
What is Stax?
Stax is an AI evaluation platform designed to help developers and product teams quickly and confidently ship their Large Language Model (LLM) powered applications. It solves the critical challenge of accurately assessing AI performance by letting you test models and prompts against your unique criteria, ensuring your applications truly meet user needs.
Key Features
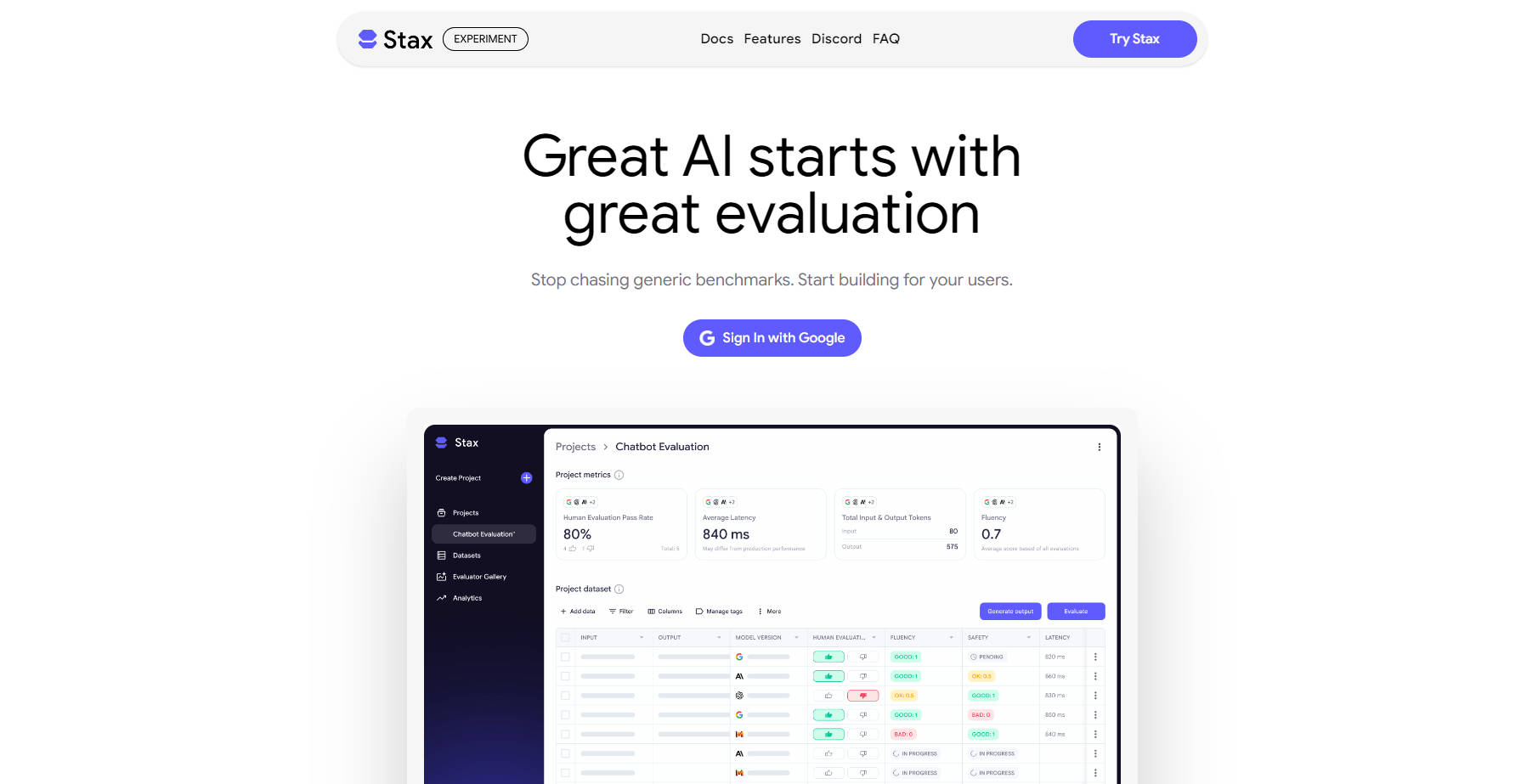
📊 Manage & Build Test Datasets: Easily import your existing production datasets or leverage Stax to construct new ones by prompting any major LLM. This ensures your evaluations are always relevant to your specific use cases.
⚙️ Leverage Pre-Built & Custom Evaluators: Go beyond generic benchmarks. Use a suite of default evaluators for standard metrics like instruction following and verbosity, or create custom ones to test for nuanced qualities such as brand voice or specific business logic.
📈 Make Data-Driven Decisions: Gain actionable data on quality, latency, and token count. Stax provides the insights you need to confidently identify the most effective AI model, prompt, or iteration for your application, moving from "vibe checks" to verifiable results.
🚀 Evaluate Fast, Ship Faster: Replace time-consuming, manual, one-off tests with powerful, repeatable evaluations. This enables rapid innovation and confident deployment, allowing you to iterate and release with speed.
Use Cases
Optimizing Chatbot Responses: A product team can use Stax to test various LLM models and prompts for a customer support chatbot. They can create custom evaluators to ensure responses are on-brand, accurate, and helpful, leading to improved customer satisfaction.
Refining Content Generation: A marketing team developing an AI-powered content creation tool can evaluate different LLM outputs against specific criteria like tone, style, and factual accuracy. Stax helps them quickly identify the best model and prompt combinations that consistently produce high-quality, on-brand content.
Benchmarking LLM Performance for a New Feature: Before launching a new feature powered by an LLM, developers can use Stax to compare multiple models and prompt engineering approaches. They can analyze performance across key metrics like latency and output quality, ensuring the feature performs reliably and efficiently in production.
Why Choose Stax?
Stax stands apart by shifting the focus from generic leaderboards to your specific needs. While general benchmarks offer a broad overview, Stax empowers you to truly understand how an LLM or prompt performs for your unique use cases.
Tailored Evaluation: Unlike platforms focused on broad metrics, Stax allows you to define and measure what genuinely matters to your product and your users, not just standard benchmarks. This means your evaluations directly inform your product's success.
Actionable Insights: Stax delivers hard data on critical performance metrics like quality, latency, and token count, enabling you to make informed decisions. You gain a clear understanding of what’s working, allowing you to build and ship breakthrough products with confidence.
End-to-End Workflow: From initial experimentation and rapid comparison of models, prompts, and orchestrations to scaled evaluation with managed datasets and custom evaluators, Stax provides a complete, repeatable workflow. You can visually track aggregated AI performance, monitor improvements, and confidently prepare for launch.
Conclusion
Stax provides the complete toolkit for AI evaluation, giving you the clarity, speed, and confidence needed to develop and deploy your LLM-powered applications effectively. Stop chasing generic benchmarks and start building for your users with data-driven insights.
More information on Stax
Launched
2008-11
Pricing Model
Starting Price
Global Rank
Follow
Month Visit
<5k
Tech used
Stax was manually vetted by our editorial team and was first featured on 2025-09-06.
Related Searches
Stax Alternatives
Load more Alternatives-

Braintrust: The end-to-end platform to develop, test & monitor reliable AI applications. Get predictable, high-quality LLM results.
-
-

-

Deepchecks: The end-to-end platform for LLM evaluation. Systematically test, compare, & monitor your AI apps from dev to production. Reduce hallucinations & ship faster.
-

Companies of all sizes use Confident AI justify why their LLM deserves to be in production.