
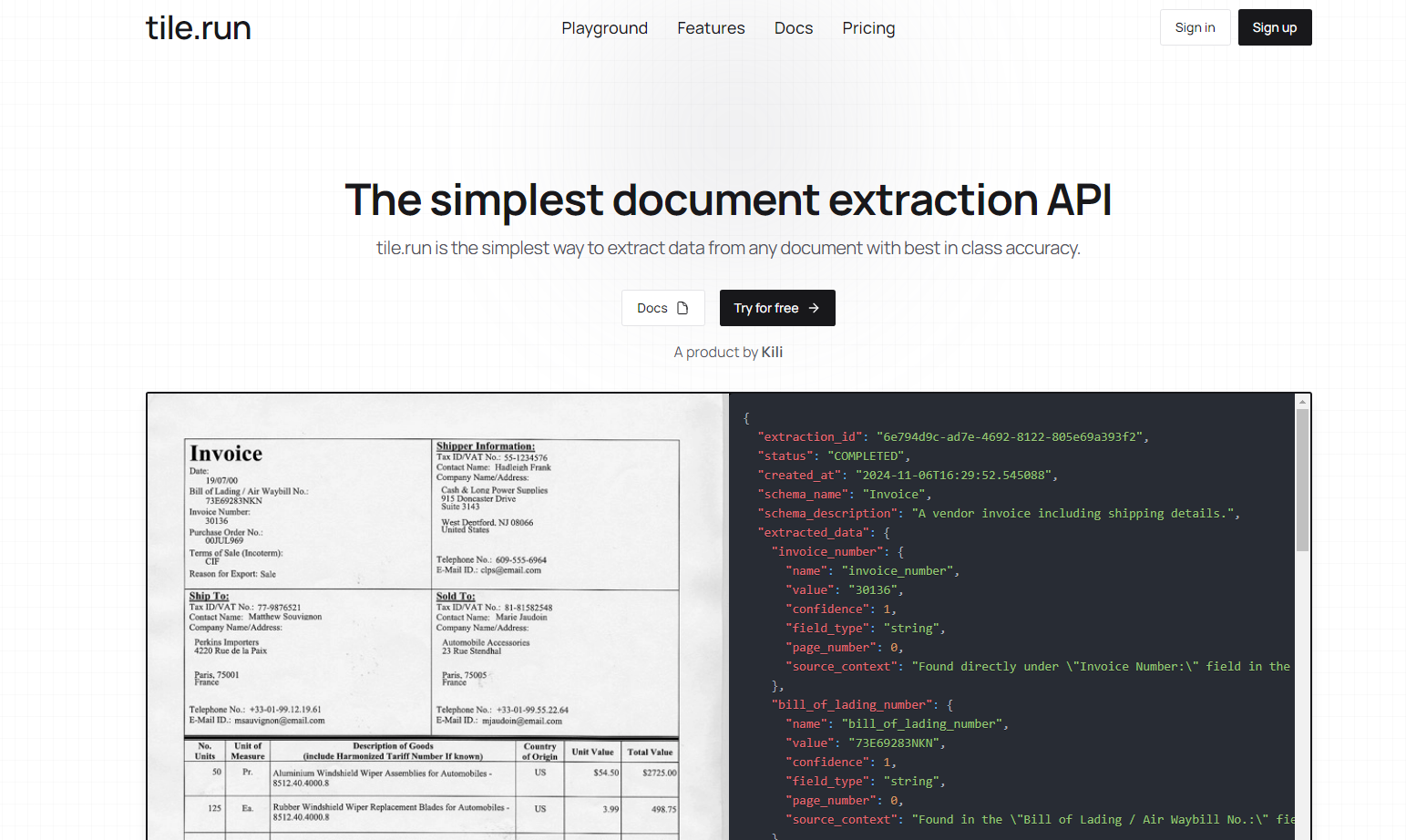
What is Tile.run?
tile.runは、開発者を対象としたシンプルで高速かつ正確なドキュメント抽出APIです。様々なファイル形式に対応し、複数ページのドキュメントを処理し、複雑な表からのデータ抽出にも優れています。業界最高水準の精度と、信頼性スコアなどの監査機能により、tile.runは信頼性の高い構造化データ抽出を保証します。PDF、画像、テキストファイルなど、どのようなファイルであっても、tile.runは抽出プロセスを効率化し、ニーズに合わせて容易に統合および拡張できます。
主な機能:
? 簡単な設定
分かりやすい統合により、2分以内でAPIを稼働させることができます。? 多様なファイル処理
PDF、TIFF、JPEG、JPG、TXTファイルなど、幅広いファイル形式に対応しています。? 複数ページ対応
複数ページのドキュメントを効率的に処理し、データの欠落を防ぎます。? 表データ抽出
複雑な表からのデータを高精度で抽出するように特別に設計されています。? 高精度
監査機能によって裏付けられた、構造化データ抽出のための業界最高水準の精度を実現します。
ユースケース:
金融アナリストが複数ページのPDFレポートからデータを抽出し、トレンド分析のためのデータベースにデータを入力します。
医療管理者がスキャンされた医療用紙から表形式のデータを抽出し、患者記録管理を効率化します。
法務助手は様々なドキュメント形式からテキストとデータを抽出し、効率的に証拠を収集します。
結論:
tile.runは、正確で効率的なドキュメントデータ抽出を必要とする開発者にとって、堅牢なソリューションとして際立っています。簡単な設定、多様なファイル処理、優れた精度により、複雑なドキュメントを扱う企業にとって理想的な選択肢となります。表、複数ページのファイル、様々な形式のいずれを使用している場合でも、tile.runは抽出プロセスを簡素化し、データの活用に集中できます。
よくある質問:
tile.runはどのようなファイル形式に対応していますか?
tile.runはPDF、TIFF、JPEG、JPG、TXTファイルに対応しています。tile.runはどのようにデータ抽出の精度を保証していますか?
tile.runは、信頼性スコアと監査機能を提供することで、高い精度と信頼性を保証します。tile.runは複数ページのドキュメントを処理できますか?
はい、tile.runは複数ページのドキュメントを効率的に処理し、すべてのデータが損失なく抽出されます。
More information on Tile.run
Launched
2024-11
Pricing Model
Freemium
Starting Price
$49/month
Global Rank
Follow
Month Visit
<5k
Tech used
Plausible Analytics,Google Fonts,Next.js,Vercel,Gzip,Webpack,HSTS
Tile.run was manually vetted by our editorial team and was first featured on 2024-11-20.
Related Searches
Tile.run 代替ソフト
もっと見る 代替ソフト-
-

表抽出を簡単に!AI搭載のTablextractは、PDF、JPG、PNGからExcel、CSVへのデータ抽出を可能にします。時間と労力を節約し、エラーを削減します!
-

DeepTagger: ノーコードAIが、インテリジェントな文書データ抽出を自動化します。複雑な文書を構造化された実用的なデータへと変換し、新たな知見を解き放ちます。
-

Trellisは、PDFワークフローを自動化する強力なAIツールです。高度なOCR、カスタマイズ可能なアクション、エンタープライズレベルのセキュリティにより、生産性とデータ精度を向上させます。金融、医療、不動産業界に最適です。
-

Parse Extract: LLMパイプライン向けの高度なデータ抽出とOCR。 複雑なドキュメントやウェブデータを、クリーンでLLMに最適なテキストへと変換します。 費用対効果に優れ、高いセキュリティを実現します。