
What is Spice?
Spiceは、Rustで構築されたオープンソースのSQLクエリおよびAIコンピューティングエンジンであり、データ駆動型AIアプリケーションの開発を簡素化するために設計されています。インテリジェントエージェント、検索拡張生成(RAG)ワークフロー、リアルタイム分析ダッシュボードの構築を問わず、SpiceはAIを高速で正確かつ関連性の高いデータに根付かせるためのツールを提供します。
Spiceを選ぶ理由
Spiceは、AIおよびデータアプリケーションを強化するための軽量で柔軟性があり、本番環境で使用できるエンジンを必要とする開発者のために構築されています。Spiceが際立っている点は次のとおりです。
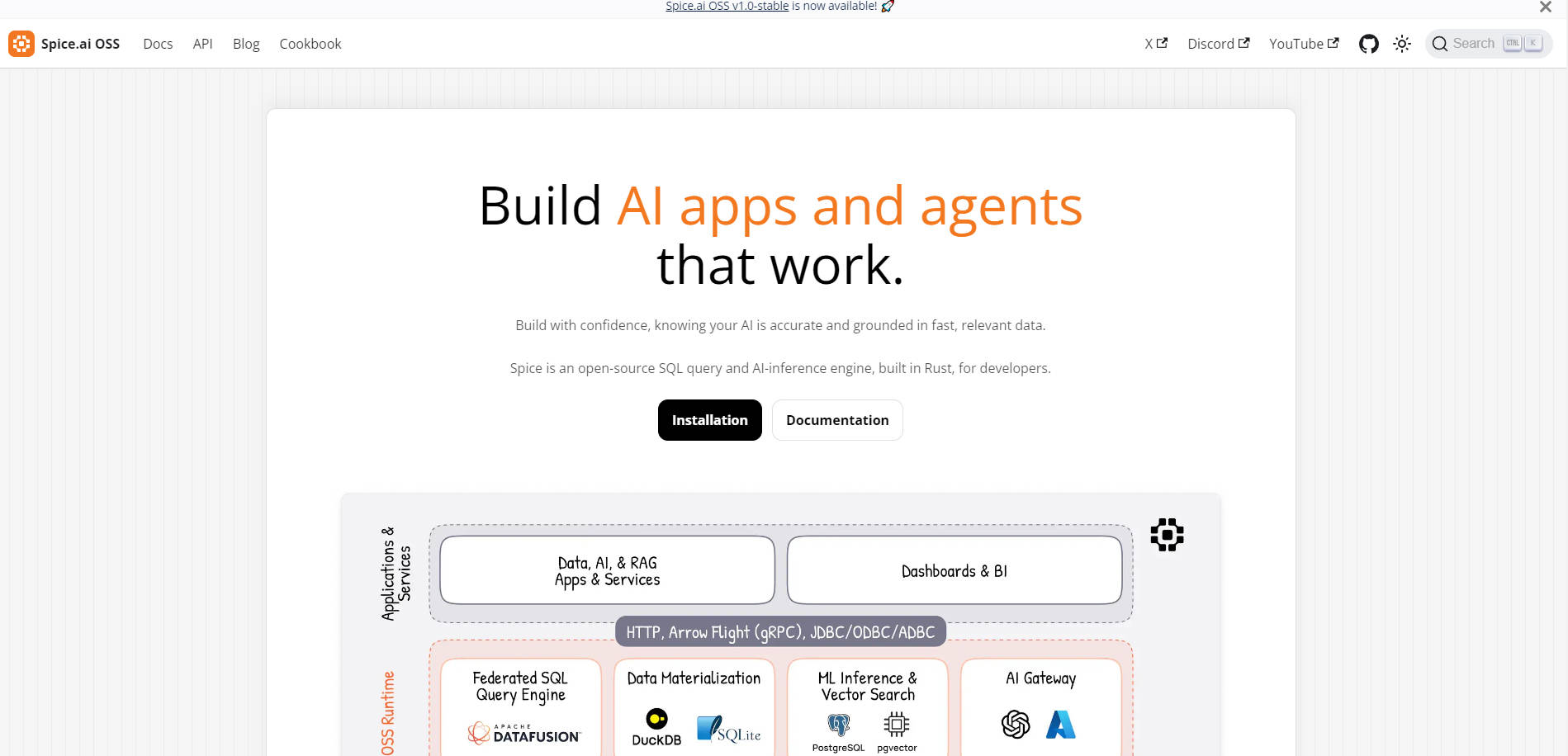
フェデレーテッドデータアクセス:統一されたSQL APIを使用して、データベース、データウェアハウス、データレイク全体で構造化データと非構造化データにクエリを実行します。
AIコンピューティングエンジン:ローカルまたはホストされた推論、検索、メモリ、および可観測性のために、OpenAI互換APIを使用します。
データアクセラレーション:DuckDB、SQLite、またはPostgreSQLにデータをマテリアライズしてキャッシュし、サブ秒のクエリパフォーマンスを実現します。
セルフホスト可能でオープンソース:インフラストラクチャを完全に制御しながら、スタンドアロンバイナリまたはDockerイメージとしてSpiceをデプロイします。
主な機能
? フェデレーテッドSQLクエリ
複数のソース(データベース、ウェアハウス、またはレイク)にまたがるデータを、単一のSQL APIでクエリします。複数のツールを切り替えたり、システム間の遅いクエリに悩まされる必要はもうありません。
? AIネイティブランタイム
SQLクエリとAI推論を1つのエンジンで組み合わせます。ローカルまたはホストされたモデル、LLMメモリ、および可観測性ツールを使用して、インテリジェントなアプリケーションを構築します。
⚡ データアクセラレーション
Arrow、DuckDB、またはSQLiteにデータセットをマテリアライズして、超高速クエリを実現します。リアルタイムダッシュボード、AIフィードバックループ、およびRAGワークフローに最適です。
? 柔軟なデプロイメント
Spiceをスタンドアロンインスタンス、Kubernetesサイドカー、または分散クラスタとして、エッジ、オンプレミス、またはクラウド環境全体で実行します。
ユースケース
エージェント型AIアプリケーション
リアルタイムデータに基づいた、ローカルまたはホストされたモデルを使用してAIエージェントを構築します。SpiceのLLMメモリと可観測性ツールを使用して、パフォーマンスを追跡し、精度を向上させます。検索拡張生成(RAG)
高性能検索とテキストツーSQL機能により、AIをデータに根付かせます。Spiceのベクター検索とセマンティックナレッジレイヤーにより、RAGワークフローをシームレスにします。データベースCDN
サブ秒のクエリパフォーマンスを実現するために、アプリケーションとデータセットを同じ場所に配置します。BIダッシュボードまたはリアルタイム分析の高速化に最適です。分散データメッシュ
高度なフェデレーションを使用して、データベース、ウェアハウス、およびレイク全体をクエリします。レガシー移行を簡素化し、最新のシステムとレガシーシステムを1つのエンドポイントで統合します。
よくある質問
1. Spiceはキャッシュですか?
厳密には違います。Spiceは、フィルタまたは間隔に基づいてデータをプリフェッチおよびマテリアライズし、アクティブなキャッシュまたはワーキングデータセットプリフェッチャとして機能します。
2. Spiceはフェデレーテッドクエリを処理できますか?
はい!Spiceは、高速で効率的なデータ取得のために、データベース、ウェアハウス、およびレイク全体で高度なクエリプッシュダウンをサポートしています。
3. SpiceはどのようなAI機能を提供しますか?
Spiceは、推論、埋め込み、およびメモリのためのOpenAI互換APIを提供します。ローカルモデルの提供もサポートし、OpenAIやAnthropicなどの一般的なプロバイダーと統合します。
Spiceは、高速で正確かつデータに基づいて動作するAIアプリとエージェントを構築するために必要なエンジンです。今すぐ試して、その違いを体感してください。
More information on Spice
Launched
2021-05
Pricing Model
Free
Starting Price
Global Rank
3492103
Follow
Month Visit
5.8K
Tech used
Cloudflare Analytics,Google Analytics,Google Tag Manager,Cloudflare CDN,Atom,Gzip,HTTP/3,OpenGraph,OpenSearch,RSS,Algolia
Top 5 Countries
46.74%
29.37%
19.77%
4.12%
United States
Vietnam
India
Poland
Traffic Sources
7.88%
1.01%
0.1%
23.02%
33.98%
33.61%
social
paidReferrals
mail
referrals
search
direct
Source: Similarweb (Sep 25, 2025)
Spice was manually vetted by our editorial team and was first featured on 2025-01-26.
Related Searches
Spice 代替ソフト
もっと見る 代替ソフト-

-
-

-
-

Fireplexity: 独自のオープンソースAI回答エンジンを構築・ホスティング。お手元のデータから、正確で引用元付きの回答をフルコントロールで取得。