
What is Llama 4?
Bienvenue à Llama 4, la prochaine étape du parcours open source de Meta dans le domaine de l'IA. Cette nouvelle série introduit des modèles multimodaux puissants, conçus pour les développeurs, les chercheurs et les entreprises qui recherchent à la fois des performances élevées et une efficacité de calcul. Pour la première fois, les modèles Llama exploitent une architecture de type "Mixture of Experts" (MoE), ce qui les rend nettement plus rapides et plus économiques à exécuter et à entraîner. Conçu nativement pour comprendre et générer du contenu à partir de textes, d'images et de vidéos, Llama 4 propose des versions spécialisées telles que Scout et Maverick, offrant ainsi des solutions sur mesure pour divers besoins en matière d'applications d'IA.
Principales Caractéristiques
💬 Compréhension et génération de langage avancées : Interprète avec précision des textes complexes et génère un contenu cohérent et adapté au contexte. Entraîné sur de vastes ensembles de données textuelles (plus de 30 billions de tokens à travers différentes modalités), Llama 4 excelle dans des tâches allant de la rédaction créative et de la composition d'articles détaillés aux interactions de dialogue sophistiquées, comprenant l'intention de l'utilisateur et fournissant des réponses pertinentes.
🖼️ Traitement multimodal natif : Intègre et raisonne de manière transparente à partir d'entrées textuelles, d'images et de vidéos grâce à son architecture de fusion précoce. Llama 4 peut identifier des objets, des scènes et des couleurs dans des images, en fournissant des descriptions et des analyses. La version Scout repousse les limites avec une fenêtre contextuelle de 10 millions de tokens, capable de traiter d'énormes documents (des millions de mots) ou d'analyser plus de 20 heures de contenu vidéo en une seule fois. Son encodeur visuel, basé sur MetaCLIP, est spécialement réglé pour un meilleur alignement avec le modèle de langage central.
⚡ Architecture MoE efficace : Emploie une conception de type "Mixture of Experts" (MoE), une première pour la série Llama, permettant une inférence plus rapide et une réduction des coûts de calcul. Au lieu d'activer l'ensemble du modèle pour chaque tâche, MoE achemine les requêtes vers des sous-modèles "experts" spécialisés. Par exemple, Llama 4 Maverick possède 400 milliards de paramètres au total, mais n'en active que 17 milliards pour une entrée donnée, ce qui réduit considérablement la latence et les dépenses opérationnelles. Cette efficacité s'étend à la formation, où des techniques telles que la précision FP8 permettent d'atteindre un débit de calcul élevé (par exemple, 390 TFLOPs/GPU pour le pré-entraînement de Behemoth) sans sacrifier la qualité.
🌍 Vastes capacités multilingues : Pré-entraîné sur des données couvrant plus de 200 langues, Llama 4 offre une compréhension, une traduction et une génération de contenu interlinguales robustes. Cela vous permet de créer des applications qui s'adressent à un public mondial, en supprimant les barrières linguistiques pour les tâches de communication et de traitement de l'information. Il prend également en charge le réglage fin open source sur des ensembles de données linguistiques spécifiques.
Cas d'utilisation
Comment pouvez-vous tirer parti de Llama 4 ? Voici quelques exemples :
Création d'assistants de recherche avancés : Imaginez alimenter Llama 4 Scout avec des heures d'enregistrements de conférences, de longs articles de recherche contenant du texte et des diagrammes, ou de vastes bases de code. Sa fenêtre contextuelle de 10 millions de tokens lui permet de synthétiser des informations à partir de ces entrées volumineuses, en fournissant des résumés complets, en répondant à des questions complexes basées sur le matériel, ou même en identifiant des schémas dans le code qu'un humain pourrait manquer.
Développement de chatbots multimodaux attrayants : Utilisez Llama 4 Maverick pour alimenter un bot de service client ou un compagnon créatif. Les utilisateurs pourraient télécharger des images de produits et poser des questions détaillées, auxquelles Maverick peut répondre visuellement et contextuellement. Sa force dans l'écriture créative lui permet également de générer des récits attrayants, des textes marketing ou des histoires personnalisées basées sur des invites d'utilisateurs pouvant inclure à la fois du texte et des images.
Création d'outils internes rentables : Déployez Llama 4 Scout (exécutable sur un seul GPU H100) pour créer un moteur de recherche de base de connaissances interne pour votre entreprise. Son architecture MoE garantit un fonctionnement efficace, permettant aux employés de trouver rapidement des informations dans les documents, les rapports et potentiellement même les archives vidéo internes de l'entreprise, sans engendrer des coûts de calcul massifs.
Conclusion
Llama 4 marque une avancée significative vers une IA accessible et performante. En combinant l'efficacité de l'architecture "Mixture of Experts" avec la multimodalité native et une vaste prise en charge multilingue, Meta fournit une base puissante, flexible et open source pour votre prochain projet d'IA. Que vous ayez besoin de l'immense fenêtre contextuelle de Scout, des capacités équilibrées et de l'acuité de l'image de Maverick, ou que vous anticipiez la puissance spécialisée de Behemoth, Llama 4 offre des options intéressantes pour la création d'applications d'IA sophistiquées et efficaces.
Foire aux questions (FAQ)
Quelles sont les principales différences entre Llama 4 et les versions précédentes de Llama ? Llama 4 introduit plusieurs avancées clés : c'est la première série Llama à utiliser une architecture "Mixture of Experts" (MoE) pour une efficacité accrue ; il est nativement multimodal, conçu dès le départ pour gérer le texte, les images et la vidéo ; il offre des versions spécialisées (Scout, Maverick) adaptées à différents besoins ; Scout dispose d'une fenêtre contextuelle exceptionnellement grande de 10 millions de tokens ; et il est entraîné sur un ensemble de données significativement plus grand et plus diversifié (>30T tokens dans plus de 200 langues).
Qu'est-ce que "Mixture of Experts" (MoE) et pourquoi est-ce important dans Llama 4 ? MoE est une architecture où un grand modèle est composé de sous-modèles plus petits et spécialisés, appelés "experts". Lors du traitement d'une entrée, le modèle achemine les données uniquement vers les experts les plus pertinents, activant ainsi seulement une fraction du nombre total de paramètres. Cela rend l'inférence (l'exécution du modèle) beaucoup plus rapide et moins coûteuse en termes de calcul par rapport à l'activation d'un modèle dense de taille totale équivalente. Pour Llama 4, cela signifie une latence plus faible, des coûts de service réduits et une formation plus efficace.
Quel modèle Llama 4 dois-je choisir : Scout ou Maverick ?
Choisissez Llama 4 Scout si votre besoin principal est de traiter des contextes extrêmement longs (jusqu'à 10 millions de tokens, comme des documents très longs, des bases de code ou des heures de vidéo) ou si vous avez besoin d'un modèle très performant qui peut fonctionner efficacement, potentiellement même sur un seul GPU haut de gamme comme le H100.
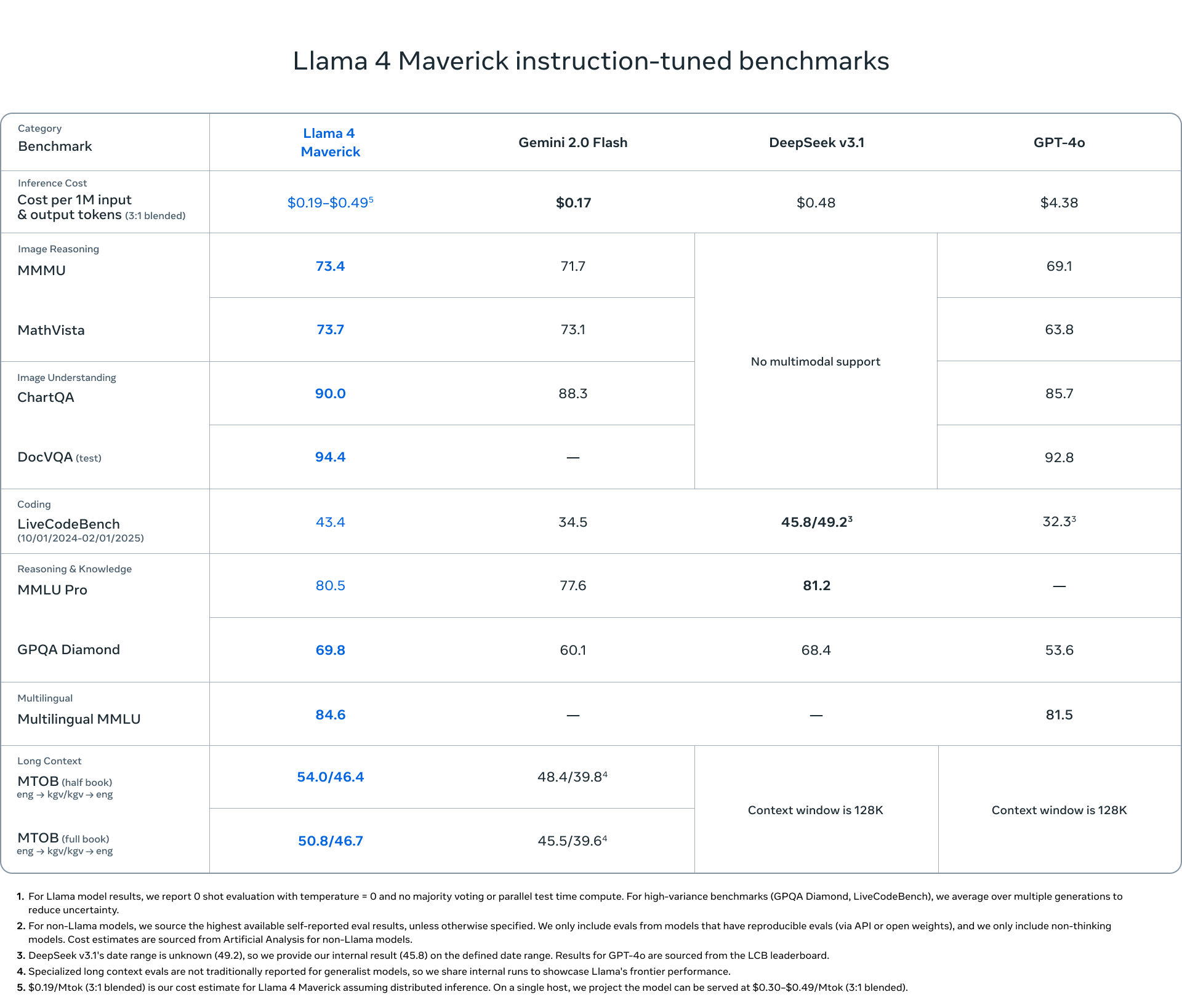
Choisissez Llama 4 Maverick pour des applications d'assistance ou de chatbot à usage général où de solides performances en matière d'écriture créative et une compréhension nuancée des images sont importantes. Il offre un équilibre des capacités et se classe bien dans les benchmarks d'IA généraux comme LMSYS.
Llama 4 Behemoth (actuellement en version préliminaire) est en cours d'entraînement avec 2 billions de paramètres et se montre exceptionnellement prometteur dans les benchmarks STEM, ciblant les tâches de raisonnement très complexes.
Quelle est l'efficacité technique de Llama 4 pendant l'entraînement et l'inférence ? Llama 4 exploite plusieurs techniques pour l'efficacité. L'architecture MoE réduit considérablement les paramètres actifs pendant l'inférence. Pour l'entraînement, Meta a utilisé la précision FP8, atteignant une utilisation élevée du matériel (par exemple, 390 TFLOPs par GPU pendant le pré-entraînement de Behemoth) tout en maintenant la qualité du modèle. Meta a également développé une nouvelle méthode appelée MetaP pour optimiser les hyperparamètres d'entraînement cruciaux, assurant la stabilité et la performance à différentes échelles.
Llama 4 est-il véritablement open source ? Oui, Meta publie les modèles Llama 4 sous une licence open source, permettant aux chercheurs, aux développeurs et aux entreprises d'accéder, de modifier et de s'appuyer librement sur les modèles, favorisant ainsi l'innovation au sein de la communauté de l'IA. Les modèles prennent également en charge le réglage fin open source.

More information on Llama 4
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Llama 4 was manually vetted by our editorial team and was first featured on 2025-04-07.
Related Searches
Llama 4 Alternatives
Plus Alternatives-
Découvrez le summum de l’IA avec Meta Llama 3, offrant des performances, une évolutivité et des améliorations post-formation inégalées. Idéal pour la traduction, les chatbots et le contenu éducatif. Améliorez votre parcours IA avec Llama 3.
-

LlamaIndex conçoit des agents IA intelligents à partir de vos données d'entreprise. Propulsez les LLMs grâce à un RAG avancé, transformant ainsi les documents complexes en informations fiables et exploitables.
-
MonsterGPT: Peaufinez et déployez des modèles d'IA sur mesure via le chat. Simplifiez les tâches complexes de LLM et d'IA. Accédez facilement à plus de 60 modèles open-source.
-

-
