
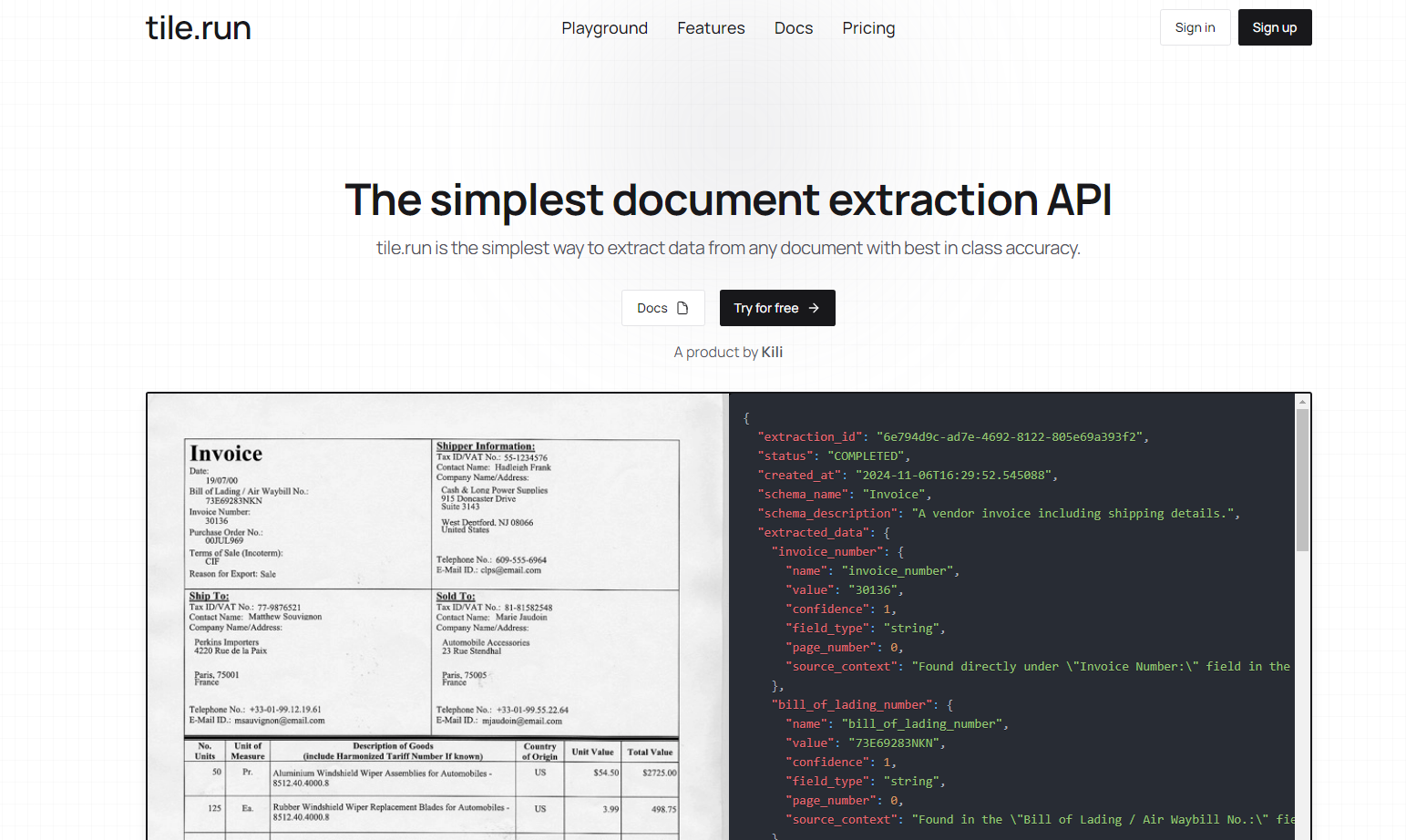
What is Tile.run?
tile.run ofrece una API de extracción de documentos sencilla, rápida y precisa, diseñada para desarrolladores. Admite diversos formatos de archivo, gestiona documentos de varias páginas y destaca en la extracción de datos de tablas densas. Con una precisión de primera clase y funciones de auditoría como puntuaciones de confianza, tile.run garantiza una extracción de datos estructurados fiable. Tanto si necesita procesar archivos PDF, imágenes o archivos de texto, tile.run agiliza el proceso de extracción, facilitando su integración y escalabilidad según sus necesidades.
Características principales:
? Configuración sencilla
Ponga la API en funcionamiento en menos de 2 minutos con una integración sencilla.? Gestión versátil de archivos
Admite una amplia gama de formatos de archivo, incluidos archivos PDF, TIFF, JPEG, JPG y TXT.? Compatibilidad con varias páginas
Gestiona eficazmente documentos de varias páginas, garantizando que no se pierdan datos.? Extracción de datos de tablas
Especialmente diseñada para extraer datos de tablas complejas con alta precisión.? Alta precisión
Ofrece una precisión de primera clase para la extracción de datos estructurados, respaldada por funciones de auditoría.
Casos de uso:
Un analista financiero extrae datos de informes PDF de varias páginas para rellenar una base de datos para el análisis de tendencias.
Un administrador sanitario extrae datos tabulares de formularios médicos escaneados para agilizar la gestión de los registros de pacientes.
Un asistente legal extrae texto y datos de varios formatos de documentos para recopilar pruebas de casos de manera eficiente.
Conclusión:
tile.run destaca como una solución robusta para los desarrolladores que necesitan una extracción de datos de documentos precisa y eficiente. Su facilidad de configuración, su versátil gestión de archivos y su precisión superior la convierten en una opción ideal para las empresas que trabajan con documentos complejos. Tanto si trabaja con tablas, archivos de varias páginas o varios formatos, tile.run simplifica el proceso de extracción, permitiéndole concentrarse en el aprovechamiento de los datos.
Preguntas frecuentes:
¿Qué formatos de archivo admite tile.run?
tile.run admite archivos PDF, TIFF, JPEG, JPG y TXT.¿Cómo garantiza tile.run la precisión de la extracción de datos?
tile.run proporciona puntuaciones de confianza y funciones de auditoría para garantizar una alta precisión y fiabilidad.¿Puede tile.run gestionar documentos de varias páginas?
Sí, tile.run gestiona eficazmente documentos de varias páginas, garantizando que se extraigan todos los datos sin pérdidas.
More information on Tile.run
Launched
2024-11
Pricing Model
Freemium
Starting Price
$49/month
Global Rank
Follow
Month Visit
<5k
Tech used
Plausible Analytics,Google Fonts,Next.js,Vercel,Gzip,Webpack,HSTS
Tile.run was manually vetted by our editorial team and was first featured on 2024-11-20.
Related Searches
Tile.run Alternativas
Más Alternativas-
-

¡Extracción de tablas simplificada! Tablextract, impulsado por IA, extrae datos de PDF, JPG, PNG a Excel, CSV. ¡Ahorra tiempo y reduce errores!
-

DeepTagger: La IA sin código automatiza la extracción inteligente de datos de documentos. Transforma documentos complejos en datos estructurados y accionables, y desvela información valiosa.
-

Trellis es una potente herramienta de IA para automatizar flujos de trabajo de PDF. Con OCR avanzado, acciones personalizables y seguridad de nivel empresarial, aumenta la productividad y la precisión de los datos. Ideal para finanzas, salud y bienes raíces.
-

Parse Extract: Extracción de datos avanzada y OCR para pipelines de LLM. Transforma documentos complejos y datos web en texto limpio, listo para LLM. Rentable y seguro.