
What is Llama 4?
歡迎使用 Llama 4,這是 Meta 開源 AI 之旅的下一步。這個全新的系列推出了強大的多模態模型,專為追求高效能和運算效率的開發者、研究人員和企業所設計。Llama 模型首次採用了 Mixture of Experts (MoE) 架構,使其在運行和訓練上都更加快速且更具成本效益。Llama 4 原生設計即具備理解和生成跨文字、圖像和影片內容的能力,並提供 Scout 和 Maverick 等特定版本,為多樣化的 AI 應用需求提供量身定制的解決方案。
主要特色
💬 進階的語言理解與生成能力: 能精準地解讀複雜的文字,並生成連貫且具備上下文意識的內容。Llama 4 在龐大的文字資料集(跨模態超過 30 兆個 tokens)上進行訓練,擅長處理從創意寫作、詳細的文章撰寫到複雜的對話互動等各種任務,能理解使用者的意圖並提供相關的回應。
🖼️ 原生多模態處理: 得益於其早期融合架構,能無縫整合並推理文字、圖像和影片輸入。Llama 4 能夠識別圖像中的物體、場景和顏色,並提供描述和分析。Scout 版本更將邊界推向極限,擁有 1000 萬個 token 的上下文窗口,能夠一次處理大量的文檔(數百萬字)或分析超過 20 小時的影片內容。其視覺編碼器基於 MetaCLIP,並經過特別調整,以更好地與核心語言模型對齊。
⚡ 高效的 MoE 架構: 採用 Mixture of Experts (MoE) 設計,這在 Llama 系列中尚屬首次,能實現更快的推論速度並降低運算成本。MoE 並非為每個任務都啟動整個模型,而是將查詢路由到專門的「專家」子模型。例如,Llama 4 Maverick 總共有 4000 億個參數,但對於給定的輸入,僅啟動 170 億個參數,從而顯著降低了延遲和營運費用。這種效率也延伸到訓練上,FP8 精度等技術可實現高運算吞吐量(例如,Behemoth 預訓練的每個 GPU 為 390 TFLOPs),同時又不犧牲品質。
🌍 廣泛的多語系能力: Llama 4 在涵蓋 200 多種語言的資料上進行預訓練,提供強大的跨語言理解、翻譯和內容生成能力。這讓您可以建構能滿足全球受眾需求的應用程式,打破語言障礙,促進溝通和資訊處理任務。它還支援在特定語言資料集上進行開源微調。
使用案例
您可以如何運用 Llama 4?以下是一些範例:
建構進階的研究助理: 想像一下,將 Llama 4 Scout 饋入數小時的錄音講座、包含文字和圖表的冗長研究論文,或龐大的程式碼庫。其 1000 萬個 token 的上下文窗口使其能夠綜合這些大量輸入中的資訊,提供全面的摘要、根據材料回答複雜的問題,甚至識別人類可能錯過的程式碼中的模式。
開發引人入勝的多模態聊天機器人: 使用 Llama 4 Maverick 來驅動客戶服務機器人或創意夥伴。使用者可以上傳產品圖片並提出詳細問題,Maverick 可以透過視覺方式理解並根據上下文做出回應。它在創意寫作方面的優勢也使其能夠根據可能包含文字和圖像的使用者提示,生成引人入勝的敘事、行銷文案或個人化故事。
建立具成本效益的內部工具: 部署 Llama 4 Scout(可在單個 H100 GPU 上運行),為您的公司建立內部知識庫搜尋引擎。其 MoE 架構可確保高效運行,使員工能夠快速找到公司文件、報告,甚至可能包括內部影片檔案中的資訊,而不會產生巨大的運算成本。
結論
Llama 4 標誌著易於使用的、高效能 AI 邁出了重要的一步。透過將 Mixture of Experts 架構的效率與原生多模態和廣泛的多語系支援相結合,Meta 為您的下一個 AI 專案提供了一個強大、靈活且開源的基礎。無論您需要 Scout 的巨大上下文窗口、Maverick 的平衡能力和圖像敏銳度,還是期待 Behemoth 的專業能力,Llama 4 都為建構複雜且高效的 AI 應用程式提供了引人注目的選項。
常見問題 (FAQ)
Llama 4 與之前的 Llama 版本之間的主要區別是什麼? Llama 4 引入了幾項關鍵改進:它是第一個使用 Mixture of Experts (MoE) 架構來提高效率的 Llama 系列;它是原生的多模態,從頭開始設計用於處理文字、圖像和影片;它提供針對不同需求量身定制的專用版本(Scout、Maverick);Scout 具有異常大的 1000 萬個 token 的上下文窗口;並且它在更大且更多樣化的資料集(跨 200 多種語言的 >30T tokens)上進行訓練。
什麼是 Mixture of Experts (MoE),為什麼它在 Llama 4 中如此重要? MoE 是一種架構,其中大型模型由稱為「專家」的較小、專用的子模型組成。在處理輸入時,模型僅將資料路由到最相關的專家,僅啟動總參數的一小部分。與啟動等效總大小的密集模型相比,這使得推論(運行模型)顯著更快且運算成本更低。對於 Llama 4 而言,這意味著更低的延遲、更低的服務成本和更高效的訓練。
我應該選擇哪個 Llama 4 模型:Scout 還是 Maverick?
如果您的主要需求是處理極長的上下文(最多 10M 個 tokens,例如非常長的文檔、程式碼庫或數小時的影片),或者您需要一個高效能的模型,該模型可以有效運行,甚至可以在像 H100 這樣的高階 GPU 上運行,請選擇 Llama 4 Scout。
對於創意寫作和細緻的圖像理解方面表現出色的通用助理或聊天機器人應用程式,請選擇 Llama 4 Maverick。它提供了能力的平衡,並且在 LMSYS 等通用 AI 基準測試中排名很高。
Llama 4 Behemoth (目前處於預覽階段)正在接受 2 兆參數的訓練,並且在 STEM 基準測試中顯示出非凡的潛力,目標是高度複雜的推理任務。
Llama 4 在訓練和推論期間的技術效率如何? Llama 4 利用多種技術來提高效率。MoE 架構大幅減少了推論期間的活動參數。在訓練方面,Meta 採用了 FP8 精度,在保持模型品質的同時實現了高硬體利用率(例如,在 Behemoth 預訓練期間,每個 GPU 為 390 TFLOPs)。Meta 還開發了一種稱為 MetaP 的新方法,用於優化關鍵訓練超參數,以確保不同規模的穩定性和效能。
Llama 4 真的開源嗎? 是的,Meta 正在以開源許可證發布 Llama 4 模型,允許研究人員、開發人員和企業自由地存取、修改和基於這些模型進行構建,從而促進 AI 社群內的創新。這些模型還支援開源微調。

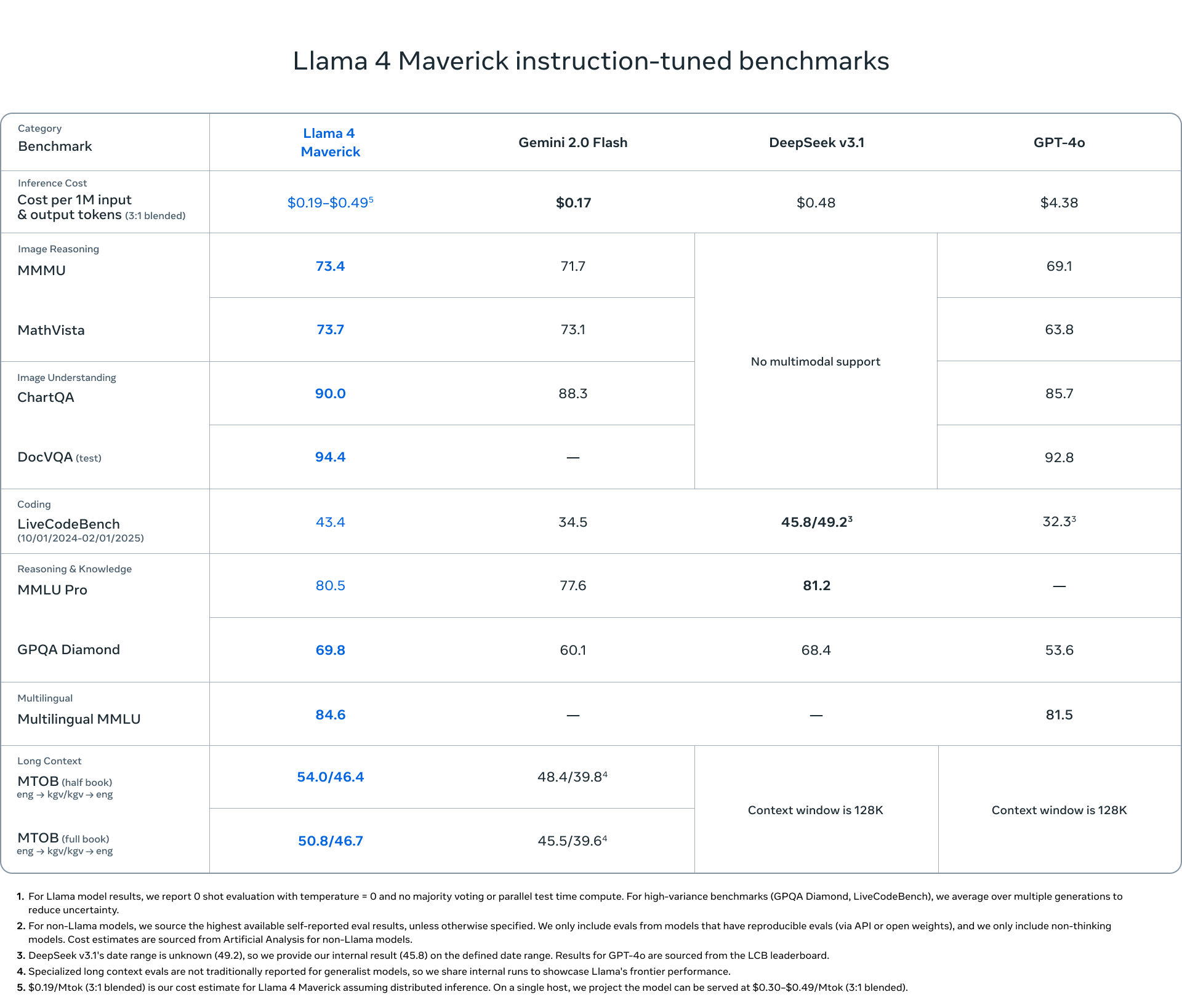
More information on Llama 4
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Llama 4 was manually vetted by our editorial team and was first featured on 2025-04-07.
Related Searches
Llama 4 替代方案
更多 替代方案-
使用 Meta Llama 3 探索 AI 的巔峰,它具備無與倫比的效能、可擴充性和訓練後提升功能。非常適合翻譯、聊天機器人和教育內容。使用 Llama 3 提升您的 AI 之旅。
-

LlamaIndex 運用您的企業資料,打造智慧型AI代理人,並透過先進的 RAG 技術賦能 LLMs,將複雜的文件轉化為可靠且可付諸實踐的洞察。
-
MonsterGPT:透過對話輕鬆微調並部署專屬AI模型。讓複雜的大型語言模型(LLM)與人工智慧(AI)任務變得更簡單。輕鬆存取超過 60 個開源模型。
-

-
