
What is GPT-Crawler?
要手動從網站彙整資訊,以訓練客製化的 GPT 或 AI 助理,可能既緩慢又費力。您需要正確的資料,而且結構也必須正確,才能開始。BuilderIO 團隊推出的開源工具 GPT Crawler,簡化了整個流程。它能讓您爬取指定的網頁、擷取相關內容,並產生結構化的知識檔案 (output.json),方便您上傳到 OpenAI。現在,您可以有效地將現有的網路內容轉換為重點明確的知識庫,用於您的客製化 AI 專案。
主要功能
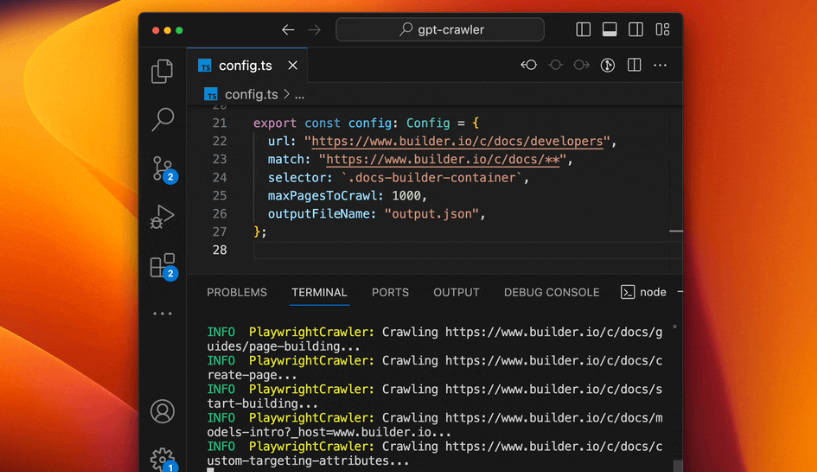
🌐 鎖定目標的網站爬取: 提供起始網址,並定義比對模式 (
match) 以引導爬取工具。它會系統性地瀏覽您關心的連結頁面。✂️ 精準的內容擷取: 使用 CSS 選擇器 (
selector) 來精確找出您想要包含的內容區域(例如主要文章、文件章節),並過濾掉標頭、頁尾和廣告等雜訊。⚙️ 彈性的設定: 直接在
config.ts檔案中調整爬取深度 (maxPagesToCrawl)、定義要排除的資源類型 (resourceExclusions)、設定最大輸出檔案大小 (maxFileSize),或依據 Token 數量限制 (maxTokens)。📄 結構化的知識輸出: 自動產生
output.json檔案,其中包含擷取的文字,其格式方便 OpenAI 的客製化 GPT 或助理建立工具輕鬆提取。🚀 多種執行方法: 直接從您的本機電腦執行 GPT Crawler、在 Docker 容器中部署以實現隔離環境,或將其整合到您的應用程式中,以 API 伺服器 (Express JS) 的形式執行。
📦 開源與社群驅動: 在 GitHub 上以開源授權提供,讓您可以檢查程式碼、貢獻改進內容,並免費使用。
使用案例
建立產品支援助理: 將 GPT Crawler 指向您產品的文件網站(例如
docs.yourproduct.com)。使用產生的output.json來建置客製化的 GPT,它可以僅根據您的官方文件立即回答使用者問題,從而減少支援工單並改善使用者自助服務。開發內部知識機器人: 爬取您公司的內部 Wiki 或知識庫(例如 Confluence 或 SharePoint 網站)。建立一個 AI 助理,協助員工直接在他們的工作流程中快速找到有關公司政策、專案細節或標準作業程序等資訊。
建置專業的研究彙整工具: 鎖定與您的領域相關的特定產業部落格、新聞網站或研究入口網站集合。使用 GPT Crawler 收集最新的文章和發現,然後建置一個客製化的 GPT,以協助您查詢、總結並隨時掌握該領域的發展。
結論
GPT Crawler 提供了一個實用且對開發人員友善的解決方案,可彌合網路內容與客製化 AI 之間的差距。它專注的爬取功能,結合細緻的設定選項和彈性的部署方法,使其成為任何希望建置基於特定線上資訊的專業 GPT 或 AI 助理的人的寶貴工具。作為一個開源專案,它提供了透明度以及社群驅動的增強潛力,簡化了客製化 AI 開發工作流程中的一個關鍵步驟。
More information on GPT-Crawler
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
GPT-Crawler was manually vetted by our editorial team and was first featured on 2025-03-30.
Related Searches
GPT-Crawler 替代方案
更多 替代方案-
使用 Simplescraper 的 Scrape to AI,輕鬆將 JSON 或 CSV 檔案上傳至 OpenAI。無縫存取和利用資料,提高生產力。
-

-

-

Website2GPT 將網站內容轉換成乾淨的文字,適用於 GPT 訓練。它具備智慧型擷取、彈性輸出及速率限制功能。非常適合 AI 模型及知識庫使用,釋放網站的 AI 潛力!
-
