
Click outside to close
What is Spice?
Spice是一款基于Rust构建的开源SQL查询和AI计算引擎,旨在简化数据驱动型AI应用的开发。无论您是构建智能代理、检索增强生成 (RAG) 工作流,还是实时分析仪表板,Spice都能提供工具,让您的AI能够基于快速、准确和相关的的数据。
为什么选择Spice?
Spice专为需要轻量级、灵活且可用于生产环境的引擎来驱动其AI和数据应用程序的开发者而构建。以下是Spice的突出之处:
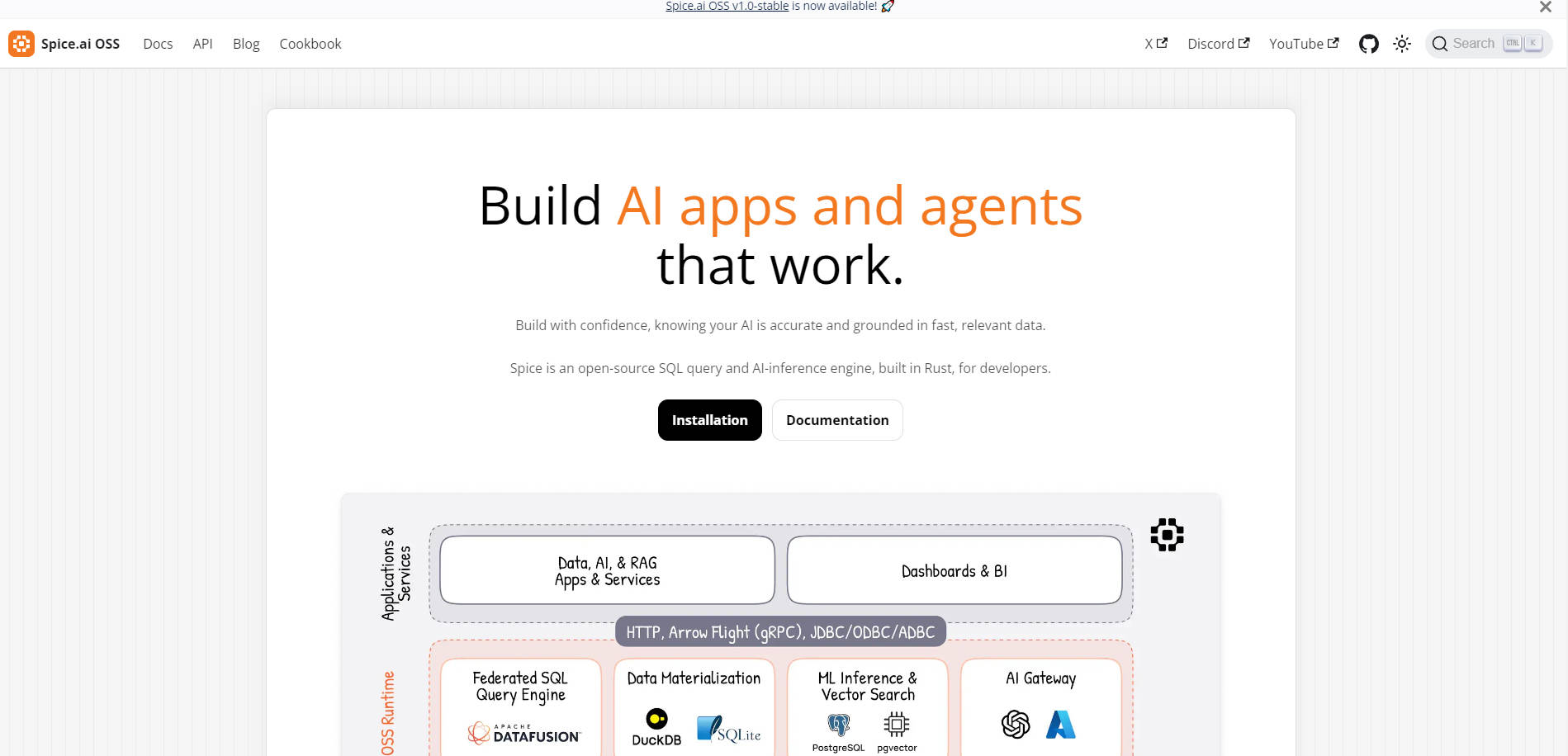
联合数据访问:使用统一的SQL API查询跨数据库、数据仓库和数据湖的结构化和非结构化数据。
AI计算引擎:使用与OpenAI兼容的API进行本地或托管推理、搜索、内存和可观测性。
数据加速:在DuckDB、SQLite或PostgreSQL中物化和缓存数据,以实现亚秒级的查询性能。
自托管和开源:将Spice部署为独立二进制文件或Docker镜像,完全控制您的基础设施。
关键特性
? 联合SQL查询
使用单个SQL API查询跨多个来源(数据库、仓库或数据湖)的数据。无需再同时使用多种工具或处理缓慢的跨系统查询。
? 原生AI运行时
在一个引擎中结合SQL查询和AI推理。使用本地或托管模型、LLM内存和可观测性工具来构建智能应用程序。
⚡ 数据加速
在Arrow、DuckDB或SQLite中物化数据集,以实现闪电般的快速查询。非常适合实时仪表板、AI反馈循环和RAG工作流。
? 部署灵活性
将Spice作为独立实例、Kubernetes sidecar或分布式集群运行——跨边缘、本地或云环境。
使用案例
智能代理应用
构建基于实时数据的本地或托管模型的AI代理。使用Spice的LLM内存和可观测性工具来跟踪性能并提高准确性。检索增强生成 (RAG)
通过高性能搜索和文本转SQL功能确保您的AI基于数据。Spice的向量搜索和语义知识层使RAG工作流无缝衔接。数据库CDN
将数据集与您的应用程序共同部署,以实现亚秒级的查询性能。非常适合加速BI仪表板或实时分析。分布式数据网格
使用高级联合查询跨数据库、仓库和数据湖。简化遗留迁移,并在单个端点下统一现代和遗留系统。
常见问题
1. Spice是缓存吗?
不完全是。Spice根据过滤器或时间间隔预取和物化数据,充当主动缓存或工作数据集预取器。
2. Spice可以处理联合查询吗?
是的!Spice支持跨数据库、仓库和数据湖的高级查询下推,以便快速有效地检索数据。
3. Spice提供哪些AI功能?
Spice提供与OpenAI兼容的API,用于推理、嵌入和内存。它还支持本地模型服务,并与OpenAI和Anthropic等流行提供商集成。
Spice是您构建高效、准确且基于数据的AI应用和代理所需的引擎。立即试用,亲身体验其差异。
More information on Spice
Top 5 Countries
46.74%
29.37%
19.77%
4.12%
United States (46.74%)
Vietnam (29.37%)
India (19.77%)
Poland (4.12%)
Traffic Sources
7.88%
23.02%
33.98%
33.61%
social (7.88%)
paidReferrals (1.01%)
mail (0.1%)
referrals (23.02%)
search (33.98%)
direct (33.61%)
Source: Similarweb (Sep 25, 2025)
Spice was manually vetted by our editorial team and was first featured on 2025-01-26.
Spice 替代
Spice 替代-

-
-

SQLite AI:AI原生、专为边缘设备打造的分布式数据库。内置大语言模型与向量搜索功能,实现数据无缝同步,并支持在全球范围内扩展您的智能应用。
-
-
