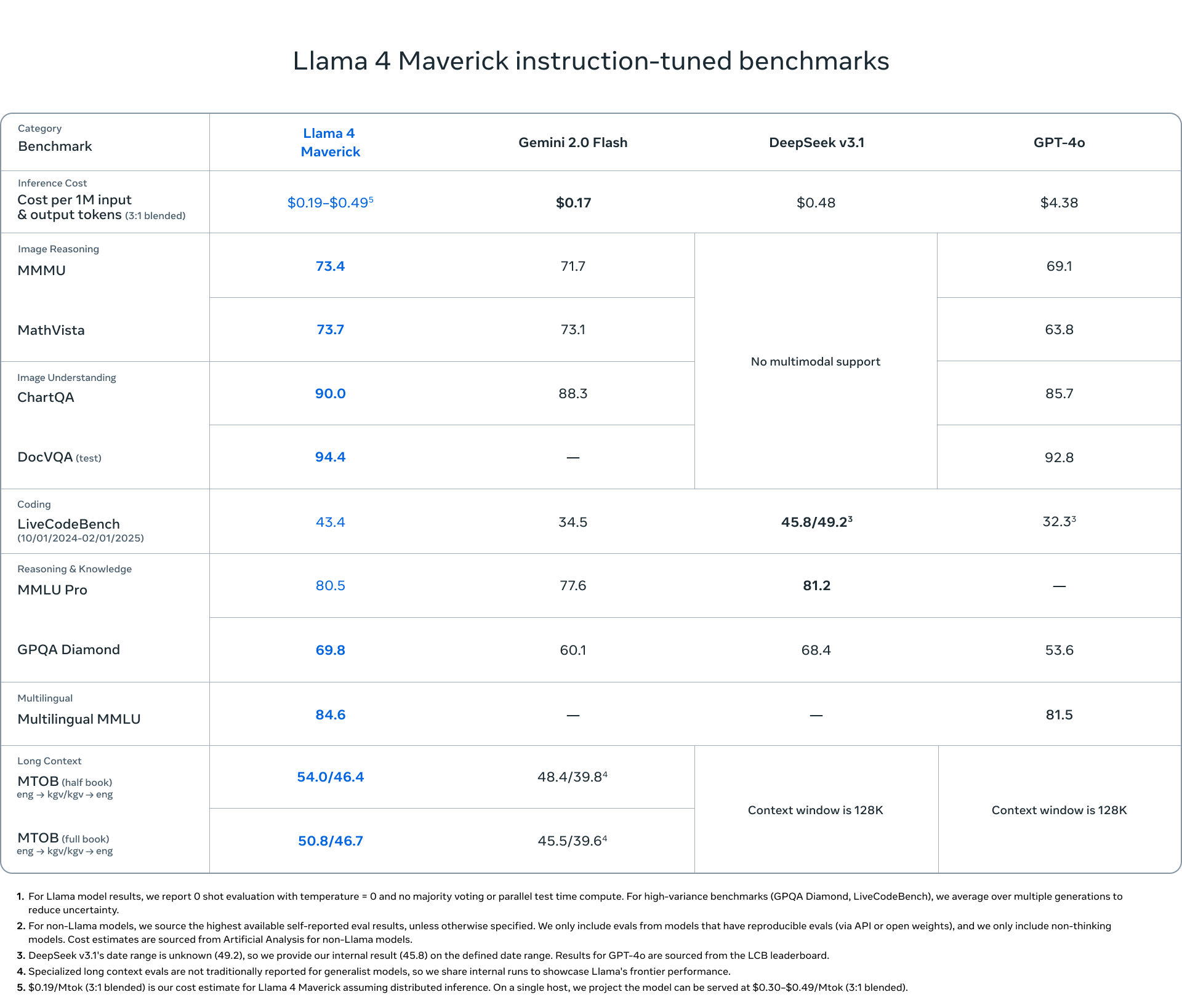
What is Llama 4?
Le damos la bienvenida a Llama 4, el siguiente paso en el viaje de Meta hacia la inteligencia artificial de código abierto. Esta nueva serie presenta modelos multimodales potentes diseñados para desarrolladores, investigadores y empresas que buscan tanto un alto rendimiento como eficiencia computacional. Por primera vez, los modelos Llama aprovechan una arquitectura Mixture of Experts (MoE), lo que los hace significativamente más rápidos y rentables de ejecutar y entrenar. Diseñado de forma nativa para comprender y generar contenido a través de texto, imágenes y video, Llama 4 ofrece versiones especializadas como Scout y Maverick, proporcionando soluciones personalizadas para diversas necesidades de aplicaciones de IA.
Características principales
💬 Comprensión y generación avanzada del lenguaje: Interpreta con precisión textos complejos y genera contenido coherente y consciente del contexto. Entrenado en vastos conjuntos de datos de texto (más de 30 billones de tokens en todas las modalidades), Llama 4 sobresale en tareas que van desde la escritura creativa y la composición detallada de artículos hasta interacciones de diálogo sofisticadas, comprendiendo la intención del usuario y proporcionando respuestas relevantes.
🖼️ Procesamiento multimodal nativo: Integra y razona sin problemas a través de entradas de texto, imágenes y video gracias a su arquitectura de fusión temprana. Llama 4 puede identificar objetos, escenas y colores dentro de las imágenes, proporcionando descripciones y análisis. La versión Scout supera los límites con una ventana de contexto de 10 millones de tokens, capaz de procesar documentos enormes (millones de palabras) o analizar más de 20 horas de contenido de video de una sola vez. Su codificador visual, basado en MetaCLIP, está específicamente ajustado para una mejor alineación con el modelo de lenguaje central.
⚡ Arquitectura MoE eficiente: Emplea un diseño de Mixture of Experts (MoE), el primero para la serie Llama, que permite una inferencia más rápida y un costo computacional reducido. En lugar de activar todo el modelo para cada tarea, MoE enruta las consultas a submodelos "expertos" especializados. Por ejemplo, Llama 4 Maverick tiene 400 mil millones de parámetros totales, pero solo activa 17 mil millones para una entrada dada, lo que reduce significativamente la latencia y los gastos operativos. Esta eficiencia se extiende al entrenamiento, donde técnicas como la precisión FP8 logran un alto rendimiento computacional (por ejemplo, 390 TFLOPs/GPU para el preentrenamiento de Behemoth) sin sacrificar la calidad.
🌍 Amplias capacidades multilingües: Pre-entrenado en datos que abarcan más de 200 idiomas, Llama 4 ofrece una sólida comprensión interlingüística, traducción y generación de contenido. Esto le permite crear aplicaciones que atienden a una audiencia global, rompiendo las barreras del idioma para las tareas de comunicación y procesamiento de información. También admite el ajuste fino de código abierto en conjuntos de datos de idiomas específicos.
Casos de uso
¿Cómo puede aprovechar Llama 4? Aquí hay algunos ejemplos:
Construcción de asistentes de investigación avanzados: Imagine alimentar a Llama 4 Scout con horas de conferencias grabadas, extensos trabajos de investigación que contienen texto y diagramas, o vastas bases de código. Su ventana de contexto de 10 millones de tokens le permite sintetizar información a través de estas extensas entradas, proporcionando resúmenes completos, respondiendo preguntas complejas basadas en el material o incluso identificando patrones dentro del código que un humano podría pasar por alto.
Desarrollo de chatbots multimodales atractivos: Utilice Llama 4 Maverick para potenciar un bot de servicio al cliente o un compañero creativo. Los usuarios podrían cargar imágenes de productos y hacer preguntas detalladas, que Maverick puede comprender visualmente y responder contextualmente. Su fortaleza en la escritura creativa también le permite generar narrativas atractivas, textos de marketing o historias personalizadas basadas en indicaciones del usuario que podrían incluir tanto texto como imágenes.
Creación de herramientas internas rentables: Implemente Llama 4 Scout (ejecutable en una sola GPU H100) para construir un motor de búsqueda de base de conocimiento interno para su empresa. Su arquitectura MoE garantiza un funcionamiento eficiente, lo que permite a los empleados encontrar rápidamente información en documentos, informes e incluso archivos de video internos de la empresa, sin incurrir en costos computacionales masivos.
Conclusión
Llama 4 marca un avance significativo para la IA accesible y de alto rendimiento. Al combinar la eficiencia de la arquitectura Mixture of Experts con la multimodalidad nativa y el amplio soporte multilingüe, Meta proporciona una base potente, flexible y de código abierto para su próximo proyecto de IA. Ya sea que necesite la inmensa ventana de contexto de Scout, las capacidades equilibradas y la agudeza de imagen de Maverick, o esté anticipando el poder especializado de Behemoth, Llama 4 ofrece opciones convincentes para construir aplicaciones de IA sofisticadas y eficientes.
Preguntas frecuentes (FAQ)
¿Cuáles son las principales diferencias entre Llama 4 y las versiones anteriores de Llama? Llama 4 introduce varios avances clave: es la primera serie Llama en utilizar una arquitectura Mixture of Experts (MoE) para una mayor eficiencia; es nativamente multimodal, diseñado desde cero para manejar texto, imágenes y video; ofrece versiones especializadas (Scout, Maverick) adaptadas para diferentes necesidades; Scout presenta una ventana de contexto excepcionalmente grande de 10 millones de tokens; y está entrenado en un conjunto de datos significativamente más grande y diverso (>30T tokens en más de 200 idiomas).
¿Qué es Mixture of Experts (MoE) y por qué es significativo en Llama 4? MoE es una arquitectura donde un modelo grande se compone de submodelos más pequeños y especializados llamados "expertos". Al procesar una entrada, el modelo enruta los datos solo a los expertos más relevantes, activando solo una fracción de los parámetros totales. Esto hace que la inferencia (ejecutar el modelo) sea significativamente más rápida y menos costosa computacionalmente en comparación con la activación de un modelo denso de tamaño total equivalente. Para Llama 4, esto significa menor latencia, costos de servicio reducidos y un entrenamiento más eficiente.
¿Qué modelo de Llama 4 debo elegir: Scout o Maverick?
Elija Llama 4 Scout si su necesidad principal es procesar contextos extremadamente largos (hasta 10 millones de tokens, como documentos muy largos, bases de código u horas de video) o si necesita un modelo altamente capaz que pueda ejecutarse de manera eficiente, incluso potencialmente en una sola GPU de alta gama como la H100.
Elija Llama 4 Maverick para aplicaciones de asistente o chatbot de propósito general donde un fuerte rendimiento en escritura creativa y una comprensión matizada de la imagen sean importantes. Ofrece un equilibrio de capacidades y se clasifica altamente en puntos de referencia generales de IA como LMSYS.
Llama 4 Behemoth (actualmente en vista previa) está siendo entrenado con 2 billones de parámetros y está mostrando una promesa excepcional en puntos de referencia STEM, apuntando a tareas de razonamiento altamente complejas.
¿Qué tan eficiente es técnicamente Llama 4 durante el entrenamiento y la inferencia? Llama 4 aprovecha varias técnicas para la eficiencia. La arquitectura MoE reduce drásticamente los parámetros activos durante la inferencia. Para el entrenamiento, Meta empleó la precisión FP8, logrando una alta utilización del hardware (por ejemplo, 390 TFLOPs por GPU durante el preentrenamiento de Behemoth) mientras mantiene la calidad del modelo. Meta también desarrolló un nuevo método llamado MetaP para optimizar los hiperparámetros de entrenamiento cruciales, asegurando la estabilidad y el rendimiento en diferentes escalas.
¿Es Llama 4 realmente de código abierto? Sí, Meta está lanzando los modelos Llama 4 bajo una licencia de código abierto, lo que permite a investigadores, desarrolladores y empresas acceder, modificar y construir sobre los modelos libremente, fomentando la innovación dentro de la comunidad de IA. Los modelos también admiten el ajuste fino de código abierto.

More information on Llama 4
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Llama 4 was manually vetted by our editorial team and was first featured on 2025-04-07.
Related Searches
Llama 4 Alternativas
Más Alternativas-
Descubre el máximo de la IA con Meta Llama 3, que ofrece un rendimiento, escalabilidad y mejoras posteriores al entrenamiento inigualables. Ideal para traducción, chatbots y contenido educativo. Eleva tu trayectoria en la IA con Llama 3.
-

LlamaIndex desarrolla agentes de IA inteligentes a partir de tus datos empresariales. Potencia los LLMs con RAG avanzado, transformando documentos complejos en conocimientos fiables y procesables.
-
MonsterGPT: Afina y despliega modelos de IA personalizados a través de chat. Simplifica tareas complejas de LLM e IA. Accede fácilmente a más de 60 modelos de código abierto.
-

-
