
2025年に最高の AnyCrawl 代替ソフト
-

Crawl4AI: あなたのAIプロジェクトやRAGアプリケーション向けに、あらゆるウェブサイトをクリーンでLLM対応のデータへと変換するために特別に開発されたオープンソースのウェブクローラー。
-

AI開発者とデータサイエンティストのための究極のツール。動的なコンテンツ処理とMarkdown変換による効率的なウェブデータ抽出を実現します。
-

WaterCrawl:あらゆるウェブサイトを、AIが即座に活用できるクリーンなデータへと変革。AIデータ抽出と動的ウェブクローリングのための、開発者ファーストのフレームワーク。
-

Webcrawlerapiを使えば、ウェブデータ抽出が簡単になります! JavaScriptの処理、プロキシ、スケーリングに対応。AIや分析などに必要な構造化データを取得できます。
-

ウェブスクレイピングのブロックとの格闘はもうやめましょう。 WebScraping.AI APIは、JavaScript、プロキシ、CAPTCHAの処理に加え、AIを活用してスマートなデータ抽出と分析を可能にします。
-
x-crawlは、柔軟なNode.js AIアシストクローラーライブラリです。柔軟な使い方と強力なAIアシスト機能によって、クローラーの作業がより効率的、インテリジェント、便利になります。
-

開発者向けの費用対効果の高いウェブクロールAPI。数百万ページへのスケーリング、JSONデータの抽出、サイトルールの遵守を実現します。5分で開始できます!
-

Crawly:AIを活用したウェブデータ抽出API。ターゲットを絞ったデータ、フルスキャン、スクリーンショットを取得。シンプルな統合。無料トライアル実施中!
-

UseScraper は効率的なデータ抽出のための強力な Web クローラーとスクレイパー API です。データを抽出し、JavaScript をレンダリングし、出力フォーマットを簡単に選択できます。
-

Crawl4LLM:LLMデータのためのインテリジェントなウェブクローラー。高品質なオープンソースデータを5倍速で取得し、効率的なAI事前学習を実現します。
-

-

AIを活用し、あらゆるサイトから構造化されたウェブデータを楽々抽出。コードは一切不要です!プロンプトとスキーマで、必要な情報を正確に定義するだけ。
-

-

Scrapeless:AI搭載のウェブスクレイピングツールキット。手間のかからないデータ抽出を実現します。ブロックを回避し、CAPTCHAを解決し、簡単にスケーリングできます。
-
AnyPicker: AI搭載ノーコードウェブスクレイパー。クリック一つで、あらゆるウェブサイトから構造化データを簡単にスプレッドシートへ抽出。安全・プライベート。
-
CrawlQ AI Agents — マーケティング、オペレーション、そして成長のための自律型AIツールで、よりスマートにスケールアップしましょう。実行可能なインサイトと自動化によって、未来を見据えたビジネスを実現します。
-
-

Crawlee — Python 用のウェブスクレイピングおよびブラウザ自動化ライブラリで、信頼性の高いクローラーを構築できます。AI、LLM、RAG、GPT 用にデータを抽出します。
-

ScrapeGraphAIは、ウェブサイトやローカルドキュメントから構造化データを抽出するAI搭載スクレイピングAPIです。
-

より賢いGPTをより速く構築しましょう! GPT Crawlerはウェブサイトのコンテンツを抽出し、カスタムAIモデル用の構造化された知識ファイルを作成します。
-
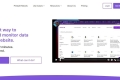
Browse AIで、ウェブデータの抽出と監視を簡単に行えます。当社のノーコードAIプラットフォームは、ウェブサイトの変更にも柔軟に適応し、信頼性の高い自動データ抽出を実現します。
-

ウェブスクレイピングのブロックとの格闘は、もう終わりにしましょう。 ScrapingAnt APIは、プロキシ、CAPTCHA、JavaScriptの処理に対応し、信頼性の高いデータ抽出を提供します。 迅速にクリーンなデータを取得できます。
-

Parseraは、LLM搭載のWebデータ抽出プラットフォームとして、自然言語による指示のみで、あらゆるURLから視認可能な全データをスクレイピングできます。そして、抽出したデータはワンクリックで再利用可能なスクレイピングスクリプトへと変換でき、数千もの同構造ページに適用することが可能です。
-

ウェブデータの収集でお困りではありませんか? MrScraperはAIを活用し、ノーコードで手軽にウェブスクレイピングを実現します。 強力なプロキシでアンチボットのブロックを回避しながら、あらゆるサイトからクリーンなデータを抽出可能です。
-
AIを活用して、ウェブデータ抽出を簡単に。コードは不要です。Lightfeedはウェブサイトの変更に合わせて自動的に適応し、クリーンでリアルタイムなデータを提供します。
-
ScrapeGraphAIは、LLMとダイレクトグラフロジックを使用して、ウェブサイト、文書、およびXMLファイルのスクレイピングパイプラインを作成するWebスクレイピングPythonライブラリです。抽出する情報を指定するだけで、ライブラリがそれを行います!
-

どんなウェブサイトも、構造化されたAPIや整然としたデータソースへと変換します。 AIとノーコードツールを活用し、ウェブデータを手軽に抽出。 パワフルかつシンプルなスクレイピング。
-

Extractor API: AIを駆使し、あらゆるウェブページ、PDF、ニュースから、クリーンで構造化されたデータを抽出。複雑なウェブスクレイピングを自動化し、LLMsを活用して深い洞察へと導きます。
-

DevDocs: 技術ドキュメントを自動化!クロール、クリーンアップ、そしてMarkdown/JSON形式でのエクスポート。LLMとの連携も可能です。フリーでオープンソース。
-

AI向けウェブデータ取得をより簡単に。pure.md API:ボット検知を回避し、クリーンなmarkdownをスクレイピング。信頼性の高いウェブコンテンツであなたのAIを強化しましょう!