
Click outside to close
What is Crawlspace?
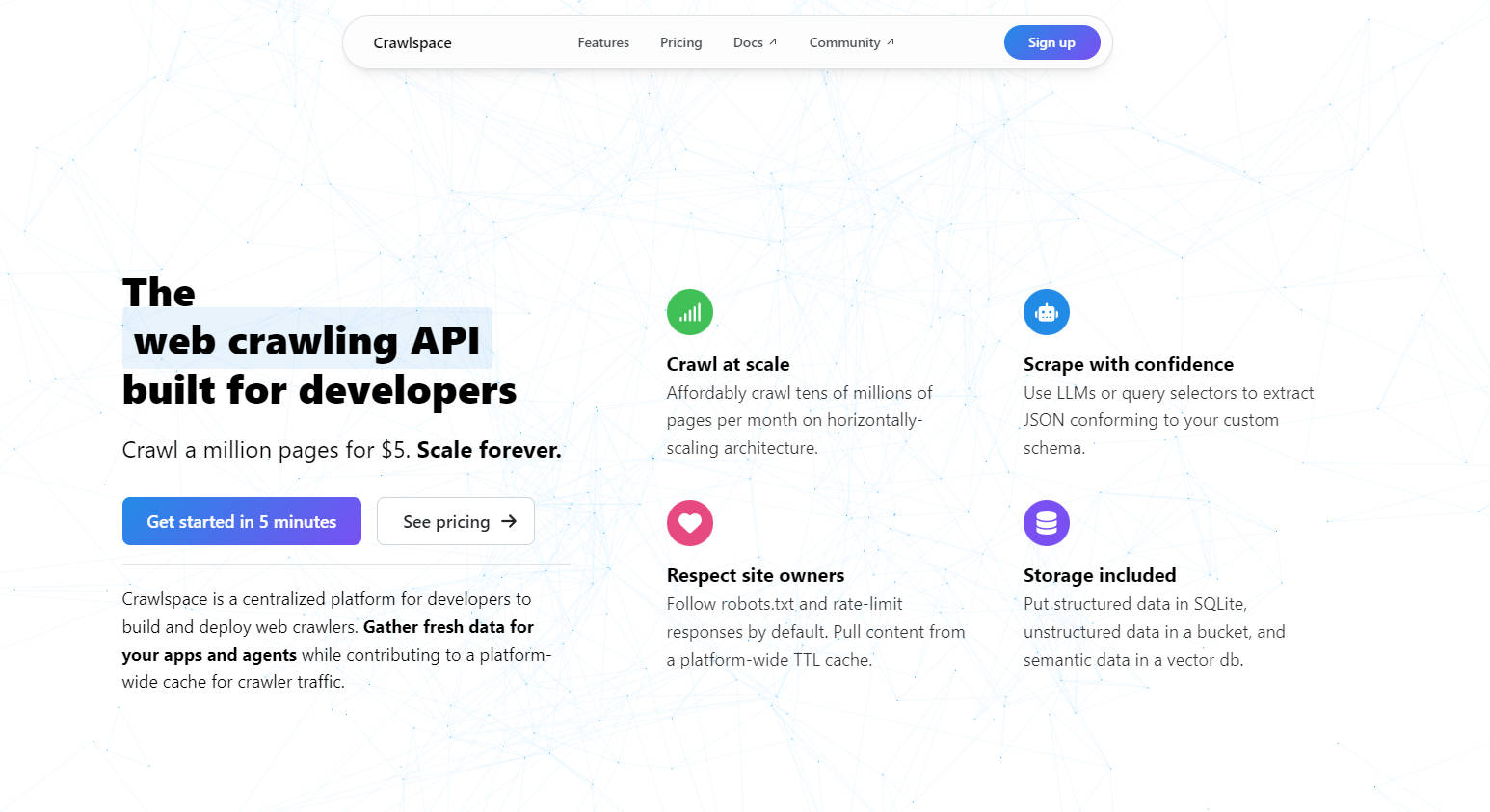
Crawlspace is a developer-first platform designed to simplify web crawling and data extraction. Whether you're building apps, training AI models, or gathering insights, Crawlspace empowers you to collect fresh, structured data at scale—without the headaches of managing infrastructure.
Key Features
🔍 Crawl at Scale
Affordably crawl tens of millions of pages per month. With horizontally-scaling architecture, you can grow your projects without worrying about performance bottlenecks.
🧠 Smart Data Extraction
Use LLMs or query selectors to extract JSON data that fits your custom schema. Whether you’re scraping text, images, or metadata, Crawlspace ensures your data is clean and usable.
🤝 Respectful Crawling
Follow robots.txt and rate-limit responses by default. Plus, leverage a platform-wide TTL cache to reduce redundant traffic and respect website owners.
🗄️ Flexible Storage
Store structured data in SQLite, unstructured data in an S3-compatible bucket, and semantic data in a vector database—all included with your crawler.
🚀 Serverless Deployment
Deploy web crawlers as easily as you deploy websites. No infrastructure to manage, no servers to maintain—just focus on building.
Use Cases
AI Training Data Collection
Gather fresh, structured data to train machine learning models. Use LLMs to extract and format data directly into your preferred schema.Market Research
Monitor competitor websites, track pricing changes, or scrape product details at scale—all while respecting rate limits and robots.txt.Content Aggregation
Build dynamic datasets for news aggregators, job boards, or research platforms. Store data in SQLite or vector databases for easy retrieval and analysis.
Why Choose Crawlspace?
Cost-Effective:Crawl a million pages for just $5.
Developer-Friendly:TypeScript-first, with support for JavaScript and npm packages.
Observable:Monitor traffic logs using OpenTelemetry for full transparency.
Always-Free Egress:Download your datasets without worrying about additional costs.
FAQ
Q: How does Crawlspace reduce redundant bot traffic?
A: Crawlspace uses a platform-wide TTL cache. When multiple crawlers request the same URL within a set time window, the response is pulled from the cache, reducing traffic to the origin server.
Q: Can I crawl social media websites?
A: No. Social media platforms like LinkedIn and X explicitly forbid crawling in their robots.txt files. For social media data, consider using data enrichment platforms.
Q: Can I use third-party AI models like GPT-4?
A: Yes! Place your API tokens in your crawler’s .envfile and use models from providers like OpenAI or Anthropic for scraping and embedding.
Q: Is Crawlspace compliant with website policies?
A: Absolutely. Crawlspace respects robots.txt and rate-limiting by default, ensuring your crawlers are polite and compliant.
Build Smarter, Crawl Better
Crawlspace is more than a web crawling platform—it’s a foundation for your next groundbreaking idea. With affordable pricing, developer-friendly tools, and a commitment to respectful crawling, it’s the ultimate solution for scaling your data collection efforts.
Ready to get started? Deploy your first crawler today and experience the future of web crawling.
More information on Crawlspace
Crawlspace was manually vetted by our editorial team and was first featured on 2025-01-22.
Crawlspace Alternatives
Crawlspace Alternatives-

Crawl4AI: Open-source web crawler purpose-built to turn any website into clean, LLM-ready data for your AI projects & RAG applications.
-

AnyCrawl: High-performance web crawler for AI. Get clean, LLM-ready structured data from dynamic websites for your AI models & analytics.
-

Crawly: AI-powered web data extraction API. Get targeted data, full scans, & screenshots. Simple to integrate. Free trial!
-

Extract web data effortlessly! Webcrawlerapi handles JavaScript, proxies, & scaling. Get structured data for AI, analysis, & more.
-

The ultimate tool for AI developers and data scientists, offering efficient web data extraction with dynamic content handling and markdown conversion.