What is Helicone AI Gateway?
Helicone AI Gateway est une couche de routage open-source et haute performance, conçue pour les développeurs qui bâtissent des applications à l'aide de Grands Modèles de Langage (LLMs). Il agit comme un point d'accès unique et unifié pour tous vos fournisseurs d'IA, simplifiant l'intégration, optimisant les performances et vous donnant un contrôle précis sur les coûts et la fiabilité. Considérez-le comme le NGINX des LLMs – un outil rapide, léger et essentiel pour les applications d'IA de qualité production.
Caractéristiques Principales
🌐 API Unifiée pour plus de 100 Modèles Utilisez la syntaxe familière de l'OpenAI SDK pour interagir avec plus de 20 fournisseurs, y compris Anthropic, Google, AWS Bedrock, et bien d'autres. Vous pouvez basculer entre des modèles comme
gpt-4o-minietclaude-3-5-sonnetavec une simple modification d'une ligne, éliminant le besoin d'apprendre et de maintenir des intégrations séparées pour chaque fournisseur.⚡ Routage Intelligent & Équilibrage de Charge Acheminez automatiquement les requêtes vers le modèle ou le fournisseur optimal en fonction de votre stratégie définie. Que vous ayez besoin du temps de réponse le plus rapide, du coût le plus bas ou de la fiabilité la plus élevée, les stratégies intégrées de la passerelle (telles que le routage basé sur la latence et l'optimisation des coûts) prennent des décisions intelligentes en temps réel.
💰 Contrôle Granulaire des Coûts et de l'Utilisation Prévenez les coûts incontrôlés et l'abus d'utilisation grâce à un contrôle de débit puissant et facile à configurer. Vous pouvez définir des limites précises basées sur le nombre de requêtes, l'utilisation des tokens ou des montants en dollars – à l'échelle globale, par utilisateur ou par équipe – pour garantir que votre application reste dans les limites de votre budget.
🚀 Mise en Cache Haute Performance Réduisez considérablement la latence et les coûts d'API en mettant en cache les réponses pour les requêtes répétées. Avec le support des backends Redis et S3, Helicone AI Gateway peut servir des résultats mis en cache en quelques millisecondes, améliorant l'expérience utilisateur et réduisant les dépenses jusqu'à 95% pour les requêtes courantes.
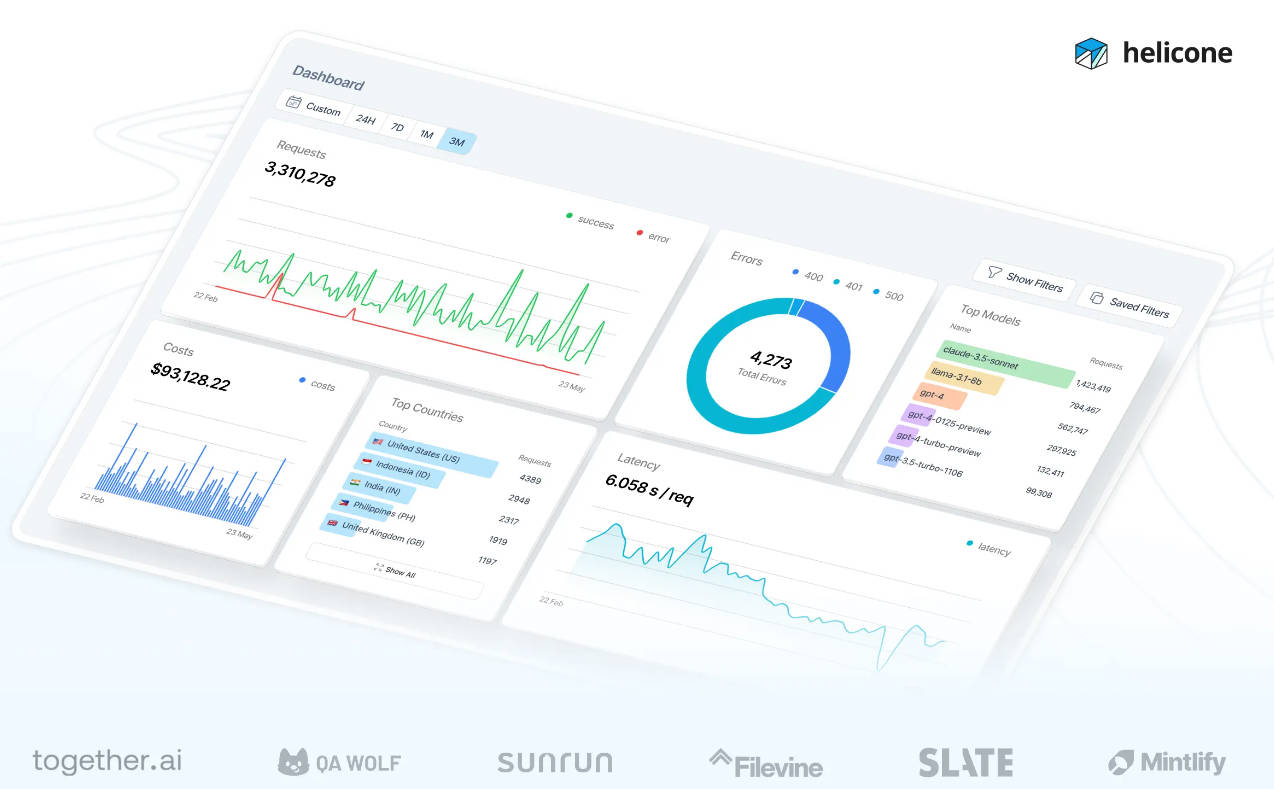
📊 Observabilité Transparente Obtenez des informations approfondies sur l'utilisation et les performances de vos LLMs grâce à une intégration prête à l'emploi avec la plateforme d'observabilité Helicone. La passerelle supporte également OpenTelemetry, vous permettant d'exporter les logs, les métriques et les traces vers vos outils de monitoring existants pour un débogage unifié.
Cas d'Utilisation
Construire des Fonctionnalités d'IA Tolérantes aux Pannes : Si votre fournisseur de LLM principal (par exemple, OpenAI) subit une panne, vous pouvez configurer la passerelle pour basculer automatiquement vers un fournisseur secondaire (par exemple, Anthropic ou Google). Cela garantit que votre application reste disponible et que vos utilisateurs ne subissent aucune interruption.
Optimiser un Chatbot Sensible aux Coûts : Pour un bot de support interne, vous pouvez créer une règle de routage qui envoie les requêtes simples et informatives à un modèle rapide et peu coûteux. Pour les requêtes complexes et analytiques, la passerelle peut automatiquement acheminer vers un modèle plus puissant et capable, vous assurant de ne payer pour des performances élevées que lorsque vous en avez réellement besoin.
Mettre à l'Échelle une Application Grand Public : Lors du lancement d'une nouvelle fonctionnalité basée sur l'IA, utilisez la mise en cache pour gérer instantanément des volumes élevés de requêtes courantes et appliquez des limites de débit aux utilisateurs individuels. Cela protège votre application contre les abus, assure une utilisation équitable et maintient vos coûts opérationnels prévisibles à mesure que vous montez en charge.
Conclusion
Helicone AI Gateway fournit l'infrastructure critique nécessaire pour construire, mettre à l'échelle et optimiser les applications LLM en toute confiance. En faisant abstraction de la complexité de la gestion de multiples fournisseurs d'IA, il vous permet de vous concentrer sur la création de valeur pour vos utilisateurs tout en garantissant que votre application est rapide, fiable et rentable.
Explorez le dépôt open-source ou démarrez en quelques secondes avec la version hébergée dans le cloud pour prendre le contrôle de vos intégrations d'IA dès aujourd'hui.
More information on Helicone AI Gateway
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Helicone AI Gateway was manually vetted by our editorial team and was first featured on 2025-08-18.
Related Searches
Helicone AI Gateway Alternatives
Plus Alternatives-
LLM Gateway : Unifiez et optimisez les API de LLM multi-fournisseurs. Acheminez intelligemment les requêtes, suivez les coûts et boostez les performances pour OpenAI, Anthropic et bien d'autres. Open-source.
-

Envoy AI Gateway est un projet open source destiné à utiliser Envoy Gateway pour prendre en charge le trafic de requêtes provenant des applications clientes vers les services d'IA générative.
-

-
Découvrez la puissance de Portkey's AI Gateway - un outil révolutionnaire pour une intégration transparente des modèles d'IA dans votre application. Améliorez les performances, l'équilibrage de la charge et la fiabilité pour des applications exploitant l'IA résilientes et efficaces.
-