
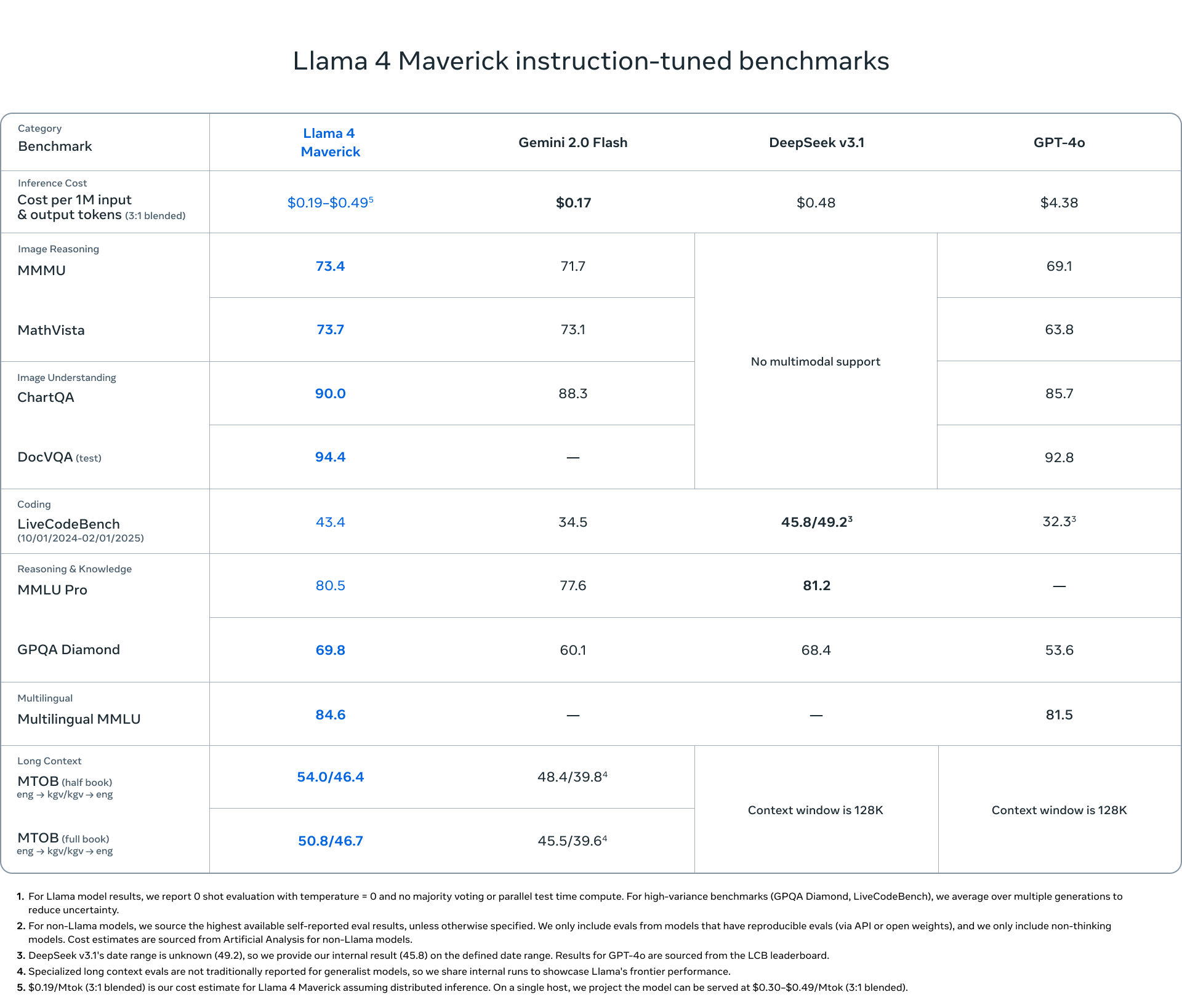
What is Llama 4?
欢迎来到 Llama 4,Meta 开源 AI 之旅的下一步。这一全新系列推出了强大的多模态模型,专为寻求高性能和计算效率的开发者、研究人员和企业而设计。Llama 模型首次采用 Mixture of Experts (MoE) 架构,使其运行和训练速度更快,成本效益更高。Llama 4 从一开始就被设计为能够理解和生成文本、图像和视频内容,并提供 Scout 和 Maverick 等专业版本,为多样化的 AI 应用需求提供定制化解决方案。
主要特性
💬 高级语言理解与生成: 能够准确解读复杂的文本,并生成连贯、具有上下文感知能力的内容。Llama 4 在海量文本数据集(跨模态超过 30 万亿个 token)上进行训练,擅长各种任务,包括创意写作、详细文章撰写以及复杂的对话互动,能够理解用户意图并提供相关响应。
🖼️ 原生多模态处理: 得益于其早期融合架构,能够无缝集成和推理文本、图像和视频输入。Llama 4 可以识别图像中的物体、场景和颜色,并提供描述和分析。Scout 版本凭借 1000 万 token 的上下文窗口,突破了界限,能够处理海量文档(数百万字)或一次性分析超过 20 小时的视频内容。其基于 MetaCLIP 的视觉编码器经过专门调整,可更好地与核心语言模型对齐。
⚡ 高效的 MoE 架构: 采用 Mixture of Experts (MoE) 设计,这在 Llama 系列中尚属首次,从而能够实现更快的推理速度并降低计算成本。MoE 不是为每个任务激活整个模型,而是将查询路由到专门的“专家”子模型。例如,Llama 4 Maverick 拥有 4000 亿个总参数,但对于给定的输入,仅激活 170 亿个参数,从而显著降低了延迟和运营费用。这种效率也扩展到训练,FP8 精度等技术可实现高计算吞吐量(例如,Behemoth 预训练的 GPU 为 390 TFLOPs),而不会牺牲质量。
🌍 广泛的多语言能力: Llama 4 在涵盖 200 多种语言的数据上进行预训练,提供强大的跨语言理解、翻译和内容生成能力。这使您可以构建面向全球受众的应用程序,打破语言障碍,从而促进沟通和信息处理任务。它还支持在特定语言数据集上进行开源微调。
用例
如何利用 Llama 4?以下是一些示例:
构建高级研究助手: 想象一下,将数小时的录音讲座、包含文本和图表的冗长研究论文或庞大的代码库输入 Llama 4 Scout。其 1000 万 token 的上下文窗口使其能够综合这些广泛输入中的信息,提供全面的摘要,根据材料回答复杂问题,甚至识别人类可能错过的代码中的模式。
开发引人入胜的多模态聊天机器人: 使用 Llama 4 Maverick 为客户服务机器人或创意助手提供支持。用户可以上传产品图片并提出详细问题,Maverick 可以通过视觉方式理解并根据上下文做出回应。它在创意写作方面的优势也使其能够根据可能包含文本和图像的用户提示生成引人入胜的叙述、营销文案或个性化故事。
创建具有成本效益的内部工具: 部署 Llama 4 Scout(可在单个 H100 GPU 上运行)来为您的公司构建内部知识库搜索引擎。它的 MoE 架构确保了高效运行,使员工能够快速查找公司文档、报告,甚至可能是内部视频档案中的信息,而不会产生巨大的计算成本。
结论
Llama 4 标志着易于访问、高性能 AI 的重大进步。通过将 Mixture of Experts 架构的效率与原生多模态和广泛的多语言支持相结合,Meta 为您的下一个 AI 项目提供了强大、灵活且开源的基础。无论您需要 Scout 的巨大上下文窗口、Maverick 的平衡能力和图像敏锐度,还是期待 Behemoth 的专业能力,Llama 4 都为构建复杂而高效的 AI 应用程序提供了引人注目的选择。
常见问题 (FAQ)
Llama 4 与之前的 Llama 版本的主要区别是什么? Llama 4 引入了多项关键改进:它是第一个使用 Mixture of Experts (MoE) 架构以提高效率的 Llama 系列;它是原生的多模态,从一开始就被设计为处理文本、图像和视频;它提供了针对不同需求量身定制的专业版本(Scout、Maverick);Scout 具有特别大的 1000 万 token 上下文窗口;并且它是在更大、更多样化的数据集(超过 30T token,跨越 200 多种语言)上进行训练的。
什么是 Mixture of Experts (MoE),为什么它在 Llama 4 中如此重要? MoE 是一种架构,其中大型模型由称为“专家”的较小、专门的子模型组成。在处理输入时,模型仅将数据路由到最相关的专家,仅激活总参数的一小部分。与激活同等总大小的密集模型相比,这使得推理(运行模型)的速度更快,计算成本更低。对于 Llama 4,这意味着更低的延迟、更低的Serving成本和更高效的训练。
我应该选择哪个 Llama 4 模型:Scout 还是 Maverick?
如果您的主要需求是处理极长的上下文(最多 1000 万个 token,如非常长的文档、代码库或数小时的视频),或者如果您需要一个能够高效运行的、功能强大的模型,甚至可以在像 H100 这样的单个高端 GPU 上运行,请选择 Llama 4 Scout。
对于通用助手或聊天机器人应用程序,在创意写作和细致的图像理解方面具有强大的性能非常重要,请选择 Llama 4 Maverick。它提供了能力的平衡,并在 LMSYS 等通用 AI 基准测试中名列前茅。
Llama 4 Behemoth (目前处于预览阶段)正在使用 2 万亿个参数进行训练,并在 STEM 基准测试中显示出非凡的前景,针对高度复杂的推理任务。
Llama 4 在训练和推理期间的技术效率如何? Llama 4 利用多种技术来提高效率。MoE 架构大大减少了推理期间的活动参数。在训练方面,Meta 采用 FP8 精度,在保持模型质量的同时实现了高硬件利用率(例如,在 Behemoth 预训练期间,每个 GPU 为 390 TFLOPs)。Meta 还开发了一种名为 MetaP 的新方法来优化关键训练超参数,从而确保不同规模的稳定性和性能。
Llama 4 真的开源吗? 是的,Meta 正在以开源许可证发布 Llama 4 模型,允许研究人员、开发人员和企业自由访问、修改和构建模型,从而促进 AI 社区内的创新。这些模型还支持开源微调。

More information on Llama 4
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Llama 4 was manually vetted by our editorial team and was first featured on 2025-04-07.
Related Searches
Llama 4 替代方案
更多 替代方案-
使用 Meta Llama 3 探索人工智能的巅峰,其特点是无与伦比的性能、可扩展性和训练后增强功能。非常适用于翻译、聊天机器人和教育内容。使用 Llama 3 提升您的 AI 之旅。
-

-
-

-
