
What is GPT-Crawler?
手动从网站搜集信息,用于训练定制的 GPT 或 AI 助手,是一个既缓慢又繁琐的过程。你需要正确的数据,并且以正确的结构呈现,才能开始。来自 BuilderIO 团队的开源工具 GPT Crawler,则完全简化了这一流程。它允许你爬取指定的网页,提取相关内容,并生成结构化的知识文件(output.json),以便上传到 OpenAI。现在,你可以高效地将现有的网络内容转化为针对你定制 AI 项目的重点知识库。
主要特性
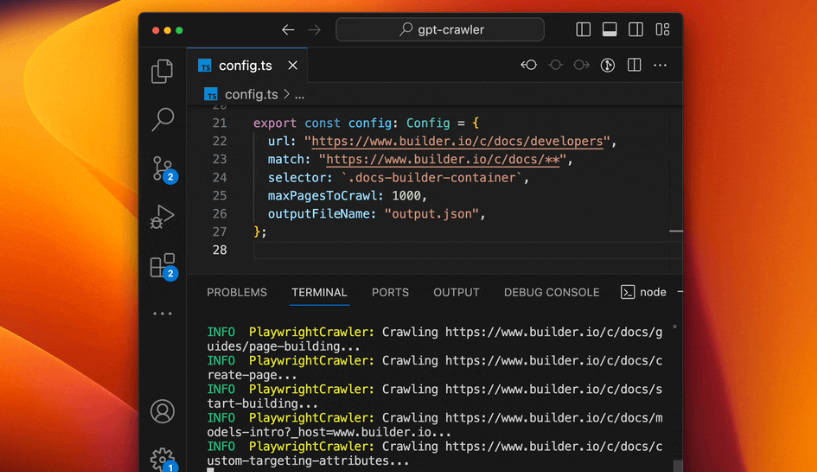
🌐 精准的网站爬取: 提供起始 URL,并定义匹配模式(
match)来引导爬虫。它会系统地浏览你关心的链接页面。✂️ 精确的内容提取: 使用 CSS 选择器(
selector)来精确定位你想要包含的内容区域(如主要文章、文档章节),过滤掉标题、页脚和广告等干扰信息。⚙️ 灵活的配置: 直接在
config.ts文件中定制爬取深度(maxPagesToCrawl),定义要排除的资源类型(resourceExclusions),设置最大输出文件大小(maxFileSize),或按 Token 数量进行限制(maxTokens)。📄 结构化的知识输出: 自动生成一个
output.json文件,其中包含提取的文本,并针对 OpenAI 的定制 GPT 或助手创建工具进行了格式化,方便直接使用。🚀 多种执行方法: 可以直接从本地机器运行 GPT Crawler,在 Docker 容器中部署以实现隔离环境,或者将其作为 API 服务器(Express JS)运行,集成到你的应用程序中。
📦 开源与社区驱动: 在 GitHub 上以开源许可证提供,允许你检查代码、贡献改进,并免费使用。
应用场景
创建产品支持助手: 将 GPT Crawler 指向你产品的文档站点(例如,
docs.yourproduct.com)。使用生成的output.json来构建一个定制 GPT,它可以根据 仅 你的官方文档立即回答用户的问题,从而减少支持请求并改善用户自助服务。开发内部知识库机器人: 爬取你公司的内部 Wiki 或知识库(如 Confluence 或 SharePoint 站点)。创建一个 AI 助手,帮助员工直接在其工作流程中快速找到有关公司政策、项目详细信息或标准操作程序的信息。
构建专业的研究聚合器: 锁定与你的领域相关的特定行业博客、新闻网站或研究门户。使用 GPT Crawler 收集最新的文章和发现,然后构建一个定制 GPT 来帮助你查询、总结并及时了解该领域的进展。
结论
GPT Crawler 提供了一个实用的、对开发者友好的解决方案,用于弥合网络内容和定制 AI 之间的差距。其专注的爬取能力、细粒度的配置选项和灵活的部署方法,使其成为任何希望构建基于特定在线信息的专业 GPT 或 AI 助手的宝贵工具。作为一个开源项目,它提供了透明度以及社区驱动增强的潜力,从而简化了定制 AI 开发工作流程中的一个关键步骤。
More information on GPT-Crawler
Launched
Pricing Model
Free
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
GPT-Crawler was manually vetted by our editorial team and was first featured on 2025-03-30.
Related Searches
GPT-Crawler 替代方案
更多 替代方案-
通过 Simplescraper 的 Scrape To AI,轻松将 JSON 或 CSV 文件上传至 OpenAI。无缝访问和利用数据以提高生产力。
-

-

-

Website2GPT 将网站内容转换为干净文本,用于 GPT 训练。智能提取,灵活输出,速率限制。非常适合 AI 模型和知识库。释放网站的 AI 潜能!
-
