
Click outside to close
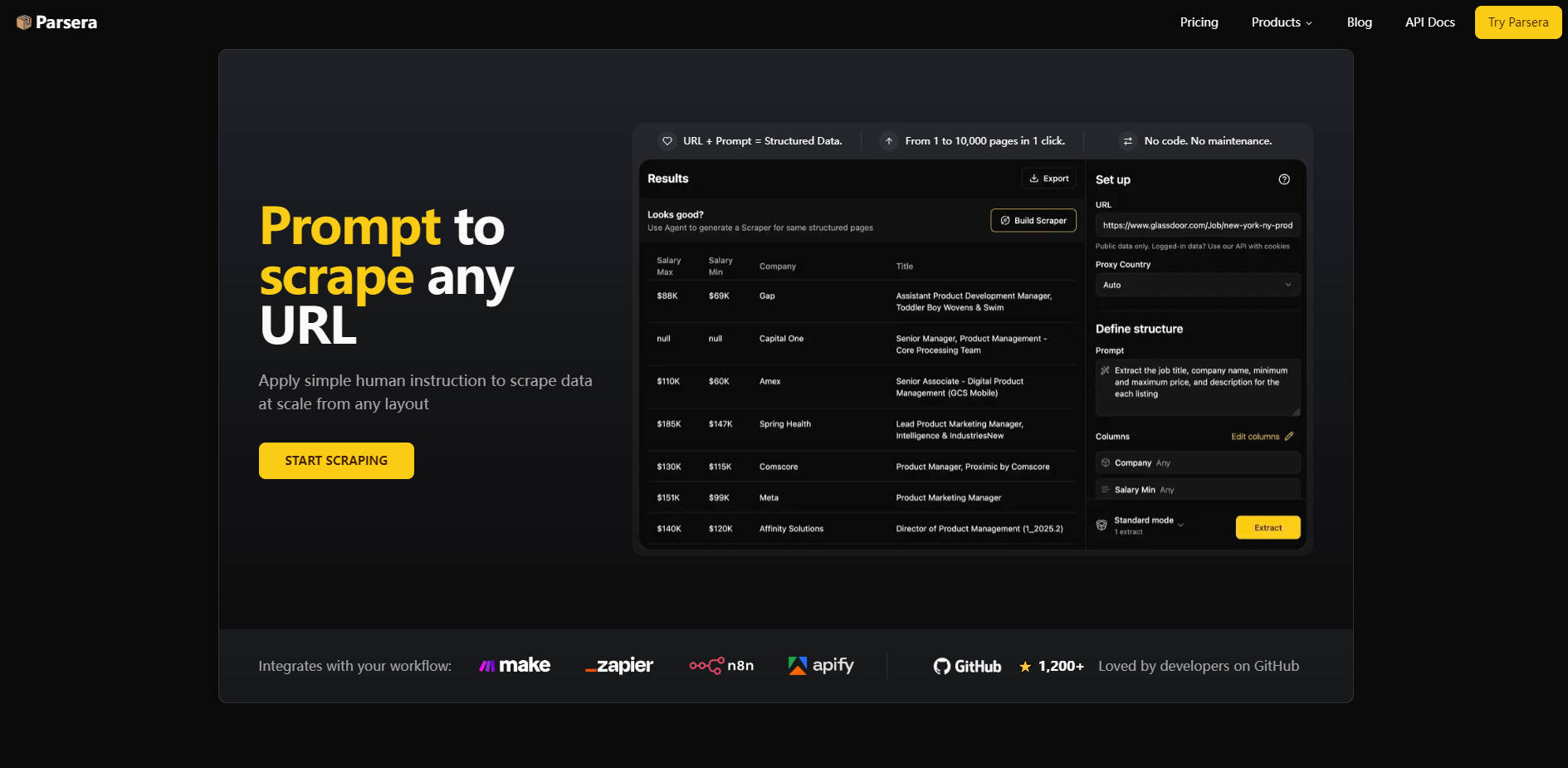
What is Parsera ?
Parsera is an LLM-powered Web Data Extraction Platform designed specifically for developers who require reliable, clean data at massive scale. It eliminates the complexity and maintenance overhead of traditional scraping by transforming any website link into structured, ready-to-use data using precise, self-repairing AI agents. With Parsera, you gain immediate, accurate results with zero manual coding or downtime, allowing you to focus on utilizing the data rather than building and maintaining the infrastructure.
Key Features
Parsera is engineered to handle the modern web's complexity while delivering clean, structured outputs with minimal effort.
🤖 Self-Repairing AI Extraction
Leverage precise, self-repairing AI agents to deliver consistently clean data, regardless of minor website layout changes. Unlike brittle manual selectors (XPath/CSS) that frequently break, Parsera’s LLM-based Extractor adapts dynamically to the page structure, ensuring high reliability and reducing the need for constant maintenance.
🚀 Scale with Generated Scrapers
Transform any successful AI extraction (a URL + natural language Prompt) into a reusable, high-efficiency Scraper with a single click. Crucially, these Generated Scrapers use the LLM only once during the initial code creation, drastically reducing processing costs and enabling reliable, affordable scraping of thousands of same-structured pages.
⚙️ Streamlined 3-Step Automation
Initiate and deploy complex data extraction using a simple, human-like workflow. Describe the required data fields using natural language instructions, Refine specific context for accuracy, and Automate the process by generating a reusable Scraper. This process drastically shortens the time from concept to production-ready data.
🔗 Seamless Workflow Integration
Integrate Parsera directly into your existing data pipelines using robust API support. We offer native connectors with popular workflow orchestration tools, including Zapier, Make, n8n, and Apify, ensuring extracted data flows instantly where you need it for analysis or action.
🍪 Authenticated Data Access
Access data behind login walls or paywalls. Parsera’s API supports the usage of cookies, enabling you to extract critical information that requires user authentication to be visible.
Use Cases
Parsera helps developers and data teams quickly acquire reliable data for critical business functions, moving beyond manual processes and fragile scripts.
Competitive E-commerce Intelligence
Automatically track competitor product listings, including real-time pricing, availability, and detailed specifications across thousands of unique product pages. You can rapidly deploy pre-generated scrapers (like the Amazon Product Scraper) to maintain market intelligence that is always current and accurate.
Targeted Lead Generation and Market Research
Rapidly build highly targeted lead lists and conduct in-depth competitor analysis by gathering contact information and company details from various web sources. Utilize the LLM Extractor's adaptability to scrape data from URLs with different structures, ensuring comprehensive coverage for prospecting and market sizing.
Real Estate and Financial Market Analysis
Monitor and analyze vast amounts of structured data from real estate listings or specialized financial news sites. By extracting only the relevant metrics—such as historical pricing, location data, or policy changes—you gain the insights necessary to inform investment decisions and market forecasting.
Unique Advantages
Parsera stands out by offering a fundamentally different, developer-friendly approach to web data extraction, prioritizing efficiency, reliability, and cost-effectiveness at scale.
Reliability Through Self-Repairing AI
Traditional web scrapers require constant coding effort and maintenance as websites change. Parsera’s core advantage lies in its LLM-powered Extractor, which understands context and layout dynamically. This self-repairing capability means you experience no downtime and zero maintenance associated with selector breakage, ensuring your data pipelines remain robust.
Optimized Cost for Scale
Parsera intelligently manages compute resources by separating the high-adaptability stage (Extractor) from the high-scale stage (Generated Scrapers).
Extractor (Higher Cost): Uses the LLM for every request, ideal for testing, adapting to new structures, or handling unique, varied URLs.
Generated Scrapers (Lower Cost): Uses the LLM only once for code generation. Once built, these scrapers execute reliably at a fraction of the cost (1 credit per scrape), making massive, repetitive extraction highly economical.
Commitment to Ethical Scraping
We believe in responsible data extraction. Parsera adheres strictly to ethical website scraping practices by automatically respecting the robots.txt files of target websites, helping you maintain compliance and good digital citizenship.
Conclusion
Parsera provides developers with a powerful, scalable, and resilient alternative to brittle manual scraping solutions. By leveraging advanced AI agents, you can focus your engineering resources on utilizing clean data rather than maintaining extraction code. Explore our platform today and start transforming complex web layouts into structured data effortlessly.
More information on Parsera
Top 5 Countries
25.25%
18.37%
11.27%
7.65%
6.98%
Brazil (25.25%)
India (18.37%)
Thailand (11.27%)
France (7.65%)
Turkey (6.98%)
Traffic Sources
49.98%
34.05%
4.74%
9.58%
mail (0.13%)
direct (49.98%)
search (34.05%)
social (4.74%)
referrals (9.58%)
paidReferrals (1.35%)
Source: Similarweb (Jan 4, 2026)
Parsera was manually vetted by our editorial team and was first featured on 2025-10-31.
Parsera Alternatives
Parsera Alternatives-

Scrapeless: The AI-powered web scraping toolkit for hassle-free data extraction. Bypass blocks, solve CAPTCHAs, and scale effortlessly.
-

Need web data? MrScraper uses AI for easy, no-code web scraping. Extract clean data from any site, bypassing anti-bot blocks with powerful proxies.
-

Automate text extraction from documents with Parseur, the powerful AI parser. Save time and eliminate errors with this user-friendly tool. Get started for free!
-

Stop fighting web scraping blockers. WebScraping.AI API handles JS, proxies, CAPTCHAs + uses AI for smart data extraction & analysis.
-

Parse Extract: Advanced data extraction & OCR for LLM pipelines. Transform complex documents & web data into clean, LLM-ready text. Cost-efficient & secure.