
What is GPT-Crawler?
ウェブサイトから情報を手動で収集し、カスタムの GPT や AI アシスタントのトレーニングに利用するのは、時間と労力を要するプロセスです。適切なデータが、正しい構造で揃っていなければ、始めることさえできません。BuilderIO チームが開発したオープンソースツールである GPT Crawler は、このプロセスを完全に効率化します。指定したウェブページをクロールし、関連コンテンツを抽出し、OpenAI へのアップロードに対応した構造化されたナレッジファイル(output.json)を生成します。既存のウェブコンテンツを、カスタム AI プロジェクトに特化したナレッジベースへと効率的に変換できます。
主な機能
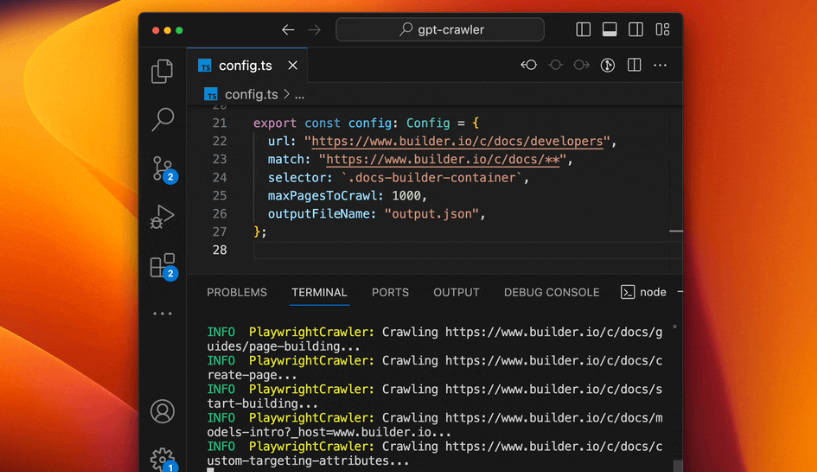
🌐 ターゲットを絞ったウェブサイトクロール: 開始 URL を指定し、照合パターン(
match)を定義して、クローラーの動作をガイドします。指定したリンク先ページを体系的にナビゲートします。✂️ 正確なコンテンツ抽出: CSS セレクター(
selector)を使用して、含めたいコンテンツ領域(メイン記事、ドキュメントセクションなど)を正確に特定し、ヘッダー、フッター、広告などのノイズを除外します。⚙️ 柔軟な構成: クロールの深さ(
maxPagesToCrawl)、除外するリソースタイプ(resourceExclusions)、最大出力ファイルサイズ(maxFileSize)、またはトークン数による制限(maxTokens)を、config.tsファイル内で直接調整できます。📄 構造化されたナレッジ出力: OpenAI のカスタム GPT または Assistant 作成ツールで簡単に取り込めるようにフォーマットされた、抽出されたテキストを含む
output.jsonファイルを自動的に生成します。🚀 複数の実行方法: GPT Crawler をローカルマシンから直接実行したり、隔離された環境のために Docker コンテナ内にデプロイしたり、API サーバー(Express JS)として実行してアプリケーションに統合したりできます。
📦 オープンソースとコミュニティ主導: GitHub でオープンソースライセンスの下で公開されており、コードの検査、改善への貢献、自由な利用が可能です。
ユースケース
製品サポートアシスタントの作成: GPT Crawler に製品のドキュメントサイト(例:
docs.yourproduct.com)を指定します。生成されたoutput.jsonを使用して、公式ドキュメントのみに基づいてユーザーの質問に即座に回答できるカスタム GPT を構築し、サポートチケットを削減し、ユーザーの自己解決を促進します。社内ナレッジボットの開発: 社内の Wiki やナレッジベース(Confluence や SharePoint サイトなど)をクロールします。従業員が会社のポリシー、プロジェクトの詳細、または標準的な運用手順に関する情報をワークフロー内で迅速に見つけられるように支援する AI アシスタントを作成します。
専門的なリサーチアグリゲーターの構築: 特定の業界ブログ、ニュースサイト、または分野に関連するリサーチポータルのコレクションをターゲットにします。GPT Crawler を使用して最新の記事と調査結果を収集し、カスタム GPT を構築して、ニッチ分野の開発に関するクエリ、要約、最新情報の入手を支援します。
結論
GPT Crawler は、ウェブコンテンツとカスタム AI の間のギャップを埋めるための、実践的で開発者にとって使いやすいソリューションを提供します。焦点を絞ったクロール機能、きめ細かい構成オプション、および柔軟なデプロイ方法の組み合わせにより、特定のオンライン情報に基づいた専門的な GPT または AI アシスタントを構築しようとするすべての人にとって価値のあるツールとなっています。オープンソースプロジェクトとして、透明性とコミュニティ主導の機能強化の可能性を提供し、カスタム AI 開発ワークフローにおける重要なステップを簡素化します。
More information on GPT-Crawler
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
GPT-Crawler was manually vetted by our editorial team and was first featured on 2025-03-30.
Related Searches
GPT-Crawler 代替ソフト
もっと見る 代替ソフト-
SimplescraperのScrape To AIを利用すれば、JSONやCSVファイルをOpenAIに簡単にアップロードできます。シームレスにデータにアクセスして活用することで、生産性を向上させることができます。
-

-

-

Website2GPTは、GPTトレーニングのためのクリーンなテキストにウェブサイトコンテンツを変換します。スマートな抽出、柔軟な出力、レート制限機能を搭載。AIモデルやナレッジベースに最適です。ウェブサイトのAIの可能性を解き放ちましょう!
-
