
What is Tile.run?
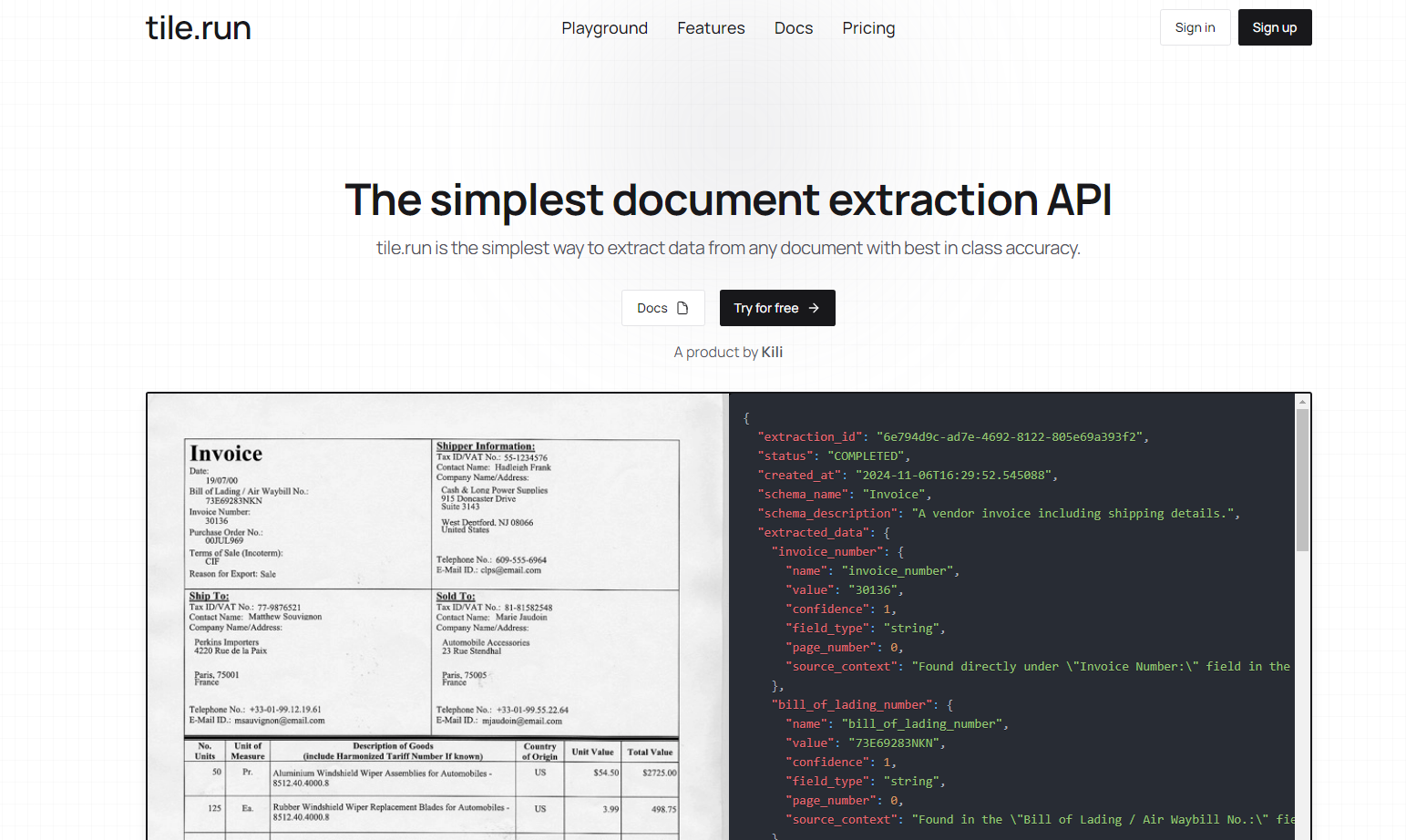
tile.run propose une API d’extraction de documents simple, rapide et précise, conçue pour les développeurs. Elle prend en charge divers formats de fichiers, gère les documents multipages et excelle dans l’extraction de données à partir de tableaux complexes. Avec une précision optimale et des fonctionnalités d’auditabilité telles que les scores de confiance, tile.run assure une extraction de données structurées fiable. Que vous ayez besoin de traiter des PDF, des images ou des fichiers texte, tile.run rationalise le processus d’extraction, facilitant son intégration et son adaptation à vos besoins.
Fonctionnalités clés :
? Configuration simplifiée
Mettez l’API en service en moins de 2 minutes grâce à une intégration intuitive.? Gestion polyvalente des fichiers
Prend en charge une large gamme de formats de fichiers, notamment les PDF, TIFF, JPEG, JPG et TXT.? Prise en charge multipages
Gère efficacement les documents multipages, garantissant qu’aucune donnée ne soit omise.? Extraction de données tabulaires
Spécialement conçue pour extraire les données de tableaux complexes avec une grande précision.? Haute précision
Offre une précision optimale pour l’extraction de données structurées, soutenue par des fonctionnalités d’auditabilité.
Cas d’utilisation :
Un analyste financier extrait des données de rapports PDF multipages pour alimenter une base de données destinée à l’analyse des tendances.
Un administrateur de la santé extrait des données tabulaires de formulaires médicaux numérisés pour rationaliser la gestion des dossiers patients.
Un assistant juridique extrait du texte et des données de divers formats de documents pour compiler efficacement les preuves d’un dossier.
Conclusion :
tile.run se distingue comme une solution robuste pour les développeurs ayant besoin d’une extraction de données de documents précise et efficace. Sa facilité de configuration, sa gestion polyvalente des fichiers et sa précision supérieure en font un choix idéal pour les entreprises travaillant avec des documents complexes. Que vous travailliez avec des tableaux, des fichiers multipages ou divers formats, tile.run simplifie le processus d’extraction, vous permettant de vous concentrer sur l’exploitation des données.
FAQ :
Quels formats de fichiers tile.run prend-il en charge ?
tile.run prend en charge les fichiers PDF, TIFF, JPEG, JPG et TXT.Comment tile.run garantit-il la précision de l’extraction des données ?
tile.run fournit des scores de confiance et des fonctionnalités d’auditabilité pour garantir une grande précision et une fiabilité optimale.tile.run peut-il gérer des documents multipages ?
Oui, tile.run gère efficacement les documents multipages, garantissant l’extraction de toutes les données sans perte.
More information on Tile.run
Launched
2024-11
Pricing Model
Freemium
Starting Price
$49/month
Global Rank
Follow
Month Visit
<5k
Tech used
Plausible Analytics,Google Fonts,Next.js,Vercel,Gzip,Webpack,HSTS
Tile.run was manually vetted by our editorial team and was first featured on 2024-11-20.
Related Searches
Tile.run Alternatives
Plus Alternatives-
-

Extraction de tableaux simplifiée ! Tablextract, alimenté par l'IA, extrait les données de PDF, JPG et PNG vers Excel et CSV. Gagnez du temps et réduisez les erreurs !
-

DeepTagger : L'IA sans code automatise l'extraction intelligente de données documentaires. Convertissez les documents complexes en données structurées et exploitables, et débloquez des perspectives inédites.
-

Trellis est un puissant outil d'IA pour automatiser les flux de travail PDF. Grâce à une reconnaissance optique de caractères (OCR) avancée, des actions personnalisables et une sécurité de niveau entreprise, il améliore la productivité et la précision des données. Idéal pour les secteurs de la finance, de la santé et de l'immobilier.
-

Parse Extract : Extraction de données avancée et OCR pour les pipelines de LLM. Transformez des documents complexes et des données web en un texte épuré et optimisé pour les LLM. Rentable et sécurisé.